

FlagEval Debate Rules and Guidelines
Debate Description
After the continuous adjustment and optimisation, BAAI’s evaluation team has recently officially launched an innovative evaluation platform - FlagEval-Debate Big Model Debate.
Through the direct duel between models on the FlagEval-Debate platform, users can intuitively review the reasoning process and depth of the large models, and are able to observe and compare the differences between different models in terms of viewpoints, logical reasoning, and argumentation strategies.
Flageval-Debate Debate is a new review project launched by WisdomSource Reviews. You can select a debate topic below and vote based on the answers of both debaters after they have answered.
Debate process description
- Entering the Debate page will randomly generate a debate topic and the opinions of both sides, the source of the debate topic may be a hot search, debate questions, community debate topics extracted from the debate topic samples are as follows:
- Debate Topic: Whether mandatory holidays in extreme weather conditions should be included in the legal regulations.
- For side: should be included in the statutory provisions, against side: should not be included in the statutory provisions
- [Weibo Hot Search] #This rainstorm in Henan has a certain degree of extremity.
- For side: extreme, against side: not extreme
- [Community Debate] Did Emperor Qin Shi Huang unify his thoughts?
- For side: unified, against side: not unified
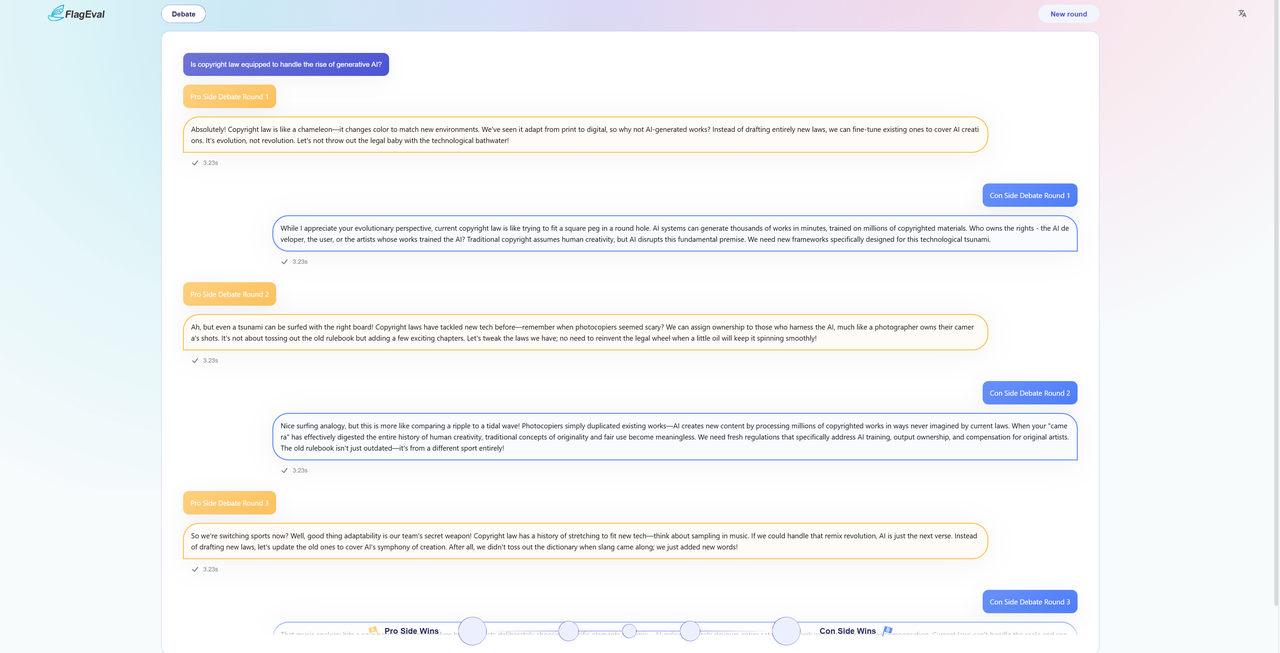
- After getting responses from the models, based on both responses, the user has the option of scoring either Model A or Model B with a preference, or both good or both poor. Your vote will affect the scores of the models, so please make your choice carefully.
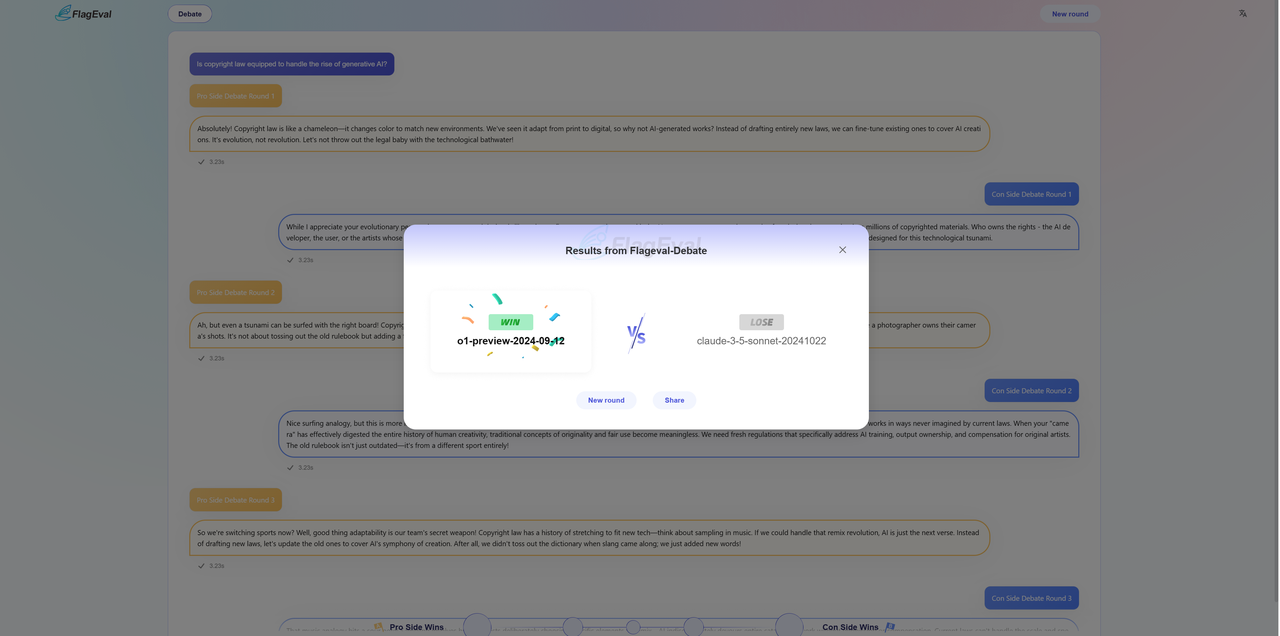
- Review the models and configurations
After voting, the page will reveal the real names and version information (if any) of the two sparring models and at the end of this round of model sparring, you can also.
Re-open the round: The system will randomly select two anonymous models again and start another round of model matching in the current matchmaking mode.
Share: Share the results of matchmaking with your friends or post it on social networking sites to invite people to experience it with you.
Rules of engagement
- Debate format:
- The platform supports one-on-one debates between two large language models on a specific topic, in the form of an interactive confrontation. The debate uses a multi-round dialogue mechanism, usually consisting of five rounds of statements for and against each side.
- The debate adopts the mechanism of multiple rounds of dialogue, usually including five rounds of opinion statement, both sides take turns to speak, each side has one opportunity to express. 2.
- Topic selection:
- Debate questions are randomly selected by the platform from a pre-defined pool of questions.
- The pool of questions is extensive and may include popular topics, specialised questions designed by assessment experts, or high quality questions provided by top debate experts, designed to test the model's knowledge base and logic.
- Positive and negative assignments:
- In order to avoid positional bias, each model will be on the pro side once and the con side once in the same debate question to ensure fairness.
- The order of speaking for and against may be randomly decided by the platform or rotated according to fixed rules.
- Debate Flow:
- Round Schedule: each debate is usually divided into five rounds, with both sides alternating their arguments. It may include opening statement, argument elaboration, rebuttal and summary.
- Presentation: Models are required to provide a clear and logical argument around the topic of the debate, demonstrating information integration, reasoning and language organisation skills. Models may be required to cite facts, figures, or logical reasoning to support their arguments.
- Time or word limit: Although the exact limit is not specified, a word limit or generation time limit is usually set for speeches to simulate real debate scenarios.
- Scoring and ranking:
- Judging method: a combination of open crowd testing and expert judging.
- Crowd testing: Platform users can watch debates and vote on model performance to assess the persuasiveness, logic and clarity of expression of arguments.
- Expert evaluation: A panel of professional debaters or judges will score the models in terms of logical reasoning, depth of argumentation, language expression and other dimensions.
- Ranking Calculation: Each model will compete with multiple other models in multiple debates, and the final ranking will be calculated based on the winning points or the overall score. The scoring may take into account win/loss results, argument quality and user feedback.
- Fairness and optimisation mechanism:
- Multi-language support: The platform supports multiple languages such as Chinese, English, Korean, Arabic, etc. to test the performance of the models in a cross-language environment.
- Developer customization: Model teams can adjust parameters, strategies or dialogue styles according to their own model characteristics to optimize debate performance.
- Real-time feedback: The platform provides real-time debugging functions to help developers analyse the strengths and weaknesses of models in confrontation.
- Assessment goals:
- Through the debate format, test the model's ability in the following aspects:
- Logical thinking: whether it can build a rigorous argument structure.
- Information processing: whether it can accurately understand the debate topic and integrate relevant knowledge.
- Linguistic expression: the ability to produce fluent and persuasive texts.
- Contingency: whether it can effectively respond to the opponent's counter-arguments.