

FlagEval Arena Combat Mechanics Design - Rules
Model Combat Description
FlagEvalArena is a model evaluation service open to users by BeijingAcademy of Artificial Intelligence (hereinafter referred to as "BAAI")for scientific research purposes. Users are requested to uploadrelevant data or content under the premise of complying with legalcompliance.
We will collect and use the data content uploaded by users, thereforeplease avoid uploading any private information or sensitive data.Interested users are welcome to join this evaluation at any time.
Combat Mode
The Large Model Arena only supports [Anonymous Combat] mode. This large model combat supports various combat modals, including LLM, VLLM, text-to-image and text-to-video.
Before model combats, users can choose diferent modals by clicking on the corresponding tab for model combats freely. To ensure the fairnessof model combats, different modal models will not combat against each other (such as multimodal large models will not combat against text-to-image large models). Text-to-image and text-to-video do not support multi-round dialogue.
The BAAI FlagEval evaluation team (hereinafter referred to as "the team") aims to ensure that the subsequent combat results list reaches the goal of being scientific, authoritative, fair, and open. Therefore,in this model combat, the evaluation experts of the team provide users with preset prompt input withhidden tags based on the division of model evaluation capabities. Under the modals of LLM, VLLM and text-to-image, users can also choose to enter their own prompts in the dialog box. However, this feature is not supported by text-to-video.
The Arena interface not only provides users with different battle modals to select but also offers two specific battle modes: "Deep Thinking" and "Multi-Model Battle." Users can switch to the desired mode by clicking the corresponding button on the interface. Alternatively, users can choose not to select any mode and engage in a general battle. In "Deep Thinking" mode, all participating models are inference models. In "Multi-Model Battle" mode, users can specify the number of models to participate, with the selectable range being 3 to 10.
After you confirm the modal of the combat model, if you choose to engage in the general battle mode, then entering a prompt, the system will randomly select two anonymous models for a combat. During the combat, the participating moels will answer your question atthe same time. After one or more rounds of dialogue, you can vote for the model that you think performs better based on the answers to the same input question of the large models. After voting, you can view the real names of the two anonymous large models (if there are versions, then the version number will also be displayed).
Similarly, in the Deep Thinking mode, after entering a prompt, the system will randomly select two anonymous inference models for a combat. During the combat, the participating moels will answer your question atthe same time. After one or more rounds of dialogue, you can vote for the model that you think performs better based on the answers to the same input question of the large models. After voting, you can view the real names of the two anonymous large models (if there are versions, then the version number will also be displayed).
In the Multi-Model Battle mode, the system will randomly selects models based on the number chosen by the user. The participating models will simultaneously answer your questions. After one or more rounds of dialogue, you can give each model a score from 1 to 5 based on their answer to the same input question. After scoring, you can view the real names of the anonymous large models (if there are versions, then the version number will also be displayed).
About Test Models: In this project, there are some models that do not wish to disclose their names, including but not limited to unreleased models, internal testing models, experimental models, and validation models. When a model from this pool is selected, they will be referred to as "test models."
For the scenario of two models competing against each other, FlagEvalArena has introduced a graded victory-defeat evaluation for the first time. This method refines the quality differences between model-generated content into five levels:
1. A is much better than B
2. A is better than B
3. A and B are tied/ Both are bad
4. B is better than A
5. B is much better than A
Compared to traditional Arena evaluations (which only categorize results into three levels: "A is superior," "B is superior," or "both are similar"), this approach provides richer granularity to capture subtle differences in model outputs. It aims to more precisely reveal performance disparities between models, thereby uncovering deeper and more comprehensive insights.
| Combat Mode | Explanation |
|---|---|
| Anonymous Model Combat | The system randomly selects two or more models for combat, and especially for the Multi-Model Battle mode, a specified number of models will be randomly selected. The model answers are generated by calling the commercialized API provided by the model side. The model answers are not restricted or arranged by the team, and are used to evaluate the text generation/VLLM/text-to-image/text-to-video capabilities of the model itself. Text-to-image may be limited by QPS calls, and there may be issues such as generation failures or extended generation time. If you encounter such problems, you can try regeneration, or contact the BAAI evaluation team: flageval@baai.ac.cn. |
Combat Workflow and Result
The general battle mode
You can refer to the following workflow to conduct model combats:
- Enter FlagEvalArena and start anonymous combats
- Choose one of the four modals by clicking on the corresponding tab for model combats freely.
- You can directly enter your question on the dialogue page or select one preset prompt.
- After you enter the text, the left and right anonymous models will answer at the same time. In combats of VLLM models and language models, you can have multiple rounds of dialogue to let the model explain further
- Based on the model's response, vote for the answer that is more satisfactory.
- To ensure the validity and fairness of the vote, you need to receive at least one complete response from any model before voting.
- You can give a preference to model A or model B, or select tie or both are bad. Your vote will affect the model's score, so please make your selection carefully.
- View model and configuration After voting, the page will reveal the real names and version information (if any) of the two models. After voting, the current round of model combat ends. You can also:
- Again: the system will randomly select two models again and conduct another round of model combat in the current combat mode.
- Share: share the combat results with your friends or post them on social media to invite everyone to experience together.
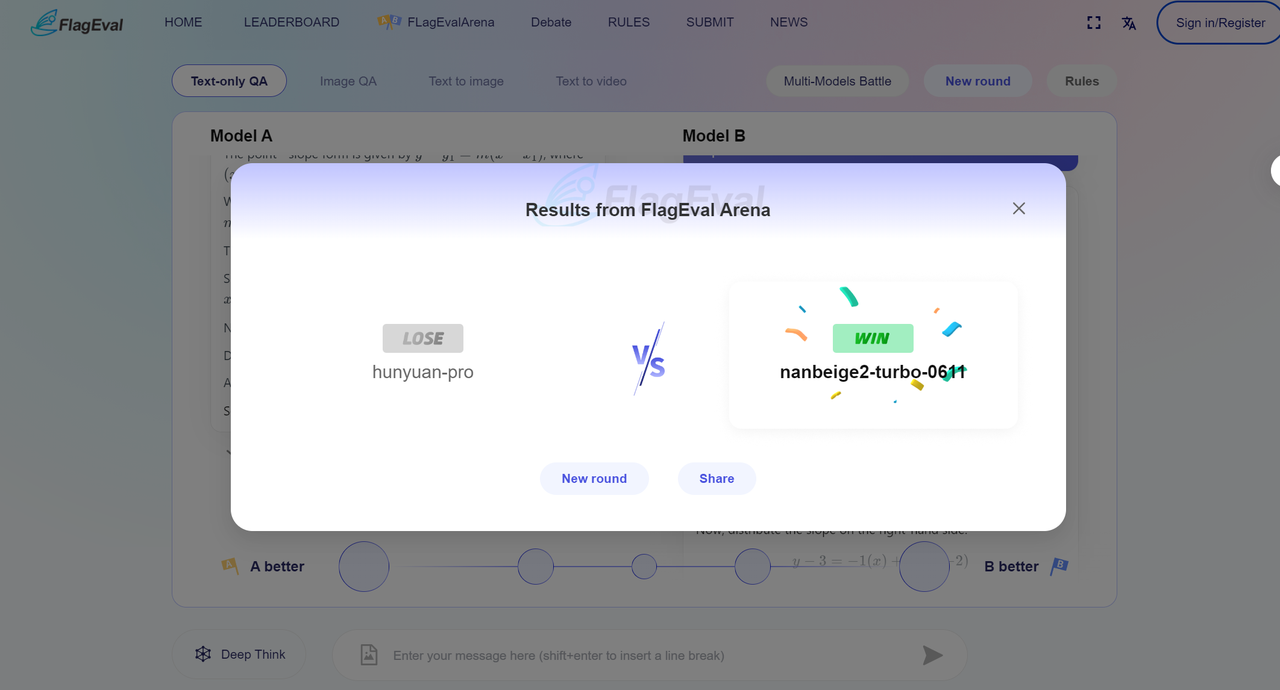
Combat Result
After voting, the page will display the winner and loser of the current round of combat, and reveal the real names of the models, as follows:
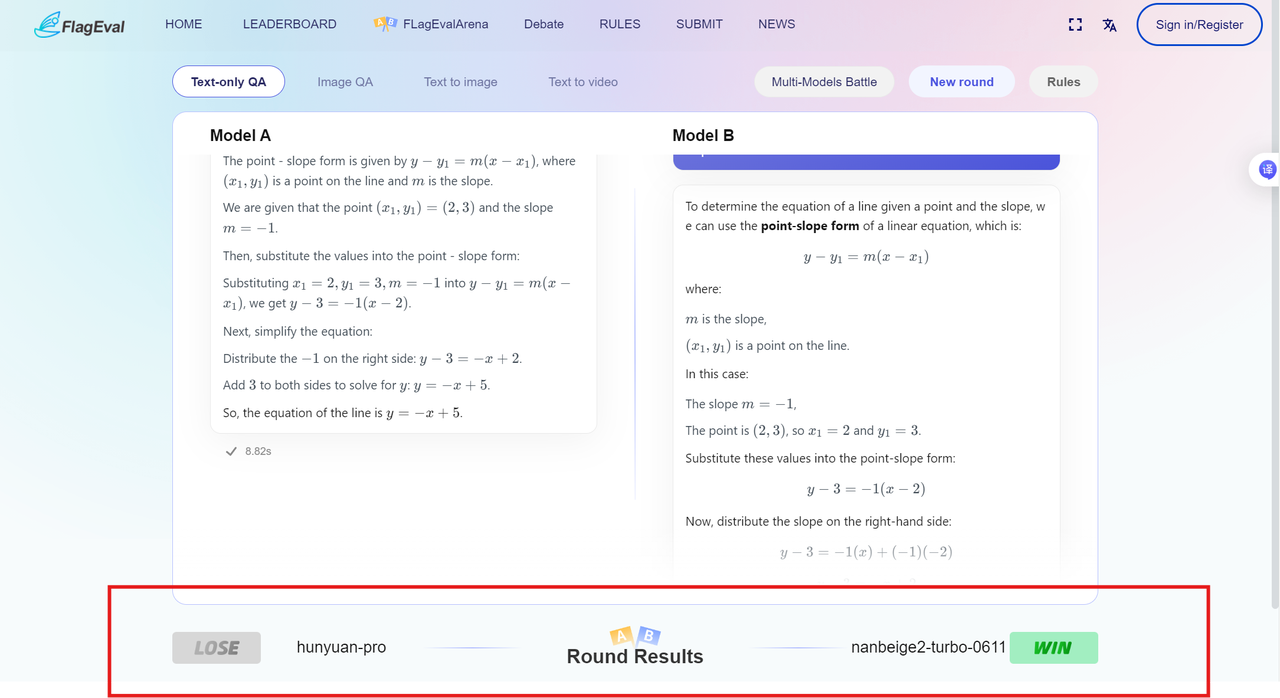
The Deep Thinking mode
When selecting the modals of LLM and VLLM, users will see a Deep Thinking option available in the lower-left corner of the page. Clicking on it will enter the Deep Thinking mode.
The battle models here are reasoning models. Compared to direct-generation models, reasoning models have slower response times, and users may need to patiently wait for the reasoning process to complete and return results. Additionally, Multi-Models battles are not supported in Deep Thinking mode.
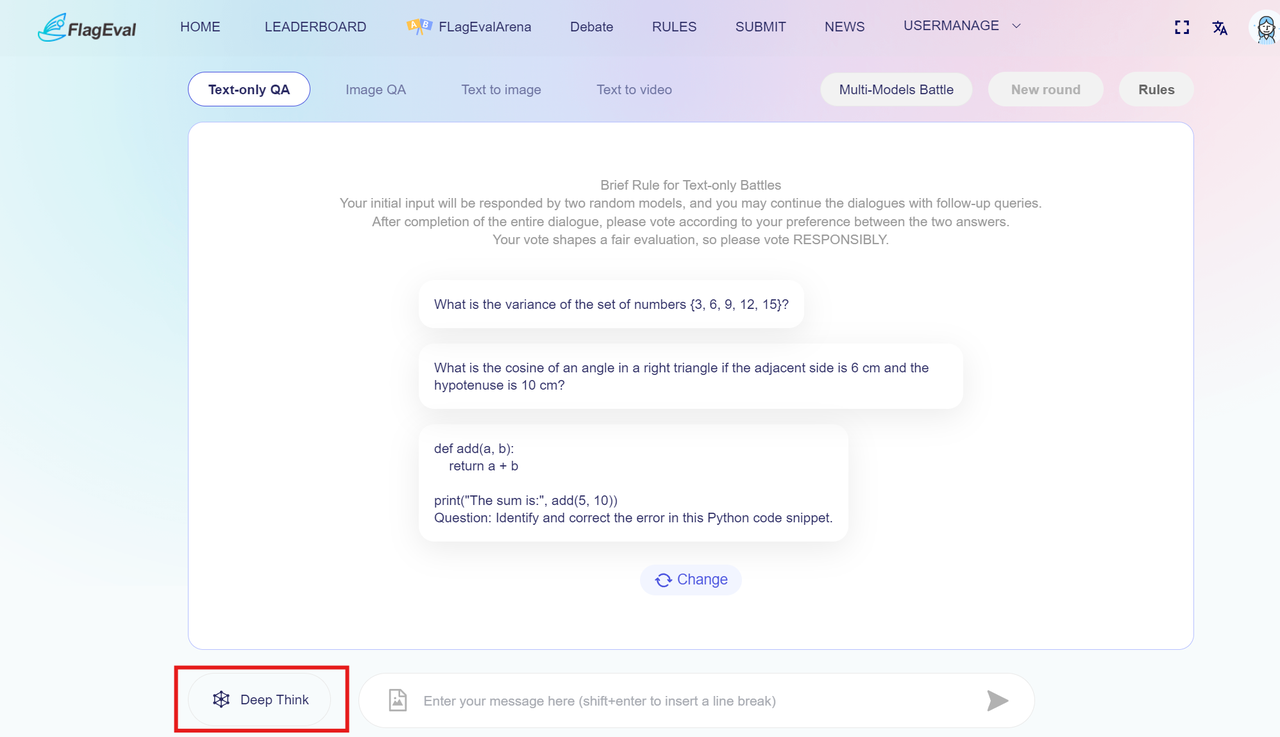
After entering Deep Thinking mode, You can refer to the following workflow to conduct model combats:
- You can directly enter your question on the dialogue page or select one preset prompt.
- After you enter the text, the left and right anonymous models will engage in deep thinking at the same time. They will generate responses after completing their reasoning and display their processing time on the page. Besides, you can have multiple rounds of dialogue to let the model explain further
- Based on the model's response, vote for the answer that is more satisfactory.
- To ensure the validity and fairness of the vote, you need to receive at least one complete response from any model before voting.
- You can give a preference to model A or model B, or select tie or both are bad. Your vote will affect the model's score, so please make your selection carefully.
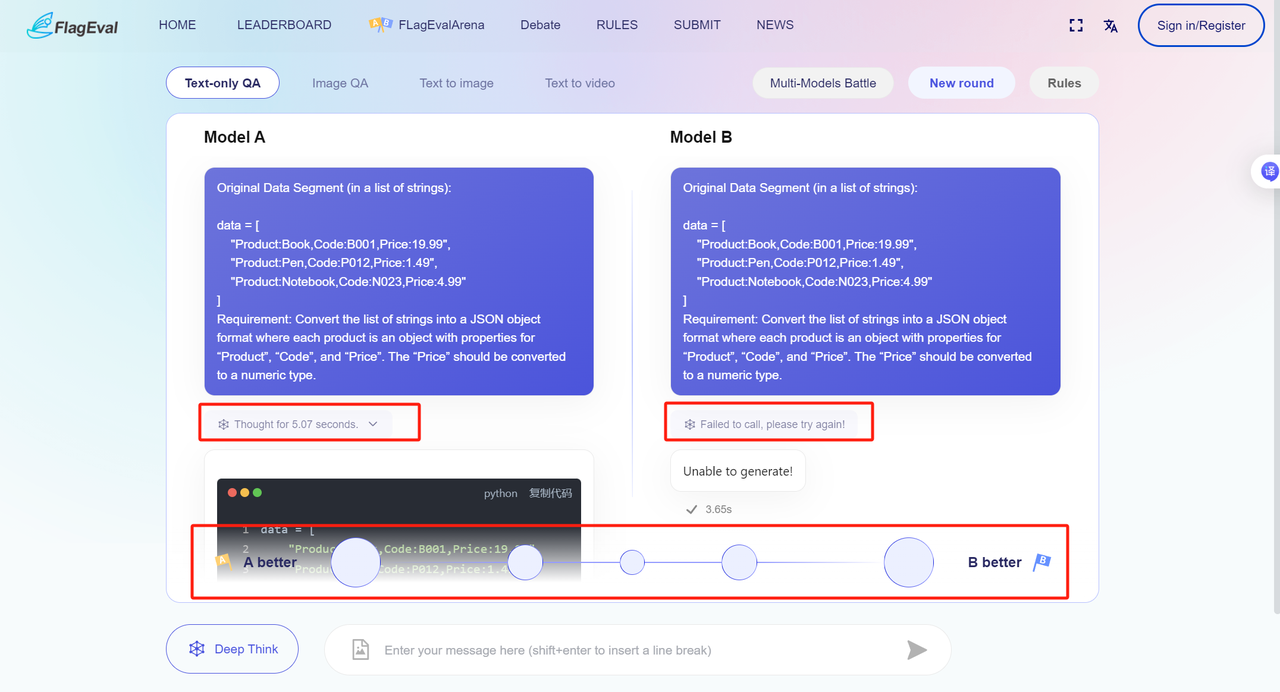
- View model and configuration After voting, the page will reveal the real names and version information (if any) of the two models. After voting, the current round of model combat ends. You can also:
- Again: the system will randomly select two models again and conduct another round of model combat in the current combat mode.
- Share: share the combat results with your friends or post them on social media to invite everyone to experience together.
- View Chain of Thought: Review the reasoning model's thought process (if available) on the results page.
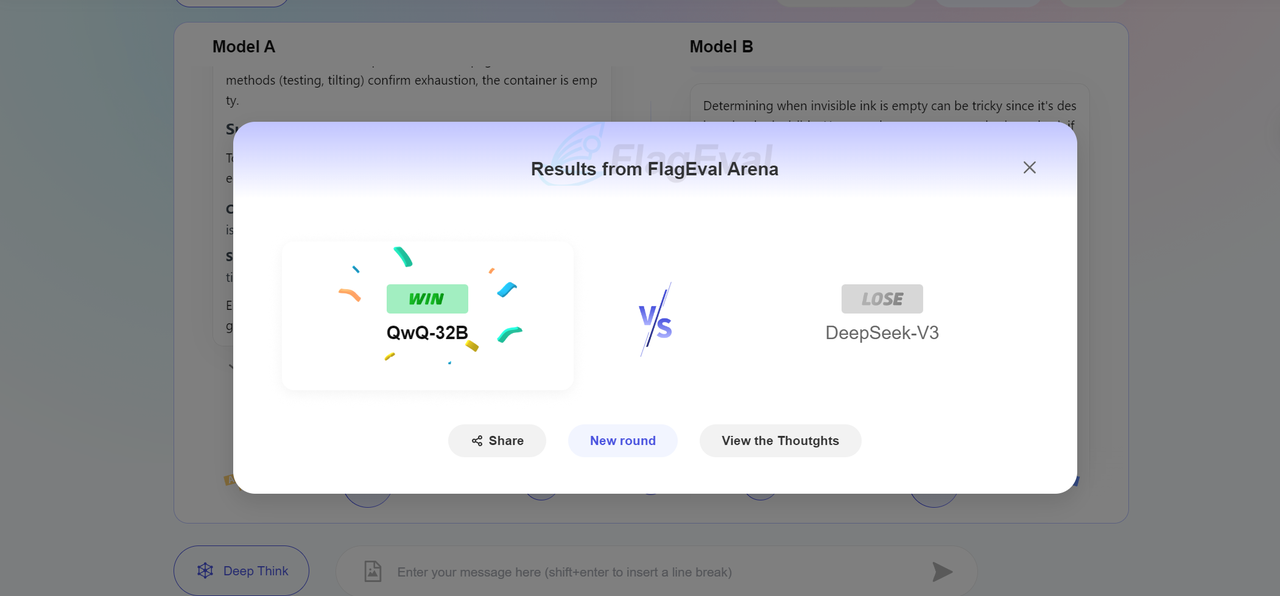
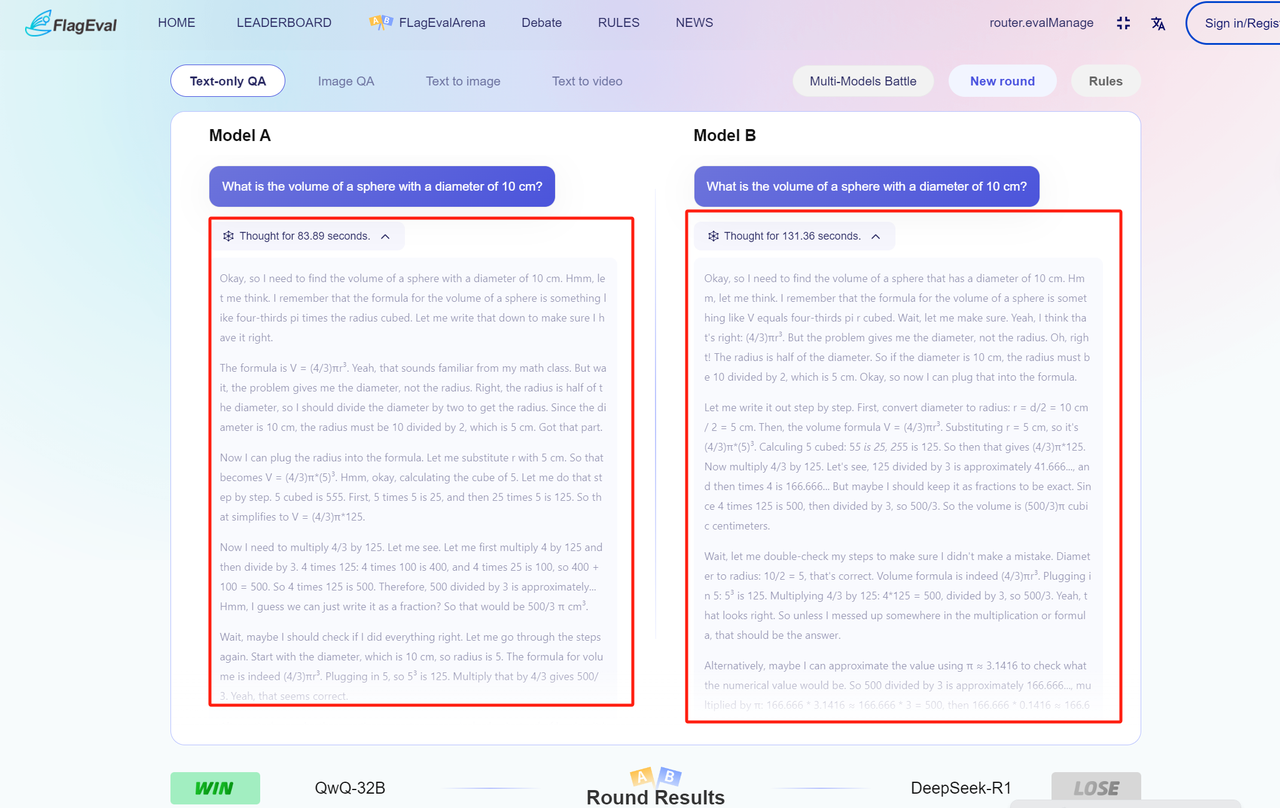
Combat Result After voting, the page will display the winner and loser of the current round of combat, and reveal the real names of the models, as follows:
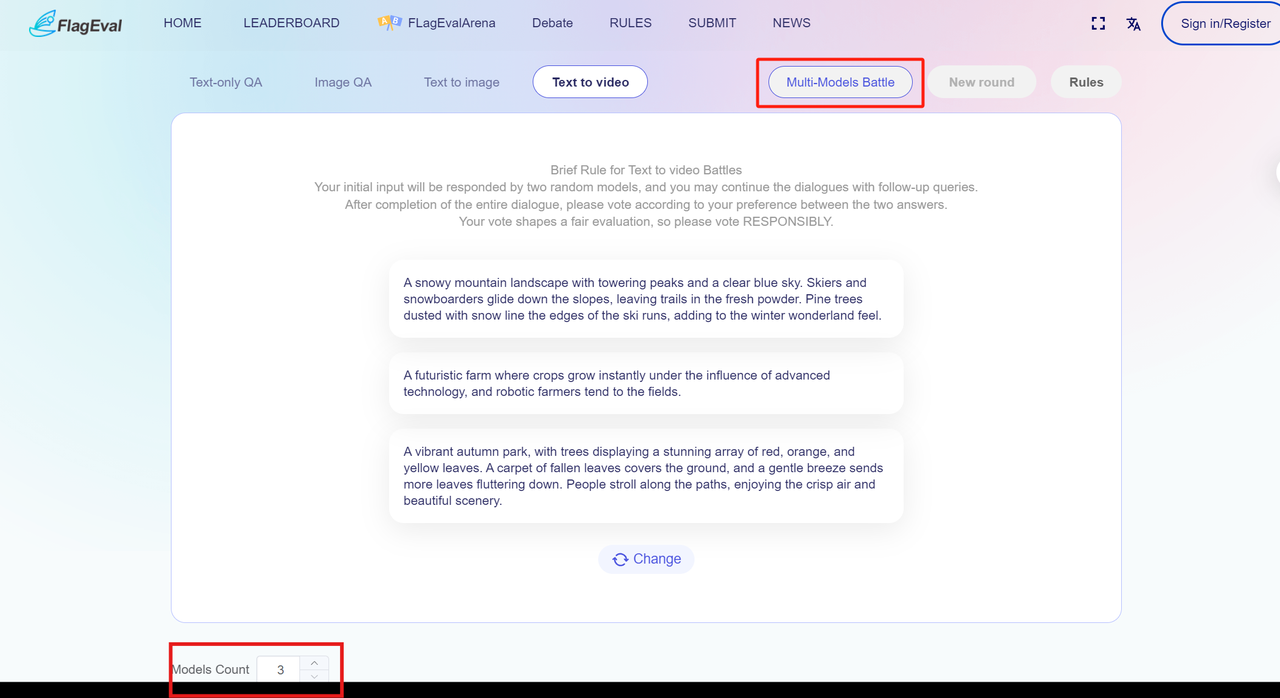
The Multi-Models Battle mode
Click the "Multi-Model Battle" button in the upper-right corner of the page to enter the multi-model battle mode. Here, users can freely select one of the four available modals. In the lower-left corner of the interface, choose the number of battle models (selectable range: 3 to 10; the exact quantity is user-defined). After confirming, input your prompt or choose a preset prompt in the bottom dialog box to initiate the battle.
After entering Multi-Model Battle mode, You can refer to the following workflow to conduct model combats:
- Choose one of the four modals by clicking on the corresponding tab for model combats freely.
- You can choose the number of models for the battle, selecting between 3 and 10 models, and multiple models will answer simultaneously. In combats of VLLM models and language models, you can have multiple rounds of dialogue to let the model explain further
- You can directly enter your question on the dialogue page or select one preset prompt.
- Based on the model's response, you can give each model a score from 1 to 5 :
- To ensure the validity and fairness of the score, you need to receive at least one complete response from any model before scoring.
- You can only have multiple rounds of dialogue if none of the models have been scored yet. Once any model enters the scoring phase, multiple rounds of dialogue are no longer supported.
- Your scoring will affect the model's evaluation results, so please make your scoring carefully.
- View model and configuration
After scoring, you can view the real names of the anonymous large models (if there are versions, then the version number will also be displayed).
After completing the scoring for each anonymous model, the scoring area displays the model name and score (not shown if unscored). Results from multi-model battles are temporarily unavailable for sharing. You can:
- Again: the system will randomly select the corresponding number of anonymous models again and conduct another round of model combat in the current combat mode.
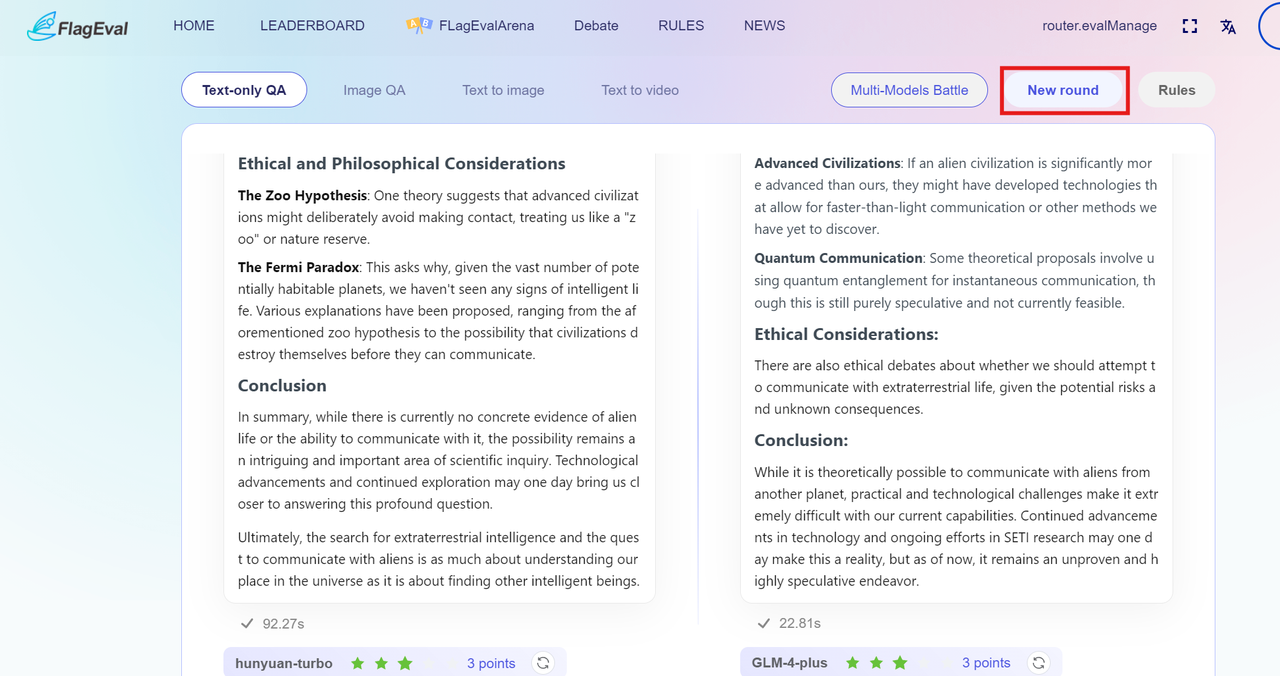
In multi-model battle mode, a scoring system is used, so there are no win/loss results displayed.
Rule of Combat
To ensure that the subjective evaluation covers the capability range of models as much as possible, you can use multiple rounds of dialogue to conduct multiple rounds of communication and questioning with models. This evaluation does not restrict evaluation questions, in order to maximize the consistency between model outputs and human expectations or preferences.
- Model matching is based on the following rules:
- The system will randomly select two or more large models participating in the anonymous evaluation for comparison. The selection of multiple models is exclusive to the Multi-Models Battle mode, and the quantity of models selected is determined by the number chosen by the user.
- Following the principle of fairness, the random selection process will uniformly sample and distribute, reducing the impact of other factors on the overall results
- Model combat restrictions:
- During the combat, switching models is not supported, but interrupting the rating and starting a new round is supported
- To ensure the fairness of evaluations, do not ask for model identities in evaluations
- After voting, the current round of combat ends. You can not continue to ask questions, change votes or give preference
- Voting rule restrictions:
- In the model combats of language conversation and VLLM, you can initiate multiple rounds of dialogue until confirming the model that performs better
- In the text-to-image and text-to-video combat, after image generation completes, the dialogue ends and you need to give preference or score directly
- In order to ensure the validity and fairness of voting or scoring, at least one model needs to complete a full response before voting or scoring is allowed in each evaluation
- If there are two models battling, you can give preference to model A or model B, or select tie or both are bad. If there are more than two models battling, you can score each model’s response on a scale of 1 to 5. Your vote or score will affect models' scores and the results of subsequent rankings, so please make your selection carefully
- In anonymous combats, if any model identity has been exposed or an attempt is made to expose a model's identity in the problem, it will be considered an invalid vote or score, and this vote or score data will not affect model scores.