

Arena 简介及操作流程
模型对战说明
FlagEval天秤大模型角斗场是北京智源人工智能研究院(以下简称“智源”)出于科研目的,开放给用户的模型评测服务,请用户在遵守法律合规的前提下,上传相关数据或内容。 我们将收集并使用用户上传的数据内容,请您避免上传任何私人信息或敏感数据。 欢迎感兴趣的用户随时加入本评测。
对战模式
天秤大模型角斗场仅支持「匿名对战」模式,本次大模型对战支持纯文本、图文理解、文生图、文生视频共4种模态的对战形式。在模型对战前,用户可以通过点击各模态对应的Tab键自由选择一个模态进行模型对战,为保证模型对战的公平性,不同模态模型不会互相对战(如多模态大模型不与文生图大模型对战),其中文生图、文生视频不支持多轮对话形式。
智源FlagEval天秤评测团队(以下称为本团队)为确保后续对战结果榜单达到科学、权威、公正、开放的目标,在本次模型对战中,本团队评测专家以模型评测能力划分为基础,为用户提供具有隐藏标签的预设prompt输入。在纯文本、图文理解、文生图3种模态下,用户也可以选择自己在对话框中输入prompt,文生视频则不支持自主输入。
角斗场界面除了给用户提供不同的对战模态选择外,还提供了深度思考和多模型对战这两个对战方式的选择,点击界面上相应按钮即可切换到对应的方式中,用户也可以都不选择,通过一般方式对战。其中深度思考方式下,对战模型均为推理模型,多模型对战方式下,用户可指定参与对战的模型数量,可选数量为3~10个.
在您确认对战模型的模态后,如果通过一般方式对战,那么输入Prompt后,系统将随机抽取两个匿名模型展开对决,在对决中,参与对战的模型将同时回答您的问题,在一轮或多轮对话后,您可根据大模型对同一个输入问题的答案进行投票,选出您认为表现更优秀的模型,在投票后,即可查看两个匿名大模型的真实名称(如存在版本,则同时显示版本号)。
同样地,在深度思考方式下,输入Prompt后,系统将随机抽取两个匿名的推理模型展开对决,在对决中,参与对战的模型将同时回答您的问题,并展示深度思考时间,在一轮或多轮对话后,您可根据大模型对同一个输入问题的答案进行投票,选出您认为表现更优秀的模型,在投票后,即可查看两个匿名大模型的真实名称(如存在版本,则同时显示版本号)。
在多模型对战方式下,系统随机抽取用户选定数量的模型,参与对战的模型将同时回答您的问题,在一轮或多轮对话后,您可根据大模型对同一个输入问题的答案分别打分,有1-5分这5个等级。评分后,即可查看匿名大模型的真实名称(如存在版本,则同时显示版本号)。
关于测试模型:本项目中,存在部分不愿公开名称的模型(包括但不限于未发布模型&内部测试&实验&验证模型),当命中该类模型池中的模型时,公布名称均为测试模型
针对两个模型对战的情况,FlagEval天秤大模型角斗场首次采用梯级胜负评测。将模型生成内容质量差异细化为A远好于B、A略好于B、AB差不多、B略好于A、B远好于A共5个梯度。
其中“AB差不多”又分为“都好与都不好”。这一评测方式较传统Arena评测(仅分为“A更优、B更优、两者相似”三个等级)能够提供更多信息,更好地捕捉模型生成内容的细微差异,有望更精确揭示模型性能差异,从而发现更丰富和深入的结果。
| 对战模式 | 说明 |
|---|---|
| 匿名模型对战 | 系统随机选择两个模型展开对战;在多模型对战模式下,系统会随机选择用户指定数量的模型参与对战。 模型回答均调用由模型方提供的商业化 API 生成,答案不受本团队限制与编排,用于评估模型在文本生成、图文理解、文生图、文生视频等方面的能力。 文生图功能可能受到 QPS 调用限制,可能会出现生成失败或生成时间延长等问题。如遇此类情况,可尝试重新生成。 |
对战流程及结果
一般对战方式下的流程及结果
您可参考以下流程,开展模型对战:
- 进入FlagEval天秤大模型竞技场,开启匿名对战:
- 通过切换页面上方的Tab键,自由选择4种模态中的其中一种
- 可在对话页面中直接输入您的问题或选择平台预设的prompt
- 在您输入prompt后,左右两个匿名模型将同时进行回答,在图文理解和语言类模型的对战中,您可进行多轮对话,让模型做进一步的解释
- 根据模型的回复,投票选择更满意的答案
- 为确保投票的有效性与公平性,您需要得到任意一个模型至少一轮完整的回复后才能投票。
- 您可以对A模型或B模型进行倾向性打分,或者选择两个都好、两个都差。你的投票将影响模型的评分,请谨慎选择。
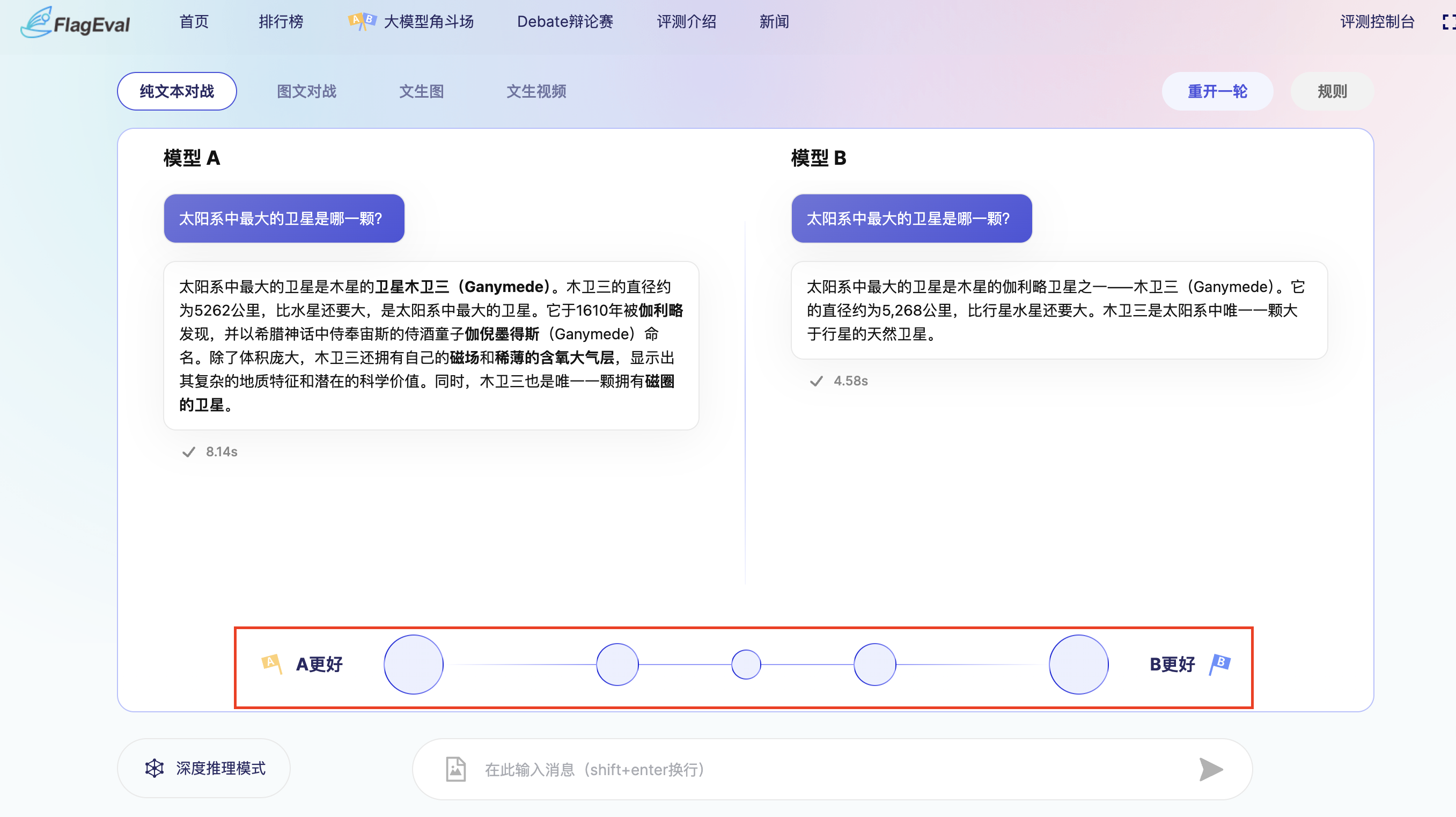
- 查看模型及配置 投票后页面将揭晓两个对战模型的真实名称及版本信息(如有),本轮模型对战结束,您还可以:
- 重开一轮:系统将再次随机选择两个匿名模型,在当前对战模式下再次开展一轮模型对战。
- 分享:将对战结果分享给你的好友或发布到社交网站,邀请大家一起体验
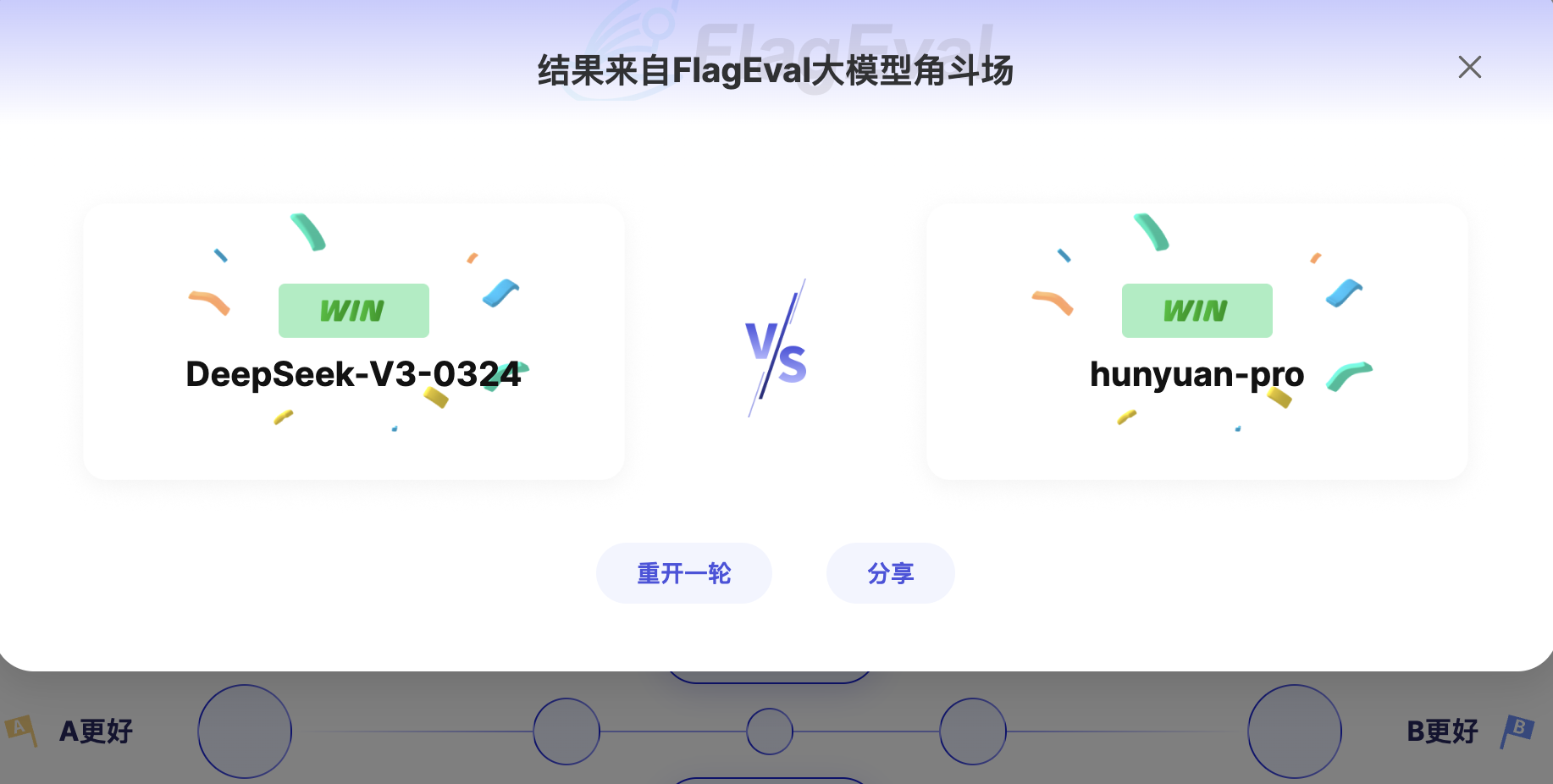
对战结果
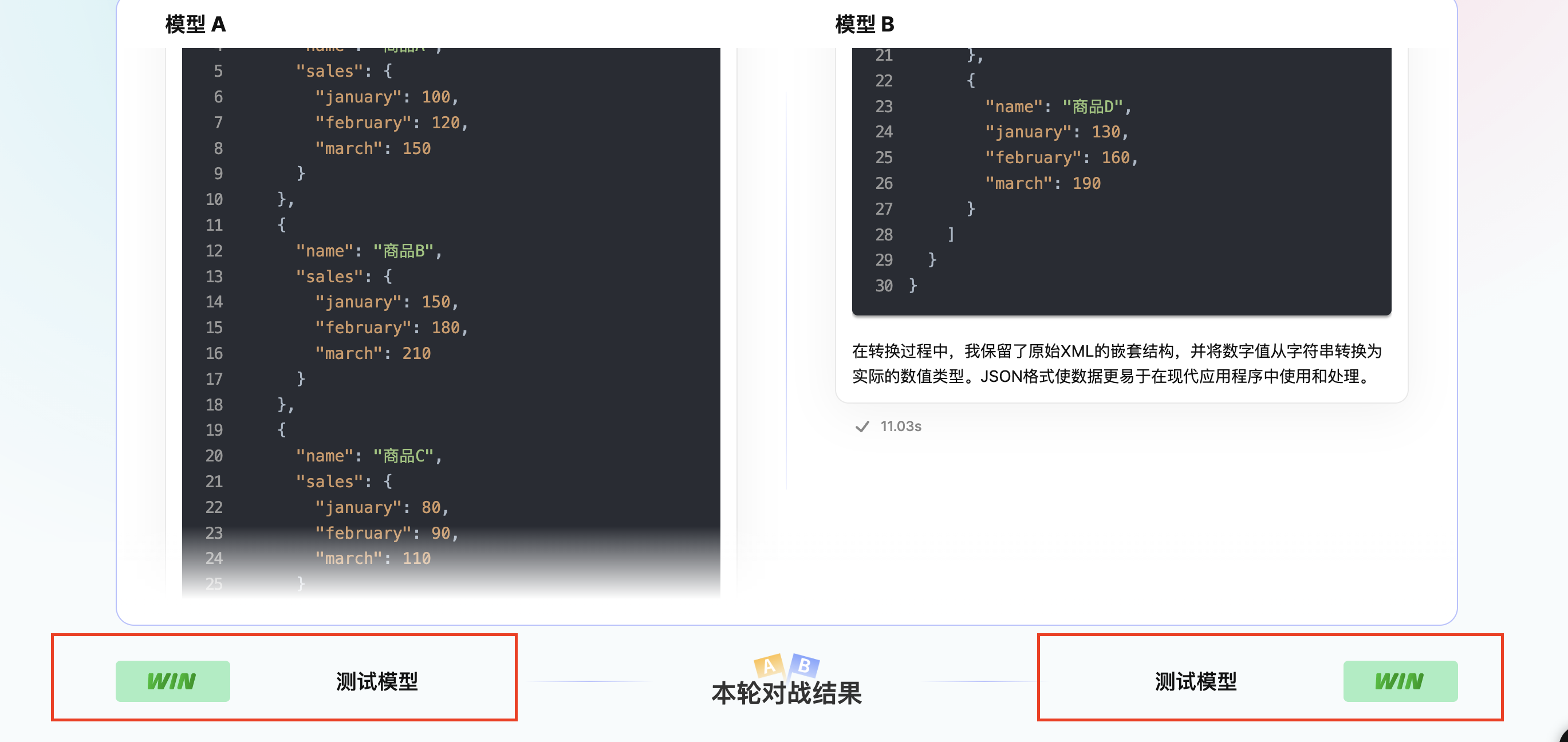
投票后,页面会展示本轮对战的胜负方,并揭示模型的真实名称,如下: 
深度思考方式下的流程及结果
选择纯文本和图文理解这两个模态时,用户可以看到在页面左下角有一个深度思考可供选择,点击后进入深度思考方式。
对战模型均为推理模型,相比于直接生成的模型,推理模型的反应时间较慢,可能需要耐心等待其推理完成返回结果。在深度模式下不能进行多模型对战。
进入深度思考方式后,您可参考以下流程,开展模型对战:
- 在对话页面中直接输入您的问题或选择平台预设的prompt
- 在您输入prompt后,左右两个匿名模型将同时进行深度思考,在思考结束后输出回答,并在页面上展示思考时间。您可进行多轮对话,让模型做进一步的解释
- 根据模型的回复,投票选择更满意的答案
- 为确保投票的有效性与公平性,您需要得到任意一个模型至少一轮完整的回复后才能投票。
- 您可以对A模型或B模型进行倾向性打分,或者选择两个都好、两个都差。你的投票将影响模型的评分,请谨慎选择。
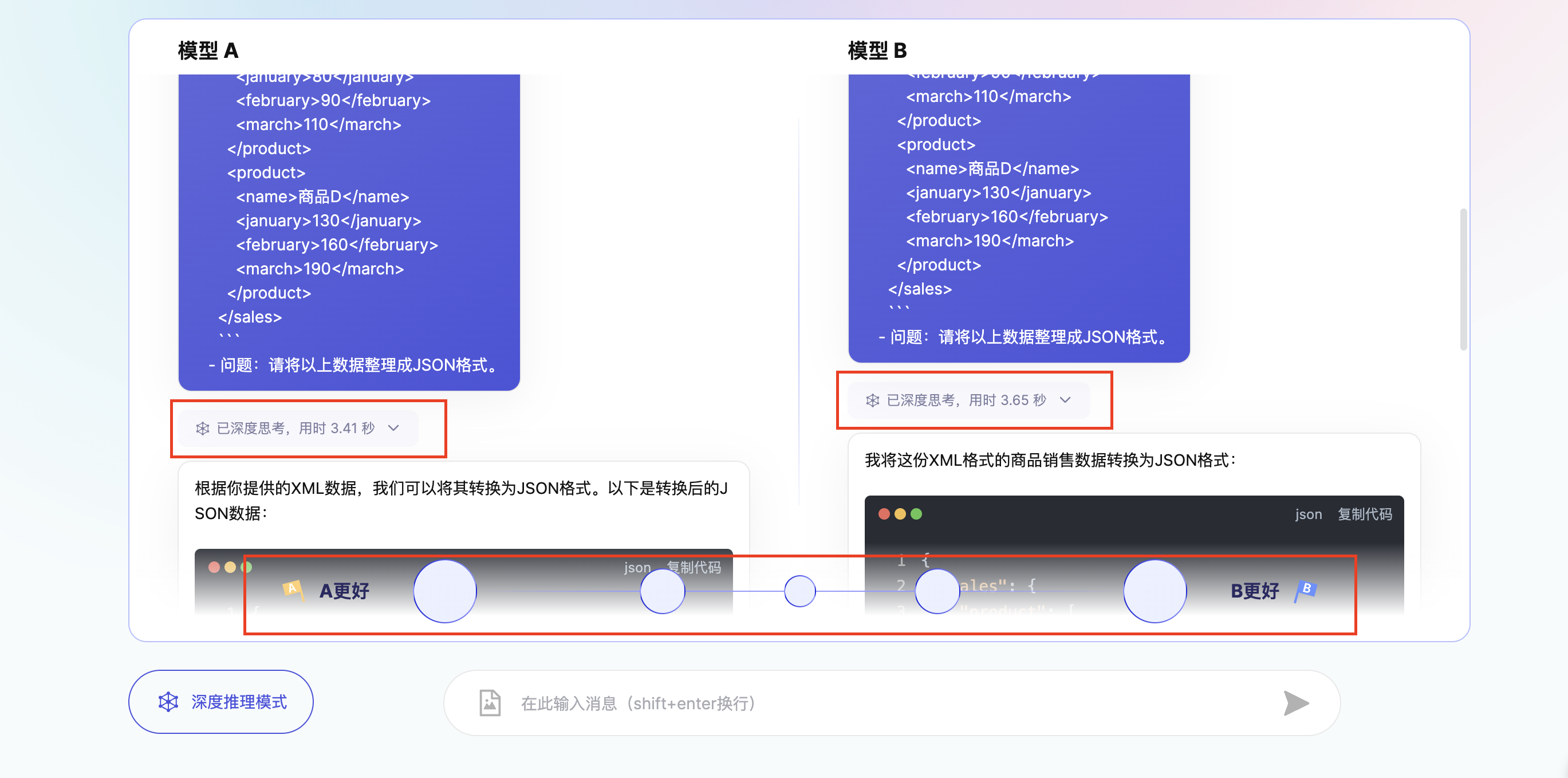
- 查看模型及配置 投票后页面将揭晓两个对战模型的真实名称及版本信息(如有),本轮模型对战结束,您还可以:
- 重开一轮:系统将再次随机选择两个匿名模型,在当前对战模式下再次开展一轮模型对战。
- 分享:将对战结果分享给你的好友或发布到社交网站,邀请大家一起体验
- 查看思维链:在结果界面查看推理模型的思考过程(如有)
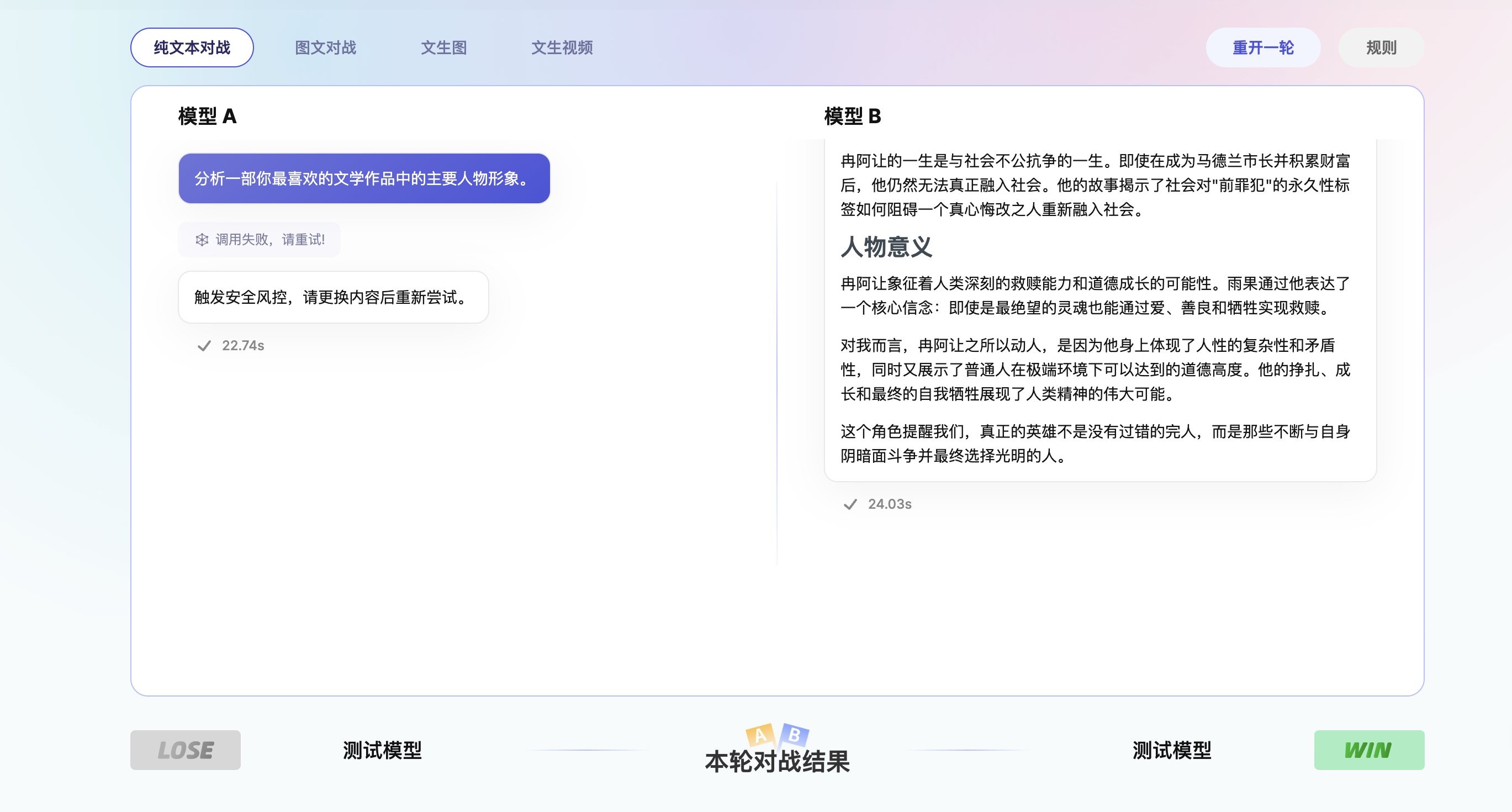
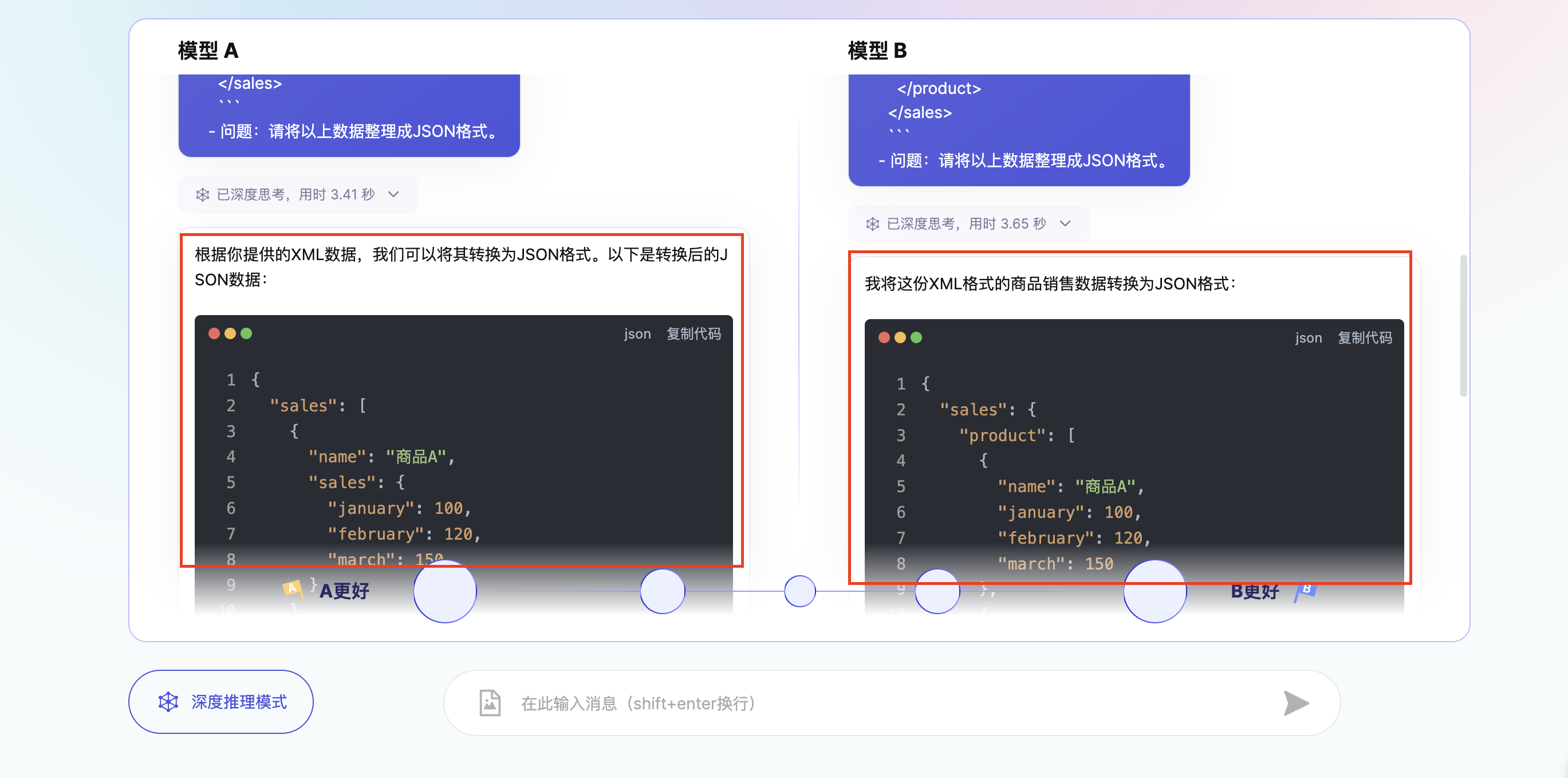
对战结果
投票后,页面会展示本轮对战的胜负方,并揭示模型的真实名称,如下:
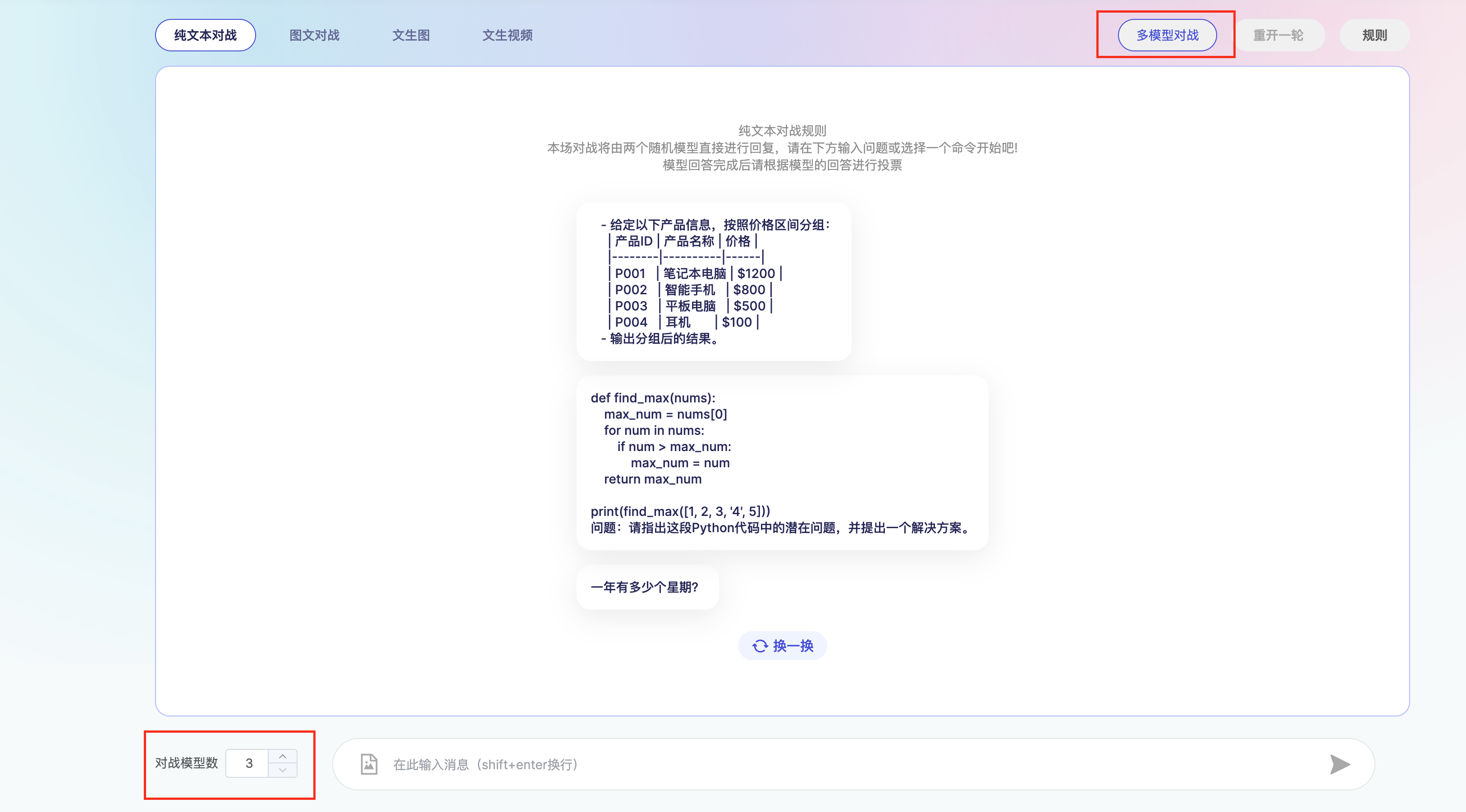
多模型对战方式下的流程及结果
- 用户点击页面右上方多模型对战按钮,进入多模型对战模式,同样用户可以自由选择4种模态中的其中一种,接着在界面左下角可以选择对战模型的数量,可选模型个数在3~10个,具体数量由用户自己决定。确定后,就能在底部对话框输入或选择平台预设的prompt开启对战。
进入多模型对战后,您可参考以下流程,开展模型对战:
- 通过切换页面上方的Tab键,自由选择4种模态中的其中一种
- 用户选择模型对战数量,可选择3~10个模型,多个模型同时进行回答,在图文理解和语言类模型的对战中,您可进行多轮对话,让模型做进一步的解释
- 在对话页面中直接输入您的问题或选择平台预设的prompt
- 根据模型的回复,给每个模型打分,有1-5分5个选择
- 为确保打分的有效性与公平性,您需要得到任意一个模型至少一轮完整的回复后再评分。
- 只有在所有模型,均为未被打分前,您才可以继续多轮问答,只要有一个模型进入了打分环节,则不支持多轮问答
- 您的评分将影响模型评测结果,请谨慎选择。
- 查看模型及配置 在完成每一个匿名模型评分后,投票区域返回模型名称和分数,不评分则不显示,在多模型对战下结果暂不支持分享,您可以:
- 重开一轮:系统将再次随机选择对应数量的匿名模型,在当前对战模式下再次开展一轮模型对战。
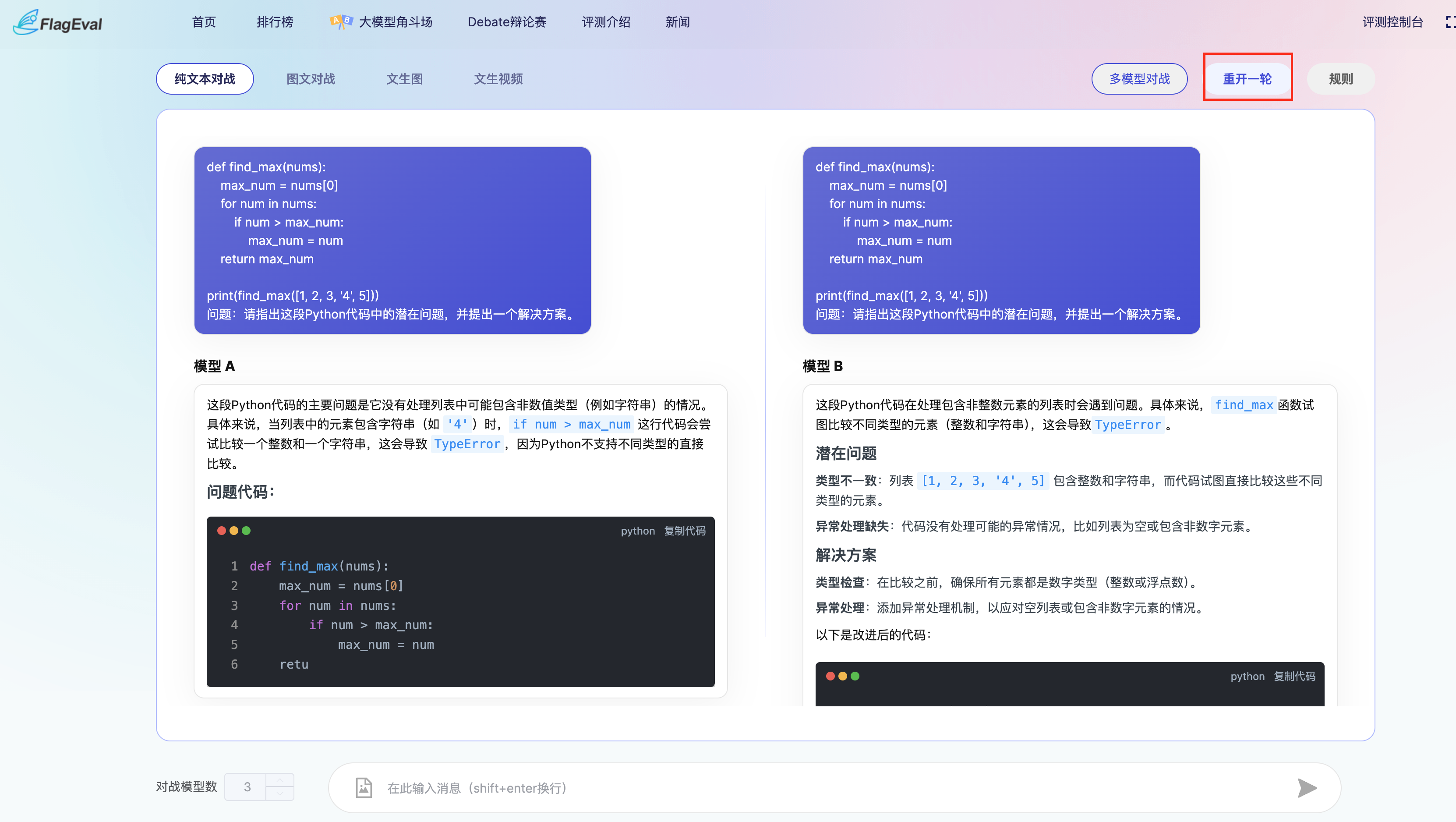
多模型对战方式下,采用的是评分制,因此没有输赢结果展示。
对战规则
为确保主观评测尽量覆盖模型的能力范围,您可采用多轮对话对模型进行多轮交流和提问,本次评测不对评测问题做限制,以期最大程度衡量模型输出与人类的期望或偏好的一致性。
- 模型匹配基于以下规则:
- 系统将随机抽取两个或多个本轮参与匿名评测的大模型进行比较,其中抽取多个只限于多模型对战方式,抽取的数量根据用户选择的模型数量决定
- 遵循公平性原则,随机选择的过程会均匀采样、分流,降低其他因素对整体结果的影响
- 模型对战限制:
- 对战过程中,不支持切换模型,但支持中断评分重开一轮
- 为保证评测的公平性,请勿在评测中询问模型身份
- 投票/评分后本轮对战结束,不支持继续提问、更改投票或打分
- 投票规则限制:
- 在语言对话与图文理解的模型对战中,您可发起多轮对话,直到确认表现更好的模型
- 文生图、文生视频的模型对战中,完成图片或视频生成后,对话结束,需要您直接投票/打分
- 为了保证投票/评分的有效性和公平性,在每次评测中,都需要至少一个模型完成一轮完整回复后,才允许投票
- 在两个模型对战的模式下,您可以对A模型或B模型进行倾向性打分,或者选择两个都好、两个都差;在多个模型对战的模式下,您可以对每个模型的回答进行1-5分的评分。你的投票或评分将影响模型的最终评分,并影响后续发布榜单的结果,请谨慎选择。
- 匿名对战中如出现已暴露或问题中试图暴露模型身份的对决,投票/评分将被视为无效投票/评分,此投票/评分数据不会影响模型分数