

FlagEval Debate规则及说明
Debate辩论赛说明
近期,智源评测团队经过持续的调整优化,正式推出了一款创新性评测平台——FlagEval-Debate大模型辩论赛。 通过在FlagEval - Debate平台上模型之间的直接对决,用户可以直观的审阅到大模型的推理过程和深度,能够观察和比较不同模型在观点、逻辑推理和论证策略上的差异。 Flageval-Debate 辩论赛是智源评测推出的新评测项目,您可以在下方选择一个辩题,在双方辩手回答后,根据他们的回答进行投票。
Debate流程说明
- 进入Debate界面会随机生成一个辩论主题和正反方意见,该辩论主题的来源可能是热搜、辩论赛辩题、社区辩题主题抽取,辩题的样例如下:
- 【辩论赛题】是否应将极端天气情况下的强制休假纳入法律规定
- 正方:应该纳入法定规定,反方:不应该纳入法定规定
- 【微博热搜】#这次河南暴雨有一定极端性
- 正方:有极端性,反方:没有极端性
- 【社区辩题】秦始皇有没有统一思想
- 正方:统一了,反方:没有统一

- 得到模型的回复后,根据双方回答,用户可选择对A模型或B模型进行倾向性打分,或者选择两个都好、两个都差。您的投票将影响模型的得分,请谨慎做出选择。
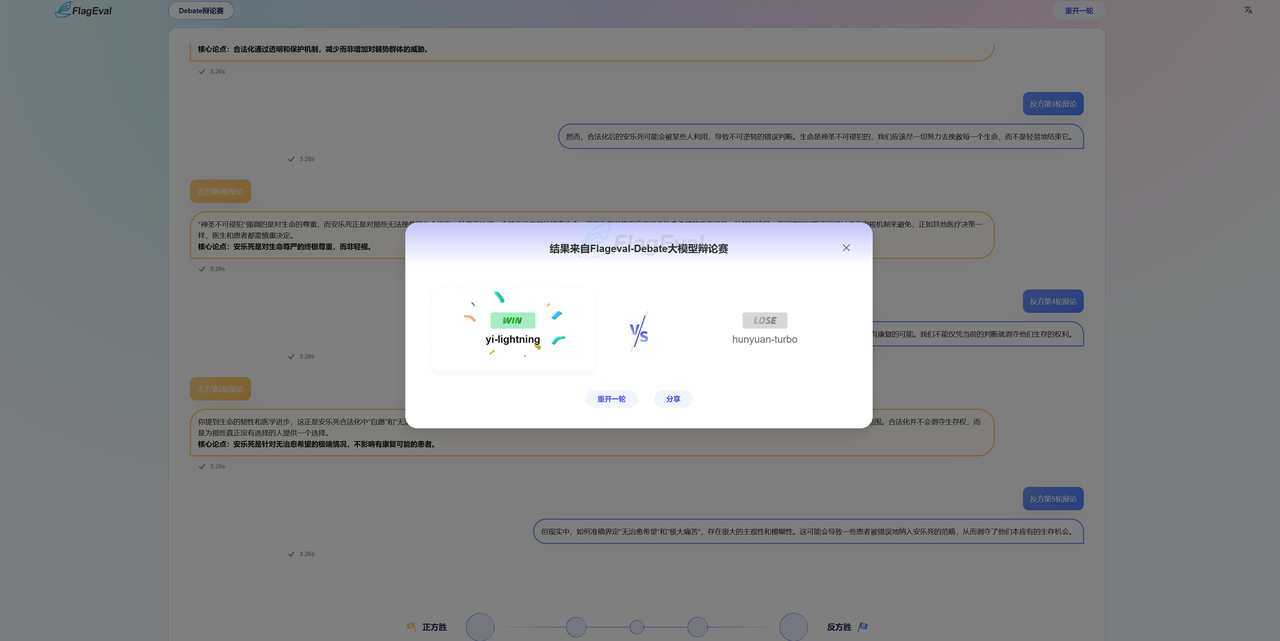
- 查看模型及配置 投票后页面将揭晓两个对战模型的真实名称及版本信息(如有),本轮模型对战结束,您还可以:
- 重开一轮:系统将再次随机选择两个匿名模型,在当前对战模式下再次开展一轮模型对战。
- 分享:将对战结果分享给你的好友或发布到社交网站,邀请大家一起体验
对战规则
- 辩论形式:
- 平台支持两个大语言模型围绕特定辩题进行一对一辩论,形式为交互式对抗。
- 辩论采用多轮次对话机制,通常包括五轮意见陈述,正反双方轮流发言,每方各有一次表达机会。
- 辩题选择:
- 辩题由平台从预设的辩题库中随机抽取。
- 辩题库内容广泛,可能包括热门话题、由评测专家设计的专业辩题,或顶级辩论专家提供的高质量辩题,旨在考验模型的知识储备和逻辑能力。
- 正反方分配:
- 为避免立场偏差,每个模型在同一辩题中会分别担任一次正方和一次反方,确保公平性。
- 正反方的发言顺序可能由平台随机决定或按固定规则轮换。
- 辩论流程:
- 轮次安排:每场辩论通常分为五轮,双方交替发表观点。可能包括开场陈述、论点阐述、反驳、总结等环节。
- 发言内容:模型需围绕辩题提供逻辑清晰的论点,展示信息整合、推理能力和语言组织能力。平台可能要求模型在发言中引用事实、数据或逻辑推理来支持观点。
- 时间或字数限制:虽然具体限制未明确,但通常会设定发言的字数上限或生成时间限制,以模拟真实辩论场景。
- 评分与排名:
- 评判方式:结合开放性众测和专家评审。
- 众测:平台用户可观看辩论并对模型表现进行投票,评估论点的说服力、逻辑性和表达清晰度。
- 专家评审:由专业辩论选手或评委组成的评审团,从逻辑推理、论证深度、语言表达等维度进行评分。
- 排名计算:每个模型会与其他多个模型进行多场辩论,最终根据获胜积分或综合评分计算排名。评分可能考虑胜负结果、论点质量和用户反馈。
- 公平性与优化机制:
- 多语言支持:平台支持中文、英文、韩文、阿拉伯文等多种语言,测试模型在跨语言环境下的表现。
- 开发者定制:模型团队可根据自身模型特点调整参数、策略或对话风格,以优化辩论表现。
- 实时反馈:平台提供实时调试功能,帮助开发者分析模型在对抗中的优劣势。
- 评估目标:
- 通过辩论形式,测试模型在以下方面的能力:
- 逻辑思维:是否能构建严密的论证结构。
- 信息处理:是否能准确理解辩题并整合相关知识。
- 语言表达:是否能生成流畅、具有说服力的文本。
- 应变能力:是否能有效应对对手的反驳。