评测操作流程
用户注册完,并按照报名评测要求补充个人信息后,等待平台审核。
审核通过后,用户登录可以点击【评测控制台】按钮,进入【评测控制台页面】。
点击【创建评测】进入参数配置界面,首先需要在5个评测领域中选择一个,再进行后续参数配置。
不同评测领域选择
NLP领域模型评测
创建评测
用户在创建评测页面,点击【NLP】这一评测领域,填写相关参数点击提交,跳转到模型评测实例详情页面。 在参数填写的界面,需填写的基本信息有:
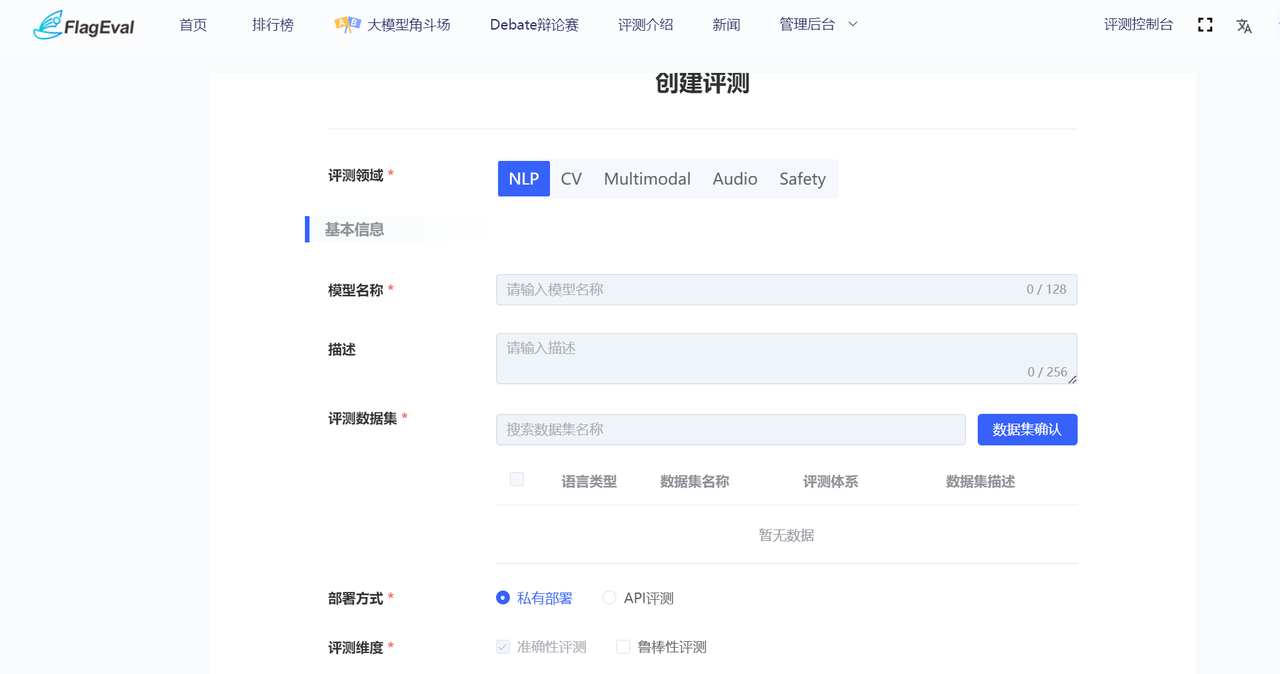
具体表单如下:
| 参数类别 | 参数名称 | 参数描述 |
|---|---|---|
| 基本信息 | 评测领域 |
|
| 模型名称 |
| |
| 描述 |
| |
| 评测数据集 |
| |
| 部署方式 |
| |
| 评测维度 | 必填 可选 是否进行鲁棒性评测,准确性评测为内置选项 |
根据基本信息中部署方式的不同,需填写不同的表单:
| 部署方式 | 参数类别 | 参数名称 | 参数描述 | 图例 |
|---|---|---|---|---|
| 私有部署 | 环境配置 | 选择镜像 |
| 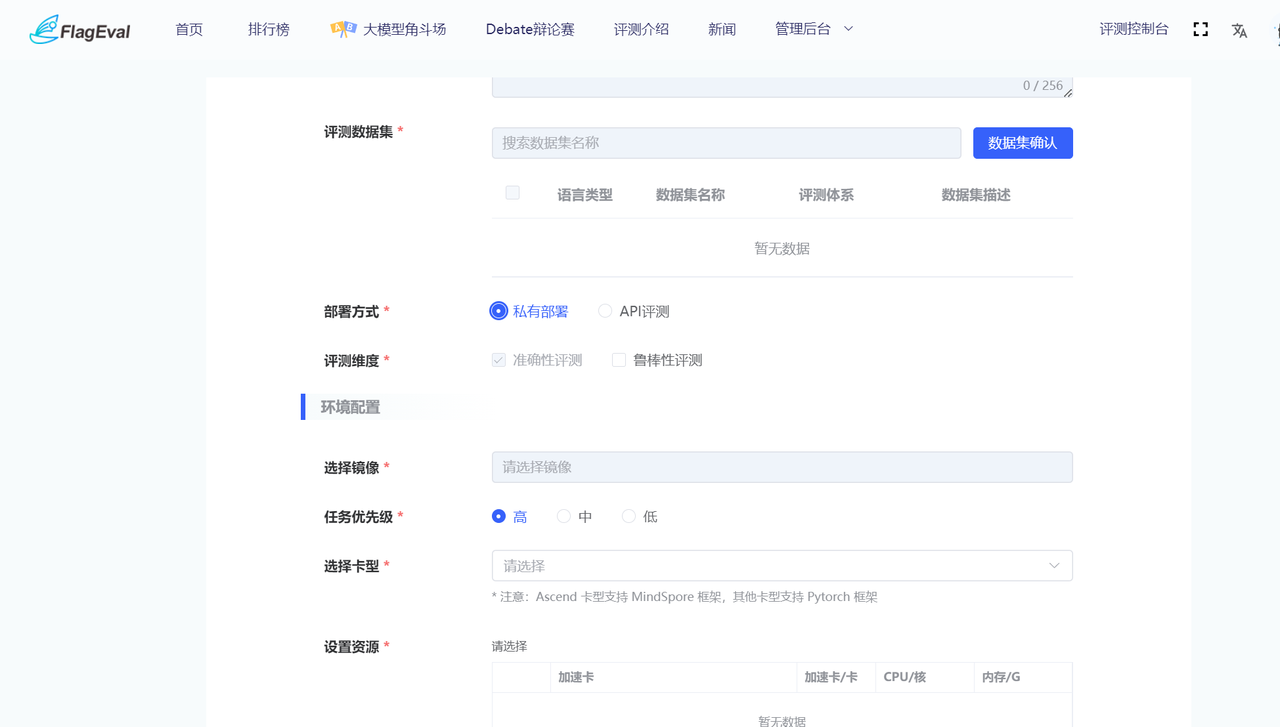 |
| 任务优先级 | 必填 有高中低三个选项 | |||
| 选择卡型 |
| |||
| 设置资源 |
| |||
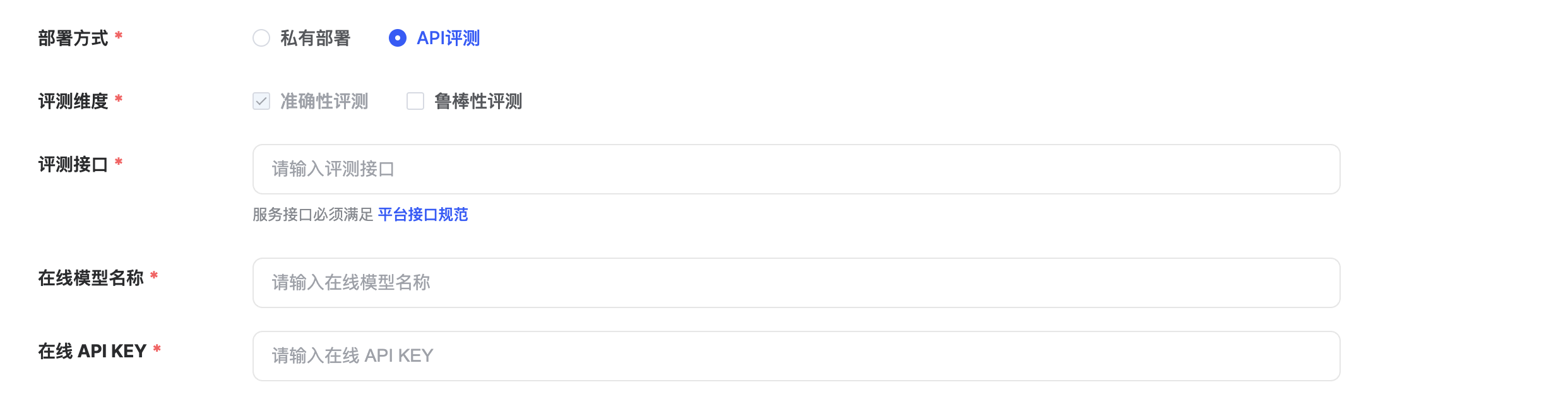
| API评测 | 基本信息 | 评测接口 | 评测接口提供需支持标准 API 并通过 HTTP 请求进行调用,支持POST请求。必填 | 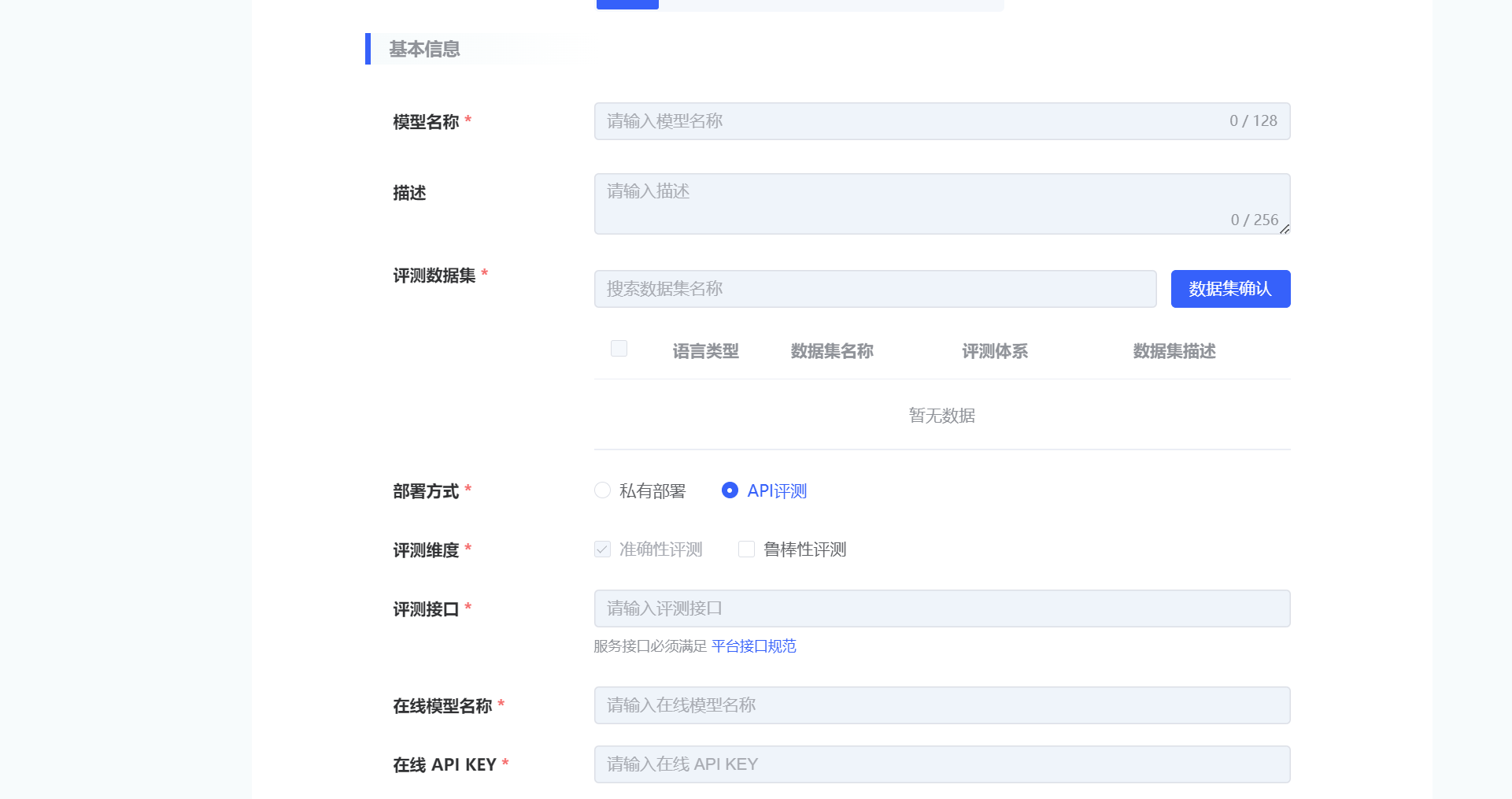 |
| 部署方式 |
| |||
| 在线模型名称 | 填写所评模型的官方名称。必填 | |||
| 在线 API KEY | 后台数据访问接口许可的密码。必填 |
本平台支持以【私有部署】、【API评测】两种方式开展模型评测
- 【API评测】操作:
- 如计划使用API接口开展模型评测,需提前按照FlagEval平台接口规范准备标准格式API接口及apikeyFlagEval评测 - API接口要求
- 在【部署方式】中选择【API评测】
- 选中【API评测】后下方自动出现「评测接口」、「在线模型名称」、「在线API KEY」3个参数
- 完成「评测接口」、「在线模型名称」、「在线API KEY」3个参数内容的填写
除上述信息外,还需填写模型相关信息:
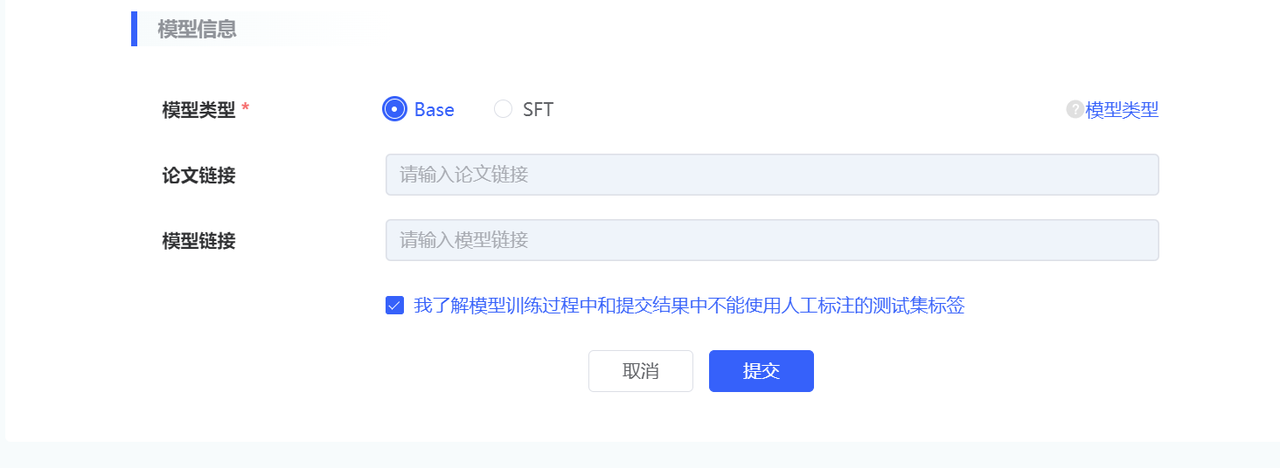
| 参数类别 | 参数名称 | 参数描述 |
|---|---|---|
| 模型信息 | 模型类型 |
|
| 论文链接 | ||
| 模型链接 |
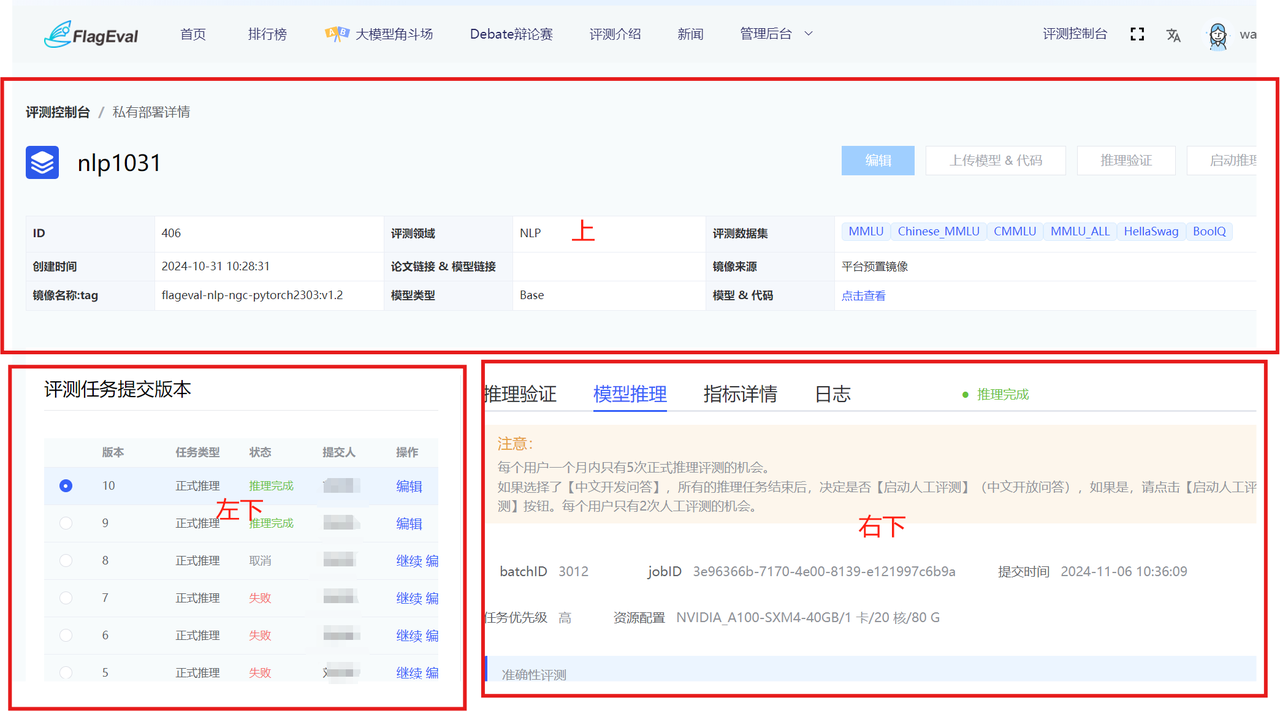
上半部分:
- 显示用户【创建评测】时的具体参数。
- 用户操作有:【编辑】、【上传模型&代码】、【推理验证】、【启动推理评测】。
- 【编辑】操作:除模型名称和评测领域之外都允许编辑。
- 【上传模型&代码】操作:弹出上传模型和代码的引导页面。
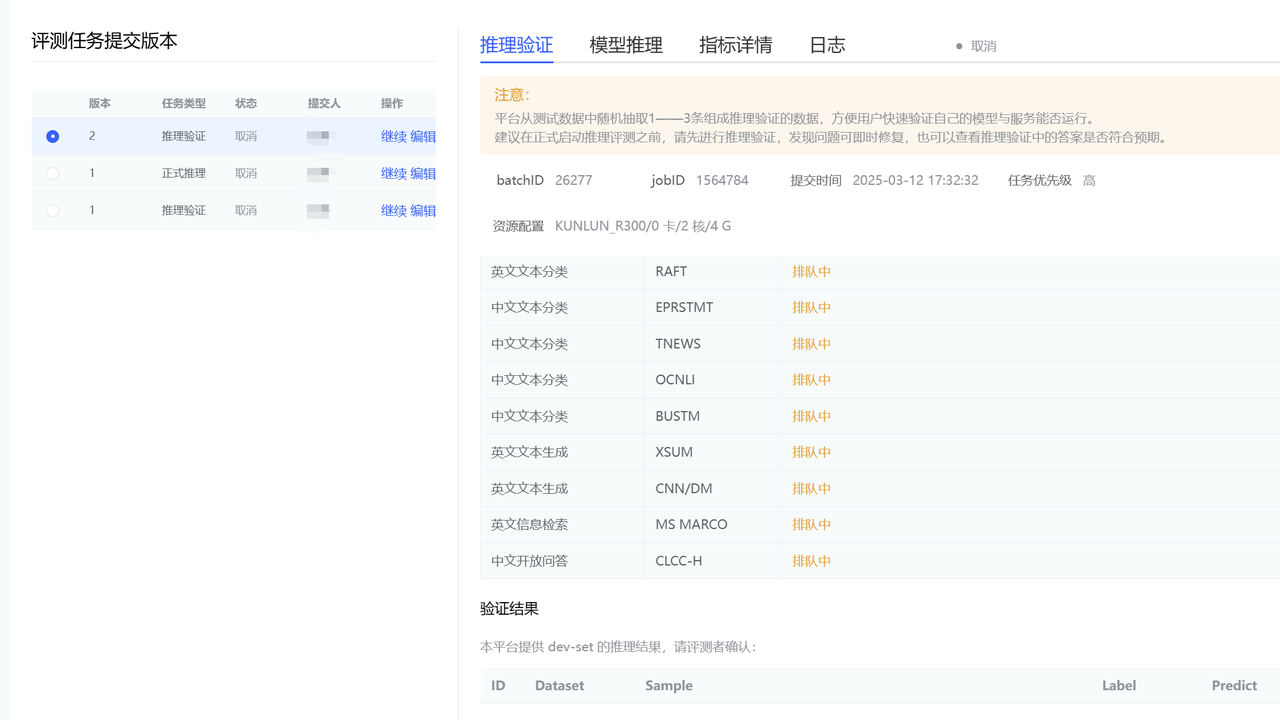
【推理验证】操作:
- 平台从测试数据中随机抽取1——3条组成推理验证的数据,方便用户快速验证自己的模型与服务能否运行。
- 建议在正式启动推理评测之前,请先进行推理验证,发现问题可即时修复,也可以查看推理验证中的答案是否符合预期。
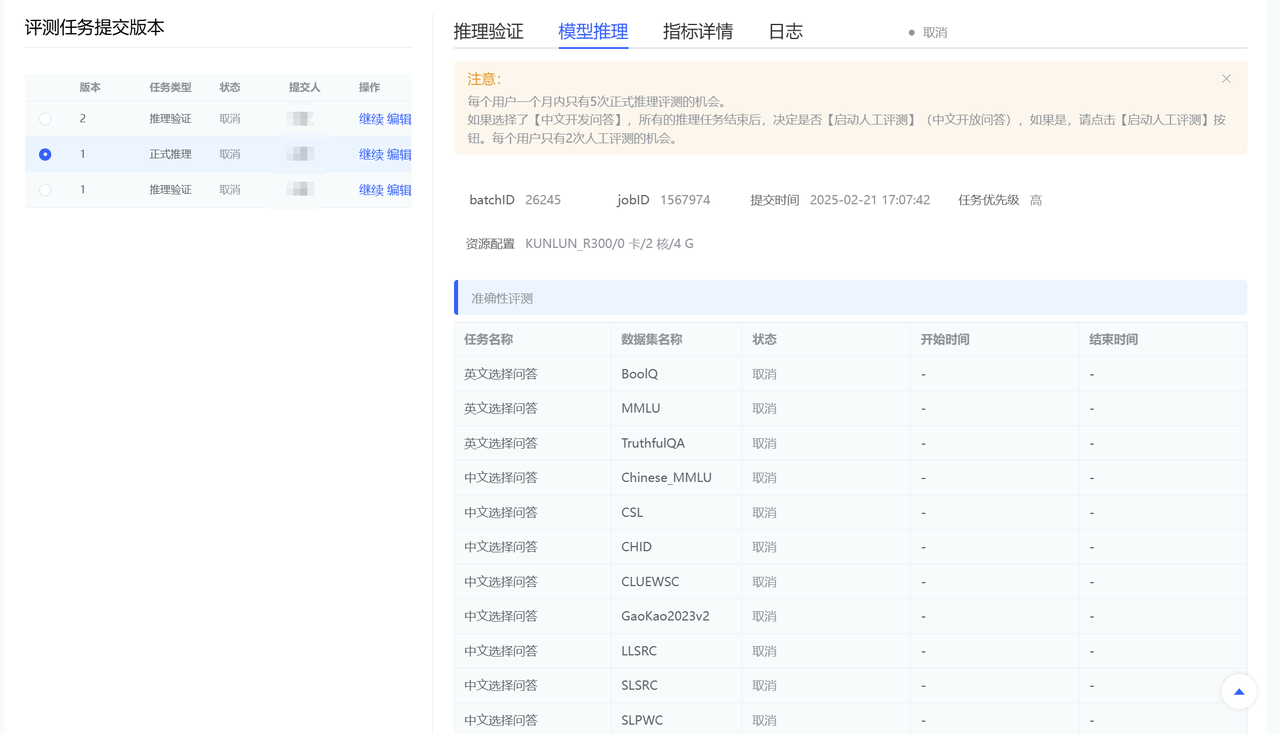
【启动推理评测】操作:用户推理验证模型与服务没问题后,可以点击启动推理评测,启动后整个推理评测的过程大概持续数个小时。
评测任务结束时会给用户发送邮件通知。- 目前仅支持单机推理评测。
左下部分:
- 展示用户启动推理和推理验证的历次版本。
- 展示参数有:版本、任务类型、状态、提交人、操作。
- 任务类型有:推理验证&正式推理。
- 【停止】操作:点击该操作,推理过程结束。
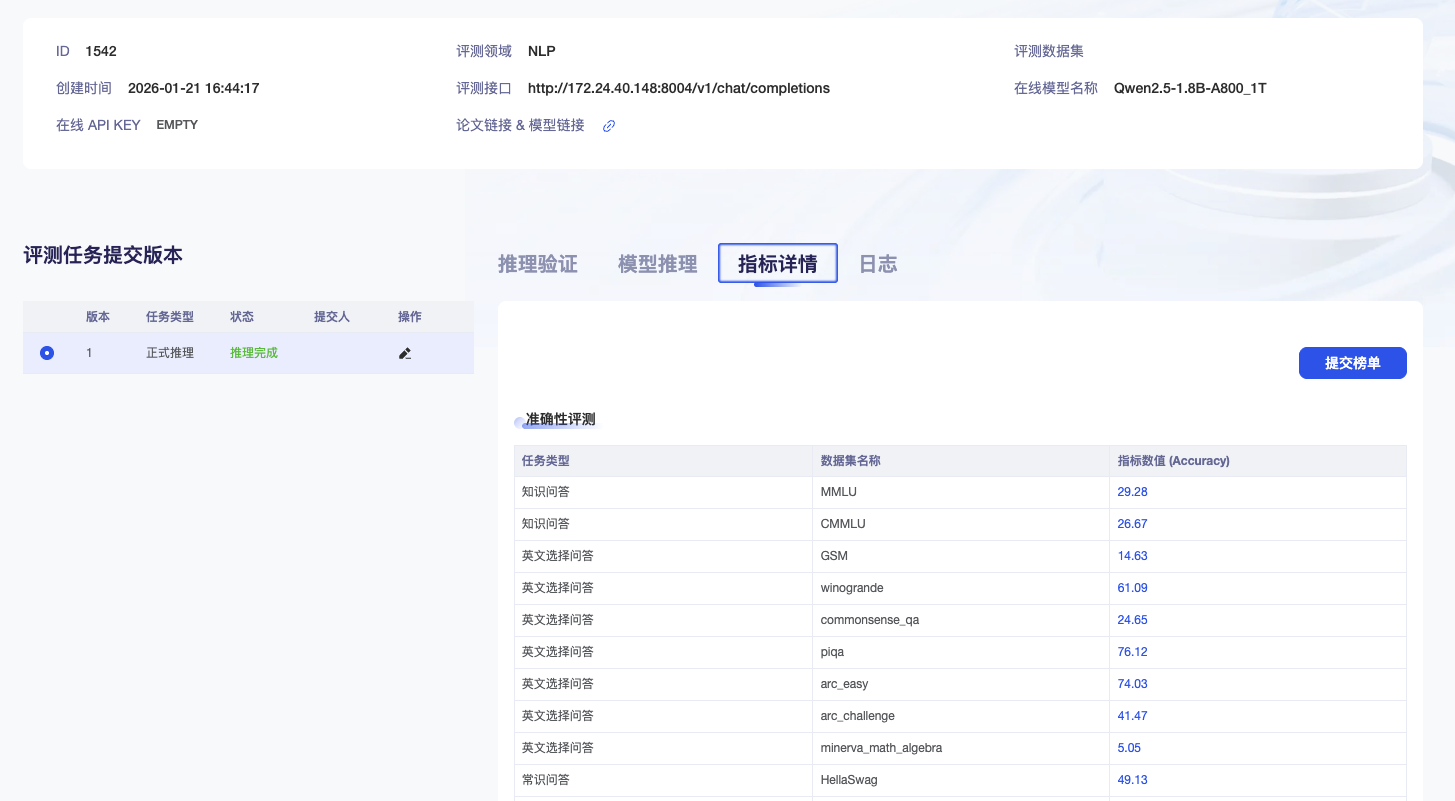
右下部分包括:推理验证详情页面、模型推理进度页面、指标详情页面、日志页面。
- 推理验证tab页面:数据集进度展示(任务名称、数据集名称、状态);
- 验证结果——平台提供部分推理结果,用户可自行确认,数据字段:ID、Dataset、Sample、Label、Predict。
- 推理验证tab页面:数据集进度展示(任务名称、数据集名称、状态);
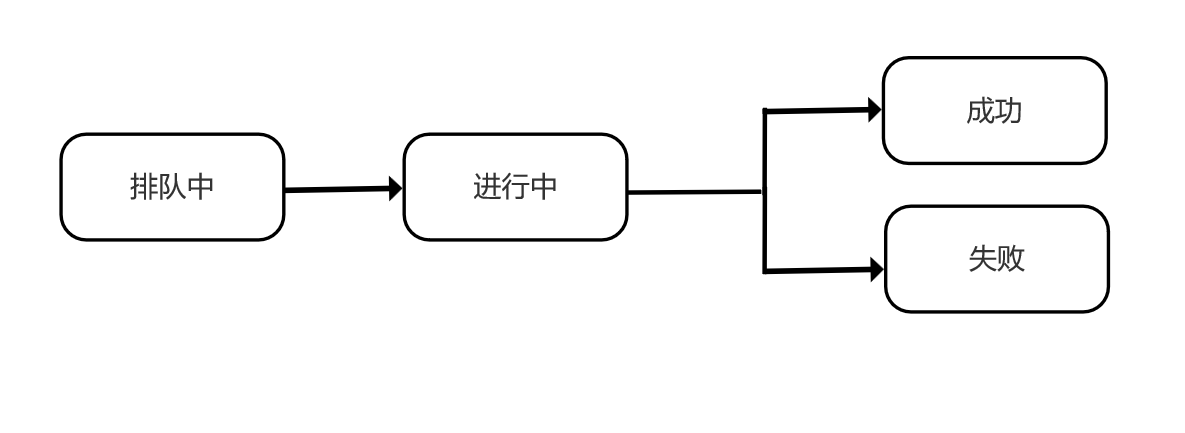
- 模型推理进度tab页面
- 主要记录推理提交时间;任务名称、数据集名称、状态、开始时间、结束时间。
- 推理过程:串行(任务数据集)推理。每个数据集的状态流转如下图。
- 指标详情页面。推理评测中,用户可以随时查看已经推理评测完的数据集的成绩,每个评测任务都计算自己的平均值。
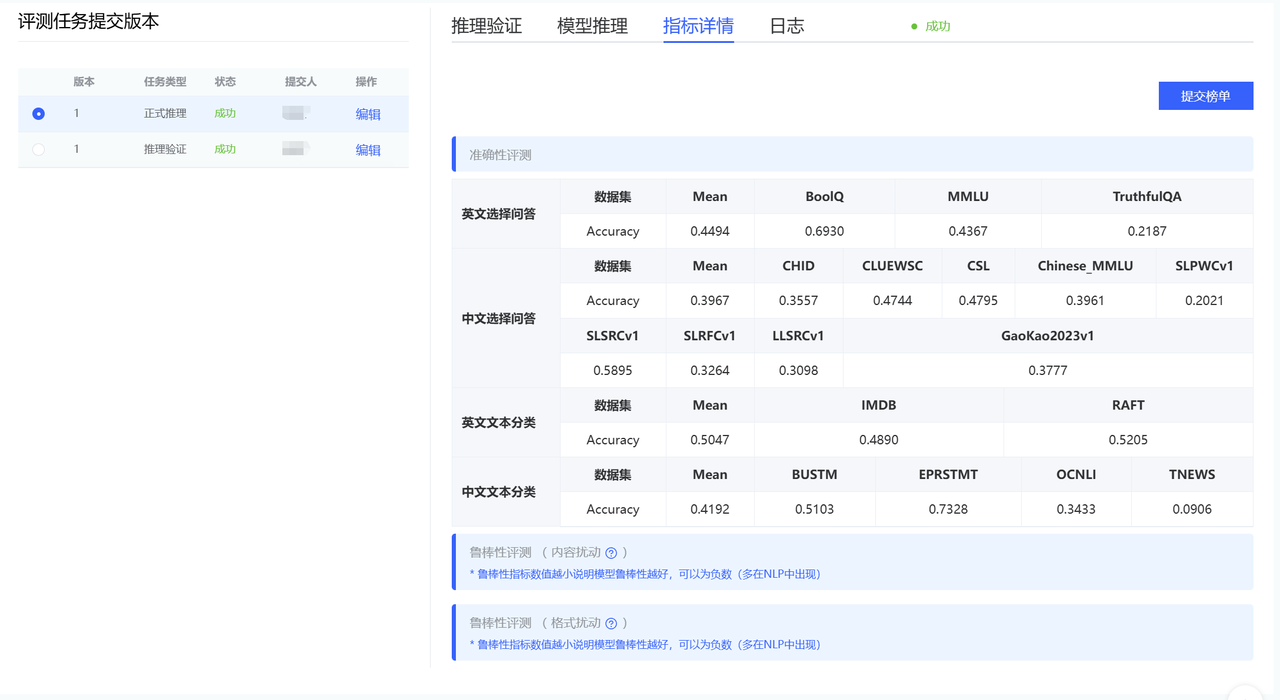
- 整个推理任务结束后,用户可以根据自己的成绩自行选择是否提交到排行榜中,可以选择【匿名提交】或【具名提交】。
- 用户点击【具名提交&匿名提交】按钮,将成绩同步到NLP排行榜,与NLP排行榜格式保持一致。只有点击提交的成绩才会出现在排行榜上。
- 具名提交:展示提交人的真实姓名与组织单位;匿名提交:提交人的真实姓名与组织单位显示为:【匿名】二字。
注意:
- 用户每个月只有5次启动正式推理评测的机会。
主观推理评测
如果用户选择了【中文开放问答】任务,则会涉及主观推理与评测。 由于主观推理的评测,需要人工进行标注评测,成本比较大,因此限制每个用户最多2次人工评测次数。等【中文开放问答】推理完成后,点击【启动人工评测】按钮即可。
准备
(1) 安装 FlagEval-Serving
pip install flageval-serving模型权重评测
目前新的 harness 和 harness-v0.4 支持对模型权重进行评测,且模型权重支持通过 transformers AutoModel 进行加载。
准备模型
目录结构
demo/
├── myModel # 模型目录包含模型权重和配置文件
│ ├── config.json
│ ├── tokenizer_config.json
│ └── model.pt
└── meta.json # 配置信息定义模型信息 meta.json
{
// 支持的评测方式。
"supported_evaluation_methods": [
// FlagEval Serving 的方式,需按文档提供 service.py,
// 可参与 HELM & Harness 评测框架的评测。
// "flageval-serving",
// HuggingFace 预训练模型,需在当前配置文件指定预训练模型的名称或位置,
// 可参与 lmeval、spor 和 lang 评测框架的评测。
"huggingface-pretrained",
],
// 指定 HuggingFace 预训练模型,支持两种格式:
// 1. 以 ./ 开始的当前目录下的预训练模型;
// 2. 格式为 "repository/name" 的 HuggingFace 模型名称,如:https://huggingface.co/Qwen/Qwen-1_8B,则填"Qwen/Qwen-1_8B"
"pretrained_model_path": "./myModel",
"pretrained_model_name": "my/myModel",
"pretrained_model_args": "attn_implementation=\"flash_attention_2\"",
}模型上传
首先在页面点击「模型上传」获取 token 然后填入下面的命令中:
flageval-serving upload --token='TOKEN' demoServing 模型进行评测(Legacy)
准备模型 & 代码
目录结构
如需接入 FlagEval 进行离线模型评测,需要将模型和代码放在同一个目录下:
demo/
├── model # 模型目录
│ └── info # 模型文件
├── local_guniconf.py # 服务配置文件
├── meta.json # 模型信息
└── service.py # 服务入口(其他依赖模块)定义模型信息
meta.json
{
"parameter_scale_billion": 7 // 模型参数规模(单位十亿)
}定义 Service
需要在 service.py 定义 Service :
from flageval.serving.service import NLPModelService, NLPEvalRequest, NLPEvalResponse, NLPCompletion
class Service(NLPModelService):
def global_init(self, model_path: str):
print("Initial model with path", model_path)
def infer(self, req: NLPEvalRequest) -> NLPEvalResponse:
print(req)
return NLPEvalResponse(
completions=[
NLPCompletion(
text='Hello, world!',
tokens='Hello, world!',
),
]
)本地模型调试
可以通过如下命令运行调试服务:
flageval-serving --service demo/service.py dev demo/model然后即可构造 curl 请求进行测试:
curl -X POST http://127.0.0.1:5000/func -H 'Content-Type: application/json' -d '{
"engine": "hello",
"prompt": "hello",
"temperature": 1.5,
"num_return_sequences": 1,
"max_new_tokens": 1,
"top_p": 1,
"echo_prompt": false,
"top_k_per_token": 1,
"stop_sequences": []
}'设置推理服务进程数
默认情况下,我们使用 1 个进程运行模型推理服务,如果需要个性化可以在 local_guniconf.py 中调整 workers 配置项:
workers = 4 # 使用 4 个 Worker 进程模型上传
在页面点击【上传模型 & 代码】获取 token 然后填入下面的命令中:
flageval-serving upload --token='TOKEN' demoCV领域模型评测
目前Flageval平台支持用户上传CV的backbone预训练模型,支持backbone模型冻结参数后在不同任务、数据集下进行finetune生成下游任务模型,并在相应的测试数据集上进行推理评测,得到模型在该数据集上的评测指标。
创建评测
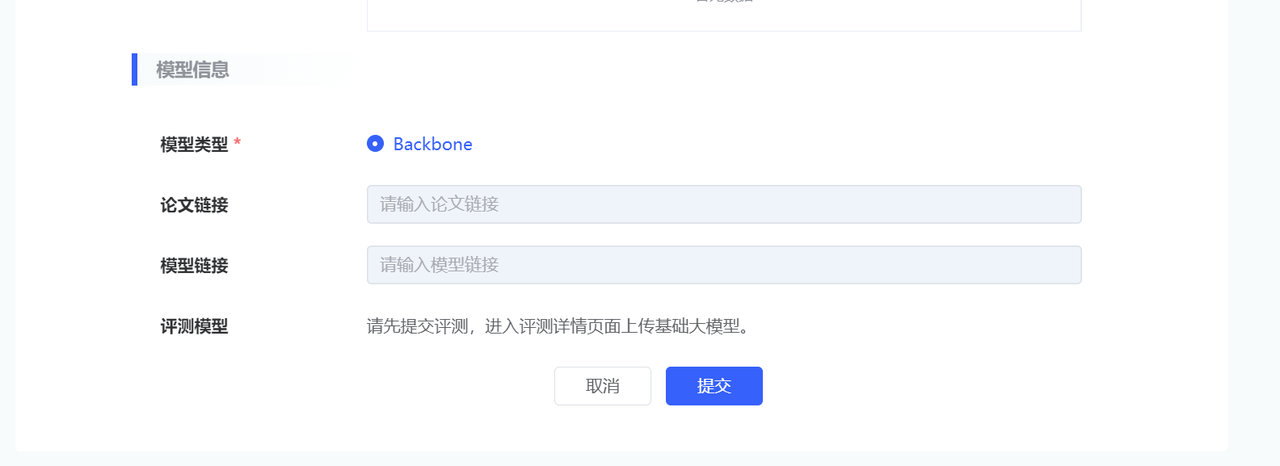
用户在评测任务列表页面,点击【创建评测】,弹出【创建评测】对话框,填写相关参数点击提交,跳转到模型评测实例详情页面。
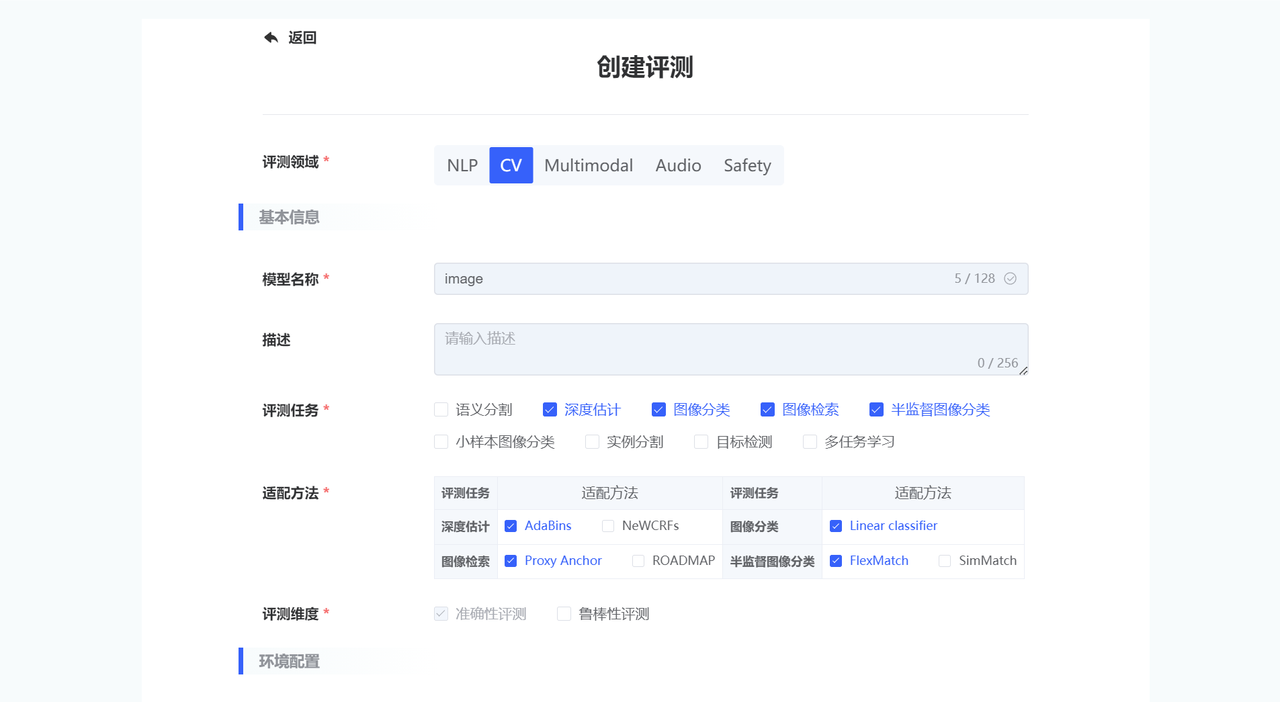
| 参数类别 | 参数名称 | 参数描述 |
|---|---|---|
| 基本信息 | 评测领域 | 选择评测领域CV。必填,单选 |
| 模型名称 | 输入待评测模型的名称,必填。支持3~32位可见字符,且只包含小写字母、数字、中间连字符-,以小写字母开头,以小写字母、数字为结尾。名称全平台唯一,不允许重复。 | |
| 描述 | 填写描述信息。选填,支持0~256位可见字符。 | |
| 评测任务 | 选择评测任务。必填,多选,不同任务关联不同的适配方法。 | |
| 适配方法 | 请选择 finetune 的适配方法,适配方法详情请参考任务介绍。 | |
| 评测维度 | 必填 可选是否进行鲁棒性评测,准确性评测为内置选项。 | |
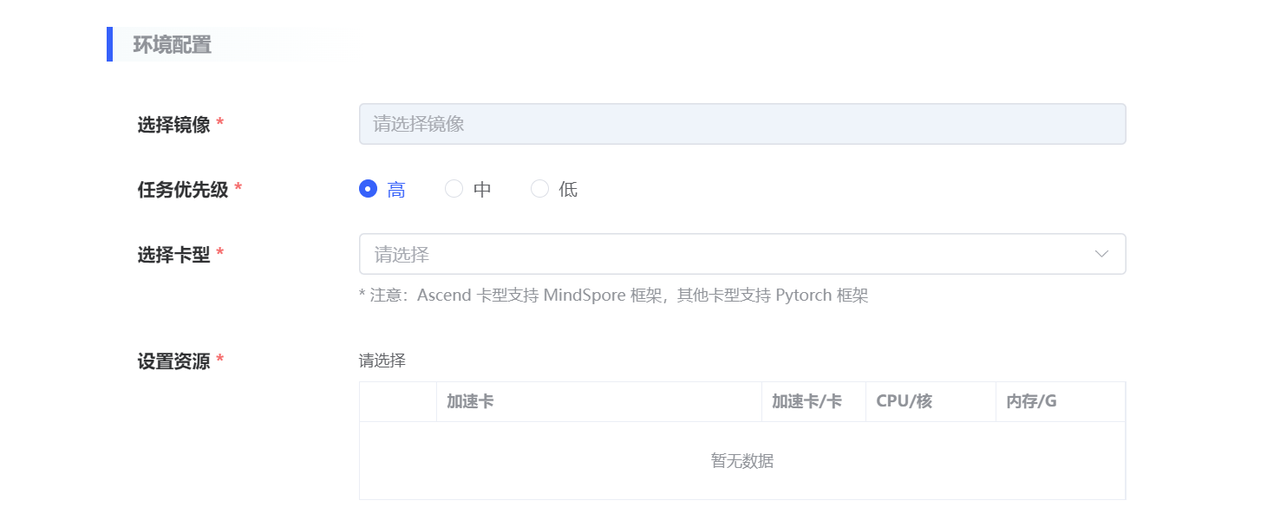
| 环境配置 | 选择镜像 |
|
| 选择卡型 |
| |
| 设置资源 | 根据模型大小设置所需资源,仅支持单机推理。必填,单选。如资源列表为空,请选择其他卡型。 | |
| 模型信息 | 模型类型 | 目前 CV 领域只支持 Backbone 预训练模型。 |
用户提交评测实例,跳转到评测实例详情页面,分为上、左下、右下三部分:
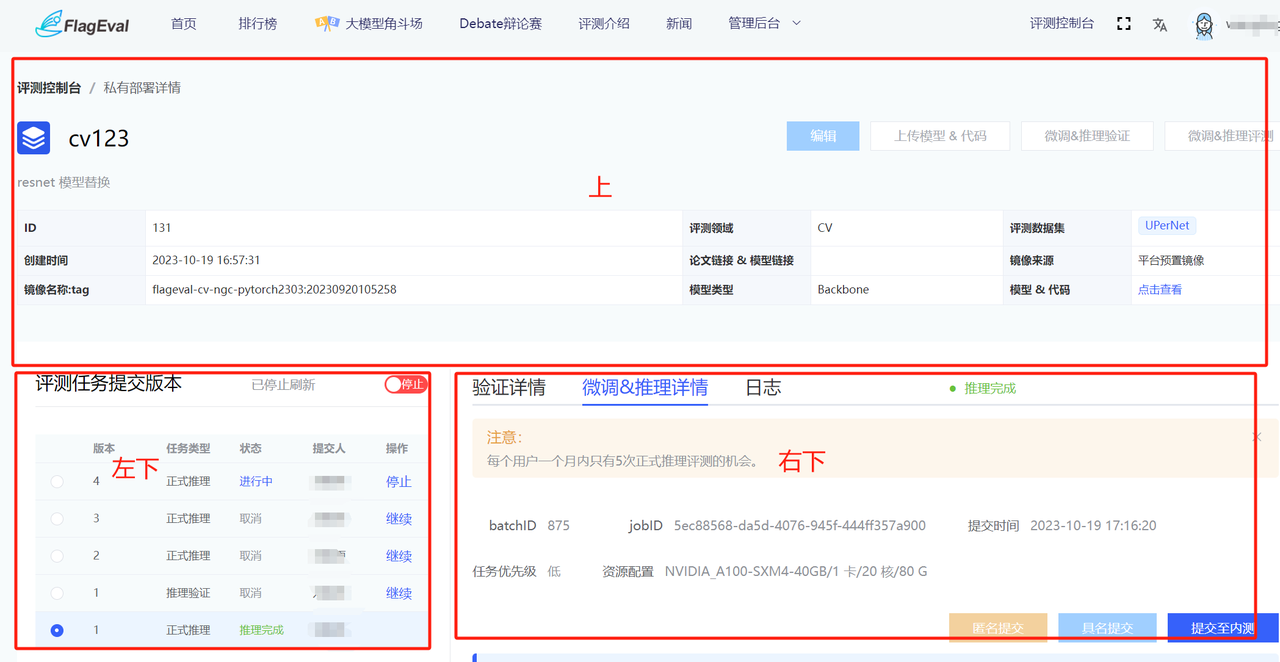
上半部分:
- 显示用户【创建评测】时的具体参数。
- 用户操作有:【编辑】、【上传模型&代码】、【微调&推理验证】、【微调&推理评测】。
- 【编辑】操作:除模型名称和评测领域之外都允许编辑。
- 【上传模型&代码】操作:弹出上传模型和代码的引导页面。
- 【微调&推理验证】操作:
- 平台从验证数据中随机抽取1——3个epoch的数据组成微调验证的数据,方便用户快速验证自己的模型与服务能否运行。
- 建议在正式启动微调&推理评测之前,请先进行验证环节,发现问题可即时修复。
- 【微调&推理评测】操作:用户验证模型与服务没问题后,可以点击微调&推理评测,启动后整个微调+推理评测的过程大概持续数个小时。评测任务结束时会给用户发送邮件通知。
- 目前仅支持单机微调与推理评测。
- 左下部分:
- 展示用户启动推理和推理验证的历次版本。
- 展示参数有:版本、任务类型、状态、提交人、操作。
- 任务类型有:推理验证&正式推理。
- 【停止】操作:点击该操作,推理过程结束。
- 右下部分包括:验证详情页面、微调&推理详情页面、日志页面。
- 验证详情页面:数据集进度展示(任务名称、数据集名称、状态);
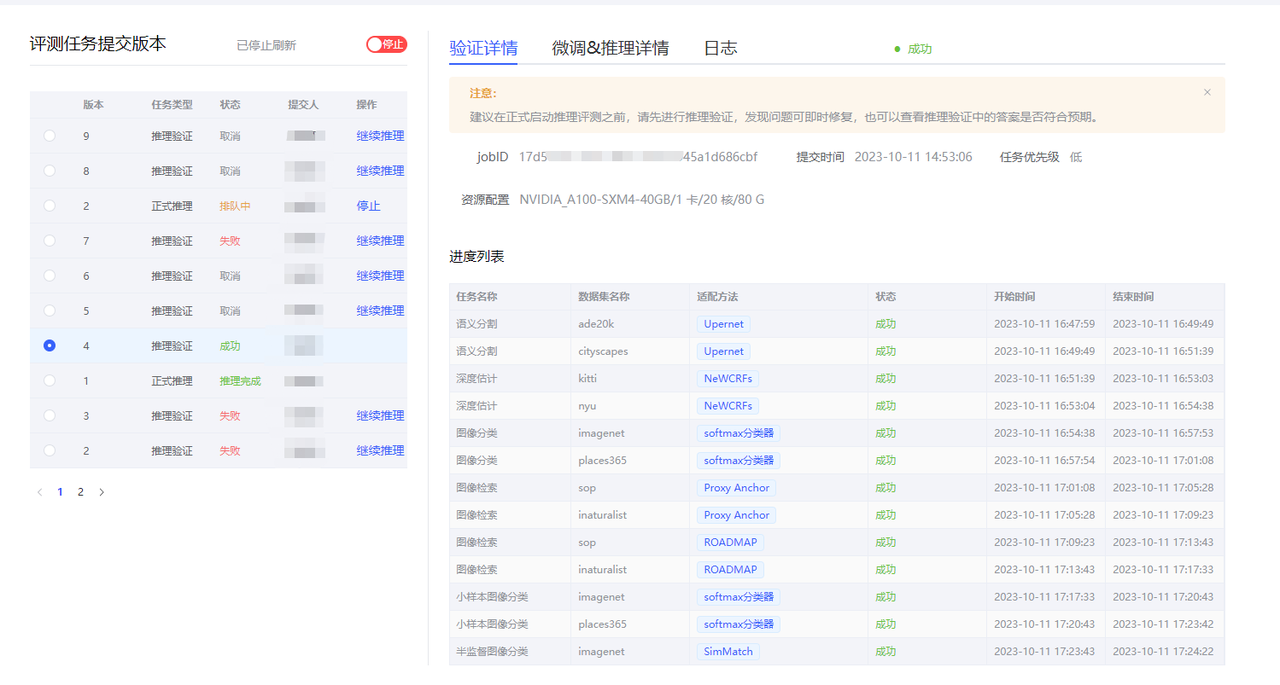
- 微调&推理详情页面
- 主要记录任务名称、数据集名称、状态、评测指标、开始时间、结束时间。
- 日志页面
- 如果某个任务失败,用户可以通过查看日志定位失败原因。
注意:
- 用户每个月只有5次启动正式微调&推理评测的机会。
上传模型与代码规范
开源示例代码请参考github
(1) 安装 FlagEval-Serving
pip install flageval-serving
或
pip install --upgrade flageval-serving参考https://github.com/FlagOpen/FlagEval/tree/master/flageval-serving
(2) 准备模型 & 代码
- 目录结构
需要将模型和代码放在同一个目录下:
开源示例代码请参考github
├── demo
│ ├── meta.json
│ ├── model # 模型相关代码,可以被model_adapter.py调用
| |—— checkpoint.pth
│ └── model_adapter.py模型参数文件: 放在model/checkpoint.pth, 在模型初始化的时候,会通过字符串checkpoint_path传入模型路径。使用者读取之后自行初始化模型。** 注意,模型名和位置在上传的时候必须放在model目录下,并且以checkpoint.pth命名,否则系统会解析出错。**
- model_adapter.py
通过ModelAdapter类的model_init方法,提供获取模型的借口,示例如下:
import os
import sys
# current_dir 为model_adapter.py所在的路径
# 如果需要访问文件系统,可以通过current_dir。如:
# abs_path = os.path.join(current_dir, yourfile) # yourfile为你的文件的相对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
sys.path.append(current_dir)
from model.user_model import get_model # noqa E402
class ModelAdapter:
def model_init(self, checkpoint_path):
model = get_model()
# init weights form checkpoint path
return model- meta.json
模型配置文件,提供模型的基本信息,其中train_batch_size和val_batch_size 参数设置为可选,系统会提供默认值。
{
"model_name": "resnet_demo",
"is_rgb": true,
"output_channels": [256, 512, 1024, 2048], # backbone 输出feature的channel数
"output_dims": [4, 4, 4, 4], # backbone 输出feature的channel维度
"mean": [123.675, 116.28, 103.53], # 输入图像预处理的mean
"std": [58.395, 57.12, 57.375], # 输入图像预处理的std
"tasks": {
"classification": {
"train_batch_size": 128,
"val_batch_size": 128,
"out_indices": [3],
},
"segmentation": { # 分割只支持output_dims为4的feature
"train_batch_size": 8,
"val_batch_size": 8,
"out_indices": [0, 1, 2, 3],
},
"semi_supervised_classification": {
"train_batch_size": 32,
"val_batch_size": 128,
"out_indices": [3],
}
}
}模型上传
在页面点击【上传模型 & 代码】获取 token 然后填入下面的命令中:
flageval-serving upload --token='TOKEN' demo上传速度根据上传主机的出口网络带宽和评测平台服务入口带宽决定,最大速度约12.5MB/s。
BackBone模型格式规范
- BackBone输出格式规范
对于图像分类、图像检索,小样本分类和半监督任务,平台预置了全局平均池化层作为Neck、线性分类器作为Head,需要获得用户BackBone输出特征图的最后一层, 输出特征可以是一个三维的tensor,也可以是四维tensor,需要和meta.json中output_dims保持一致。 对于语义分割、深度估计等密集预测型任务,平台预置了不同的Head,需要获得用户BackBone输出的全部四层特征图。建议用户在BackBone的forward函数中将特征图格式处理为[B,C,H,W](B为Batch_size大小, C为特征维度大小,H、W分别为图片的高和宽),再将四层特征图以tuple格式输出。
SwinTransformer的forward函数示例代码如下:
def forward(self, x):
x, hw_shape = self.patch_embed(x)
if self.use_abs_pos_embed:
x = x + resize_pos_embed(
self.absolute_pos_embed, self.patch_resolution, hw_shape,
self.interpolate_mode, self.num_extra_tokens)
x = self.drop_after_pos(x)
outs = []
for i, stage in enumerate(self.stages):
x, hw_shape = stage(x, hw_shape)
if i in self.out_indices:
norm_layer = getattr(self, f'norm{i}')
out = norm_layer(x)
out = out.view(-1, *hw_shape,stage.out_channels).permute(0, 3, 1,2).contiguous()
outs.append(out)
return tuple(outs)- 适配方法选择注意事项
针对语义分割分割任务,如果用户提交的BackBone采用的是类似Swin或ViT-Adapter的特征金字塔输出形式,请选择UPerNet作为适配方法。如果BackBone采用的是普通ViT输出形式,请选择SETR作为适配方法。 深度估计任务暂时不支持普通ViT架构的评测,仅支持特征金字塔输出形式的模型。对于后者,两个适配方法均可选择。
针对图像分类任务和图像检索任务,所有适配方法均可选择。
模型输入大小:
对于各个任务,模型输入尺寸如下:
- 图像分类、图像检索,小样本分类和半监督:224*224
- 深度估计:
- KITTI Eigen split数据集:352*1120
- NYU-Depth V2数据集:480*640
- 语义分割:512*512
Multimodal领域模型评测
目前Flageval平台支持用户上传Multimodal领域的直接推理模型(无需Finetune)进行推理评测。
创建评测
用户在评测任务列表页面,点击【创建评测】,弹出【创建评测】对话框,填写相关参数点击提交,跳转到模型评测实例详情页面。
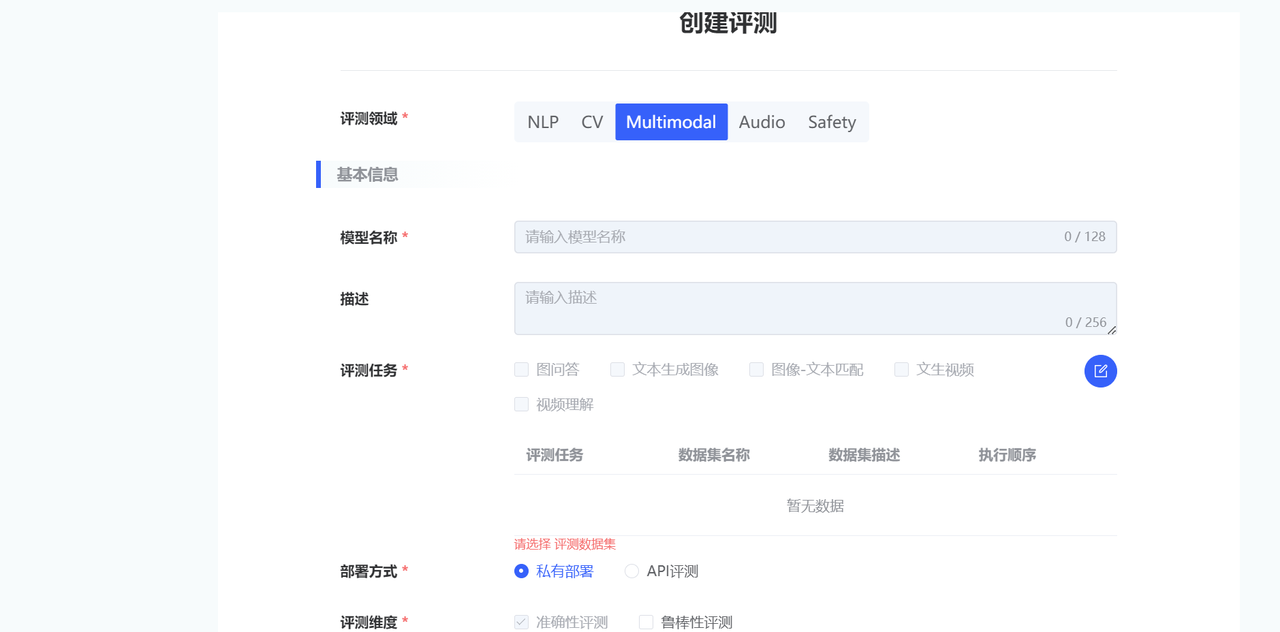
| 参数类别 | 参数名称 | 参数描述 |
|---|---|---|
| 基本信息 | 评测领域 |
|
| 模型名称 |
| |
| 描述 |
| |
| 评测任务 | 选择评测任务。必填,多选 | |
| 部署方式 |
| |
| 评测维度 | 必填 可选是否进行鲁棒性评测,准确性评测为内置选项 |
根据基本信息中部署方式的不同,需填写不同的表单: 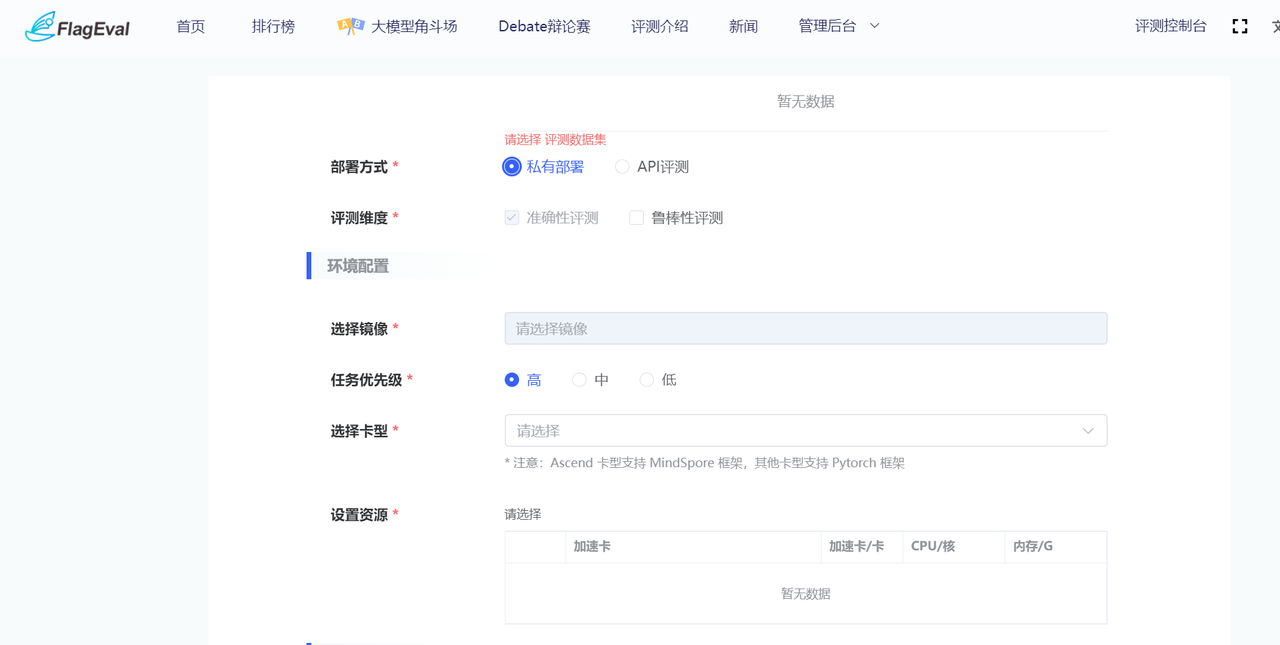
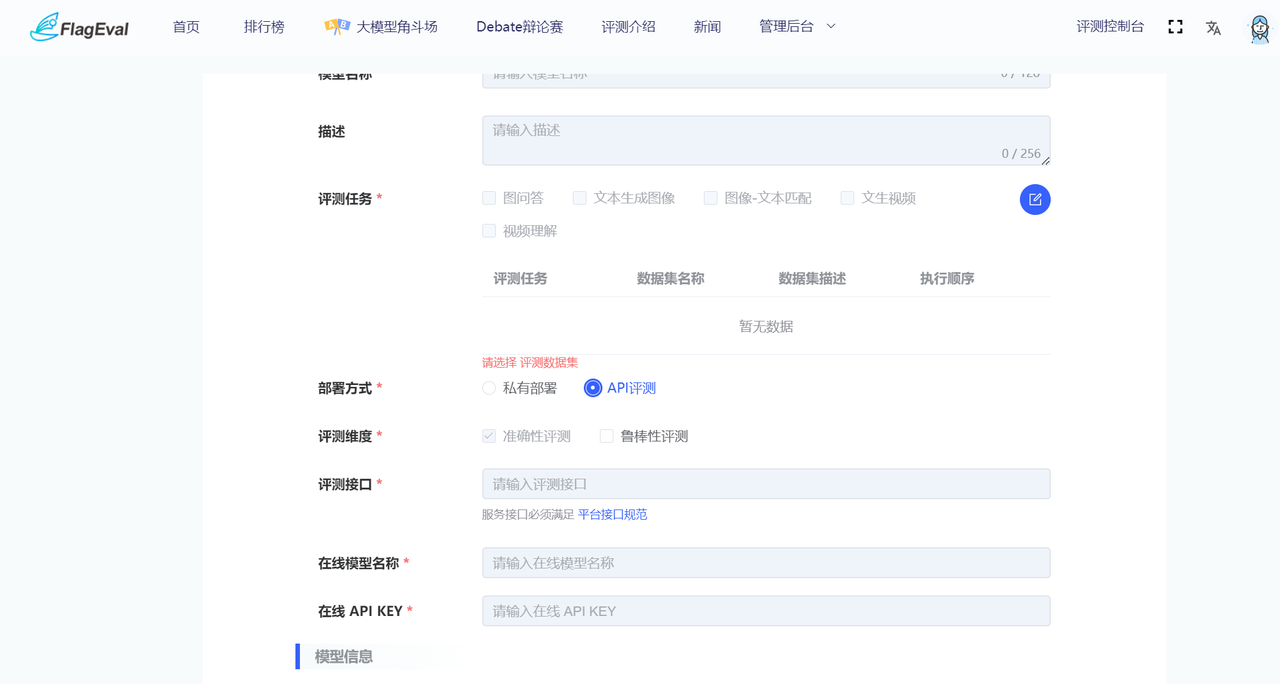
| 部署方式 | 参数类别 | 参数名称 | 参数描述 | 图例 |
|---|---|---|---|---|
| 私有部署 | 环境配置 | 选择镜像 |
| |
| 任务优先级 | 必填 有高中低三个选项 | |||
| 选择卡型 |
| |||
| 设置资源 |
| |||
| API评测 | 基本信息 | 评测接口 | 必填 需符合平台接口规范 | |
| 在线模型名称 | 选填 | |||
| 在线 API KEY | 选填 |
除上述信息外,还需填写模型相关信息: 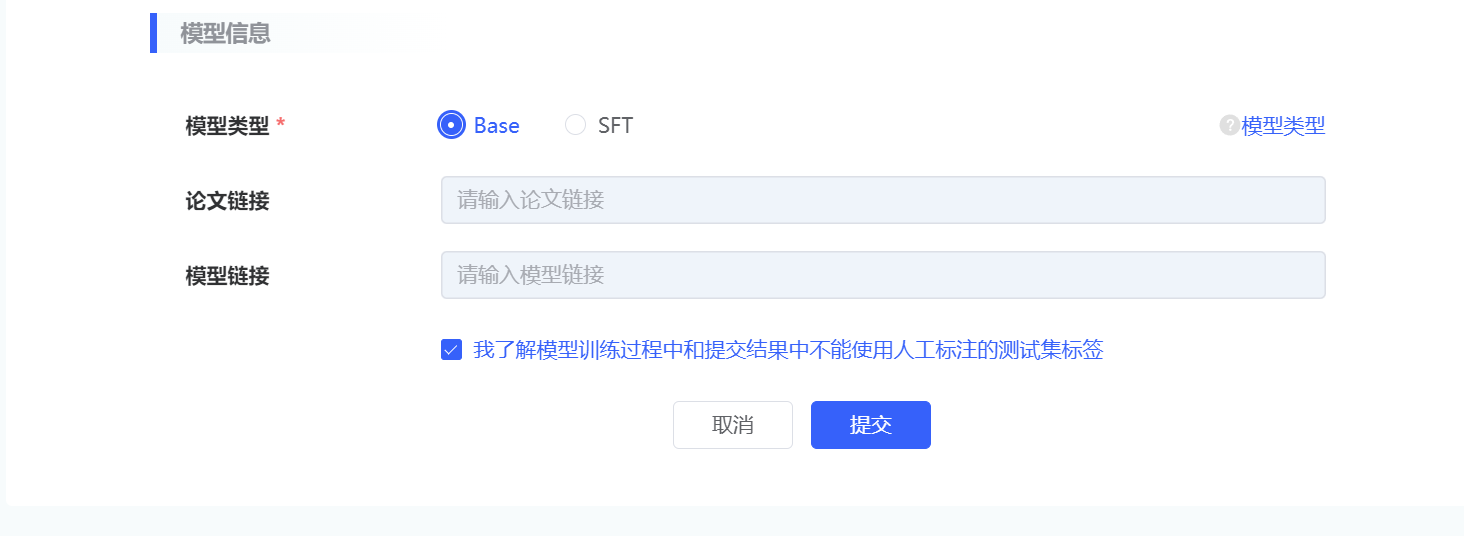
| 参数类别 | 参数名称 | 参数描述 |
|---|---|---|
| 模型信息 | 模型类型 |
|
| 论文链接 | ||
| 模型链接 |
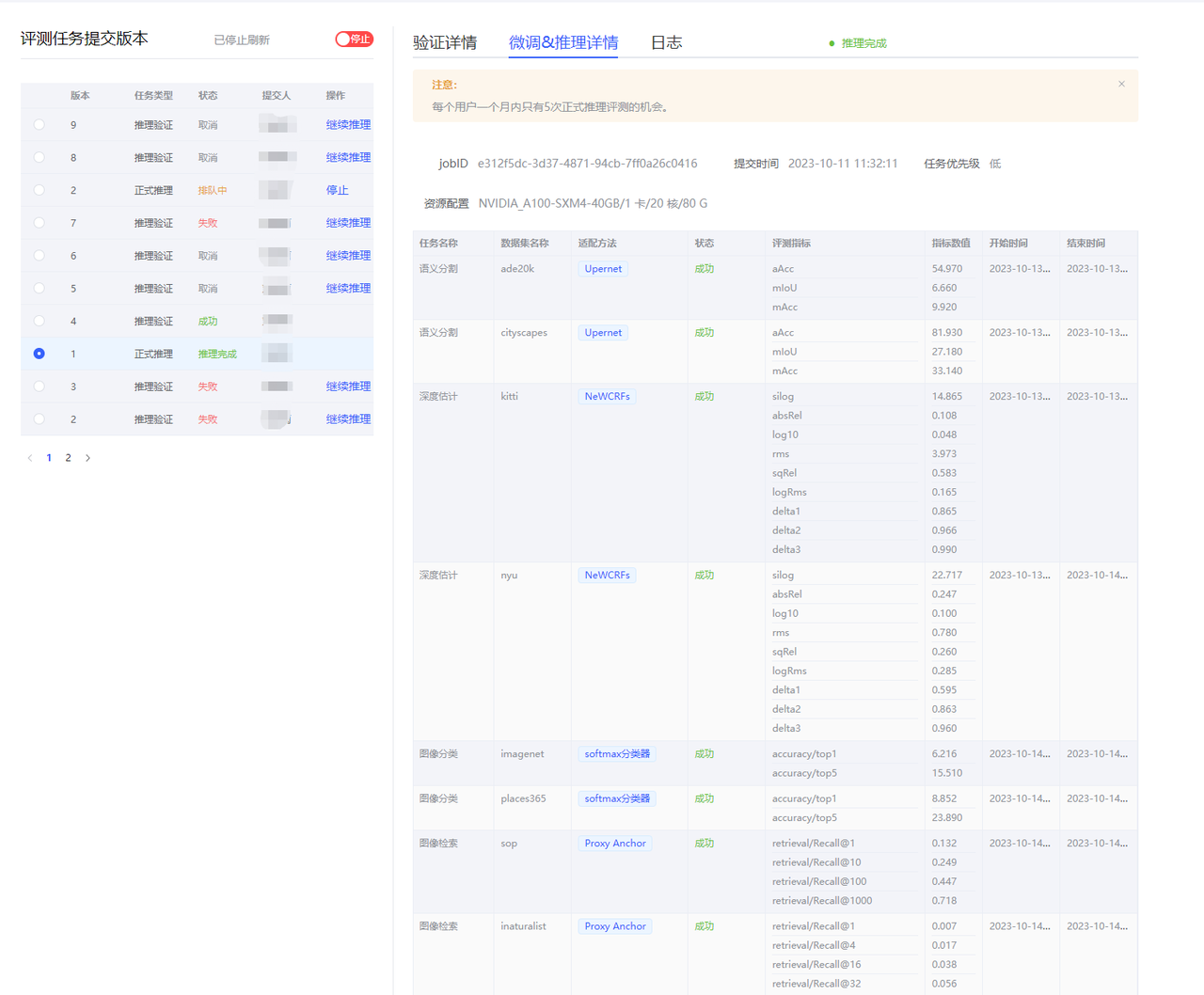
用户提交评测实例,跳转到评测实例详情页面,分为上、左下、右下三部分: 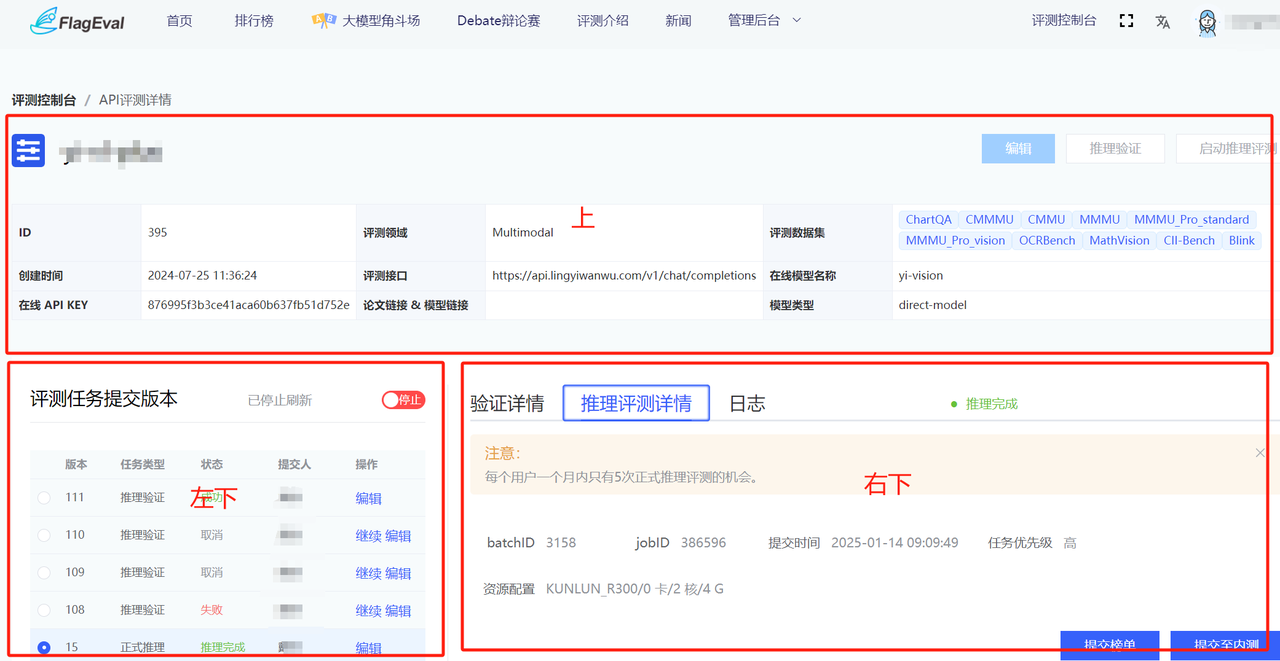
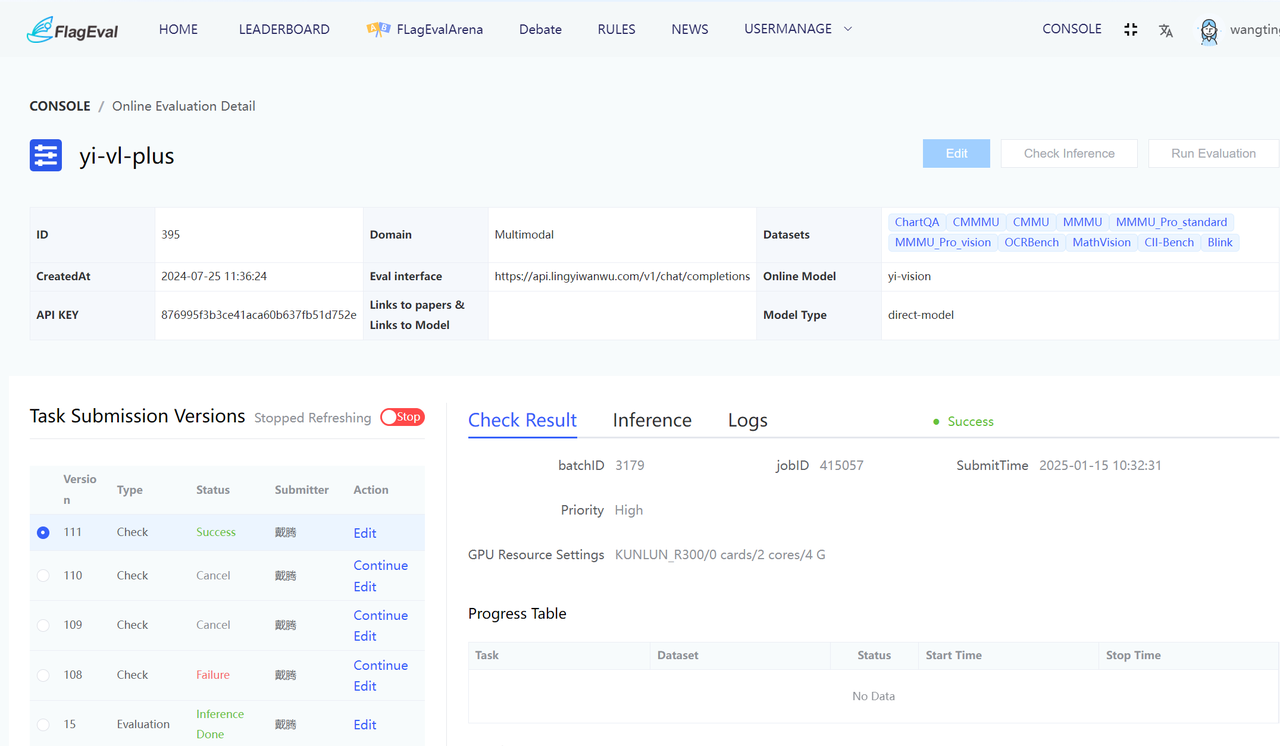
上半部分:
显示用户【创建评测】时的具体参数。
用户操作有:【编辑】、【上传模型&代码】、【推理验证】、【启动推理评测】。
【编辑】操作:除模型名称和评测领域之外都允许编辑。
【上传模型&代码】操作:弹出上传模型和代码的引导页面。
【推理验证】操作:
- 平台从测试数据中随机抽取1——3条组成推理验证的数据,方便用户快速验证自己的模型与服务能否运行。
- 建议在正式启动推理评测之前,请先进行推理验证,发现问题可即时修复,也可以查看推理验证中的答案是否符合预期。
【启动推理评测】操作:用户验证模型与服务没问题后,可以点击启动推理评测。
评测任务结束时会给用户发送邮件通知。- 目前仅支持单机推理评测。
左下部分:
- 展示用户启动推理和推理验证的历次版本。
- 展示参数有:版本、任务类型、状态、提交人、操作。
- 任务类型有:推理验证&正式推理。
- 【停止】操作:点击该操作,推理过程结束。
右下部分包括:验证详情页面、推理评测详情页面、日志页面。
- 验证详情页面:数据集进度展示(任务名称、数据集名称、状态)以及验证数据结果;
- 推理评测详情页面
- 主要记录任务名称、数据集名称、状态、评测指标、开始时间、结束时间。
日志页面
- 如果某个任务失败,用户可以通过查看日志定位失败原因。
注意:
- 用户每个月只有5次正式启动推理评测的机会。
上传模型与代码规范
开源示例代码请参考github
(1) 安装 FlagEval-Serving
pip install flageval-serving
或
pip install --upgrade flageval-serving参考https://github.com/FlagOpen/FlagEval/tree/master/flageval-serving
(2) 准备模型 & 代码
- 目录结构
使用flageval-serving上传的文件中,必要的两个文件如下,文件名必须使用checkpoint.pth和run.sh,存放在上传文件的根目录下:
example_model
├── checkpoint.pth # 模型初始化需要用的的权重文件,需要用户的代码自行载入,解析。
├── run.sh
└── .... # 其它的用户文件checkpoint.pth
模型初始化需要用的的权重文件,需要用户的代码自行载入,解析。
run.sh
需要接受3个命令行参数,分别表示:task_name, server_ip, server_port, 第一个参数是任务名(retrieval, vqa, t2i),后两个参数是数据服务器ip和端口。run.sh内部没有限制,能确保程序运行,并输出符合预期的结果即可。
bash run.sh $task_name $server_ip $server_port- 输出格式
vqa任务
对于每个数据集,输出一个list,list的每个元素为 {"question_id": int, "answer": str} 格式,表示对应id的问题和模型给出的答案,具体如下
[
{"question_id": str, "answer": str},
....
]存储为json格式,路径为 "$output_dir"/"$dataset_name".json
retrieval任务
对于每个数据集,输出一个n*m的矩阵,表示第n张图片和第m个句子的相似度,使用np.ndarray格式,存储路径为 "$output_dir"/"$dataset_name".npy
t2i任务
对于每个数据集,输出n张图片到"$output_dir"目录下,存储为png格式,图片命名为 ${prompt_id}.png 同时生成另一个文件"$output_dir/output_info.json" ,内容为一个json的list,每个元素需要包含 "id"(当前的question_id)和 "image"(生成的图片的名字,即相对于$output_dir的路径),例如:
[
{
"id": "0",
"image": "0.png"
},
{
"id": "1",
"image": "1.png"
}
....
]- 数据接口
用户需要通过http请求,获得数据,模型的路径,以及数据集相关信息。主要接口如下:
- io_info:存储用户输出的目录和模型文件路径
http://{server_ip}:{server_port}/io_info
{
'checkpoint_path': 'model checkpoint path',
'output_dir': 'output dir'
}- meta_info:数据集的meta信息
http://{server_ip}:{server_port}/meta_info
# 对于vqa任务
{
'length': 图片数量,
'name': 数据集名称,
'type': 'vqa'
}
# 对于retrieval
{
'name': 数据集名称,
'image_number': 图片数量,
'caption_number': 文本数量,
'type': 'retrieval'
}- get_data:获取数据的接口
- vqa任务
# index的取值范围为 [0, 图片数量)
http://{server_ip}:{server_port}/get_data?index={index}
{
"img_path": 一个list,每个元素为图片绝对路径,可以使用PIL,cv2等直接读取,
"question": 问题,是一个str,图片位置用<image1> <image2>
"question_id": question_id,
'type': 类型为str,是题目的类型
}
其中type可以为:
multiple-choice (单选题)
multiple-response (多选题)
fill-in-the-blank (填空题)
short-answer (简答题)
yes-no (判断题)
# 下面是一个实际的例子:
{'img_path': ['/share/projset/mmdataset/MathVista/images/20.jpg'],
'question': '<image 1>Hint: Please answer the question and provide the correct option letter, e.g., A, B, C, D, at the end.\nQuestion: Is the sum of smallest two bar is greater then the largest bar?\nChoices:\n(A) Yes\n(B) No',
'question_id': '20',
'type': 'multiple-choice'
}- retrieval任务
# 读取图片,index的取值范围为 [0, 图片数量)
http://{server_ip}:{server_port}/get_data?index={index}&type=img
{
"img_path": 图片绝对路径,可以使用PIL,cv2等直接读取,
}
# 读取文本,index的取值范围为 [0, 文本数量)
http://{server_ip}:{server_port}/get_data?index={index}&type=text
{
"caption": 一个文本
}- t2i任务
# index的取值范围为 [0, prompt数量)
http://{server_ip}:{server_port}/get_data?index={index}
{
"prompt": 一段描述图像的文本,是一个str,
"id": prompt id,int格式
}- 使用样例: 获取模型checkpoint存储地址以及输出目录。
url = f"{server_ip}:{server_port}/io_info"
data = requests.get(url).json()
checkpoint_path = data['checkpoint_path']
output_dir = data['output_dir']- 数据相关
# 获取vqa数据
url = f"{server_ip}:{server_port}/get_data?index=12"
data = requests.get(url).json()
# 获取retrieval文本
url = f"{server_ip}:{server_port}/get_data?index=10&type=text"
data = requests.get(url).json()
# 获取retrieval图像
url = f"{server_ip}:{server_port}/get_data?index=10&type=img"
data = requests.get(url).json()模型上传
在页面点击【上传模型 & 代码】获取 token 然后填入下面的命令中:
flageval-serving upload --token='TOKEN' demo上传速度根据上传主机的出口网络带宽和评测平台服务入口带宽决定,最大速度约12.5MB/s。
flageval-serving的更多使用教程请参考章节
Audio语音领域模型评测
目前Flageval平台支持用户上传Audio语音领域的backbone预训练模型,支持backbone模型冻结参数后在不同任务、数据集下进行finetune生成下游任务模型,并在相应的测试数据集上进行推理评测,得到模型在该数据集上的评测指标。
创建评测
用户在评测任务列表页面,点击【创建评测】,弹出【创建评测】对话框,填写相关参数点击提交,跳转到模型评测实例详情页面。 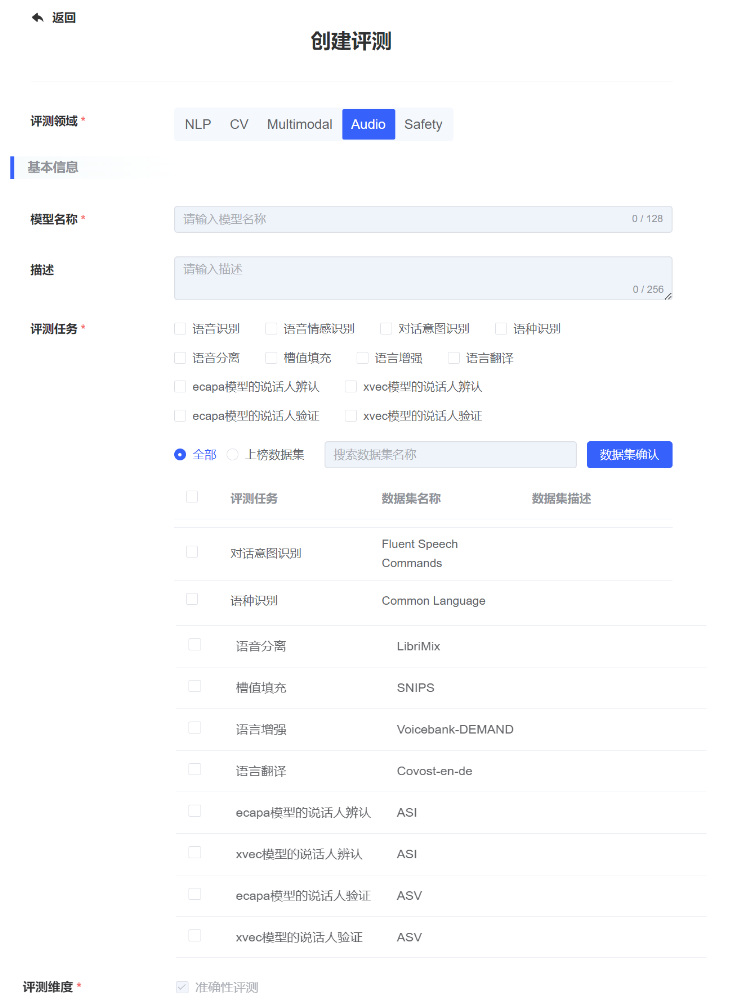
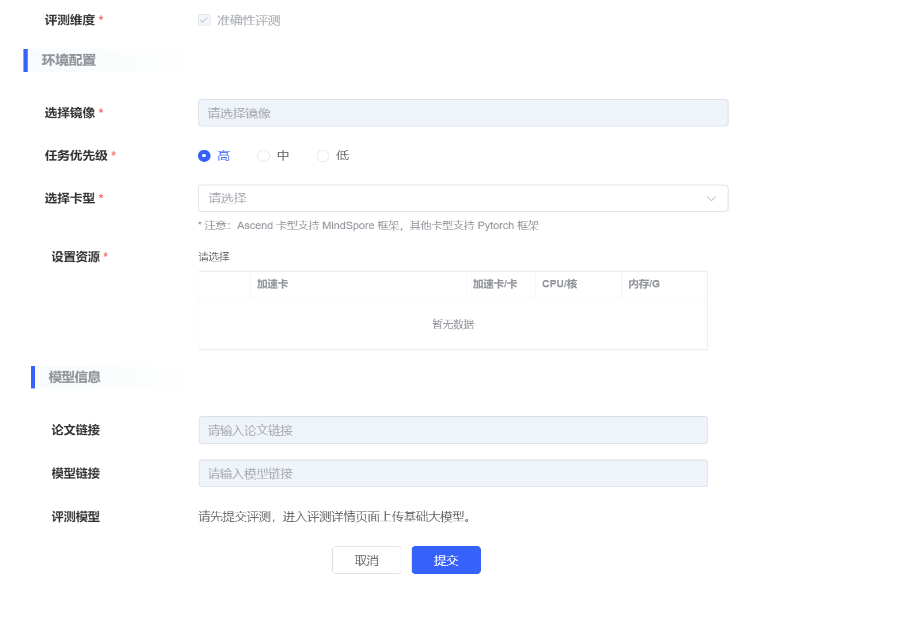
| 参数类别 | 参数名称 | 参数描述 |
|---|---|---|
| 基本信息 | 评测领域 |
|
| 模型名称 |
| |
| 描述 |
| |
| 评测任务 | ||
| 评测维度 | 默认进行准确性评测 | |
| 环境配置 | 选择镜像 |
|
| 任务优先级 | 必填 有高中低三个选项 | |
| 选择卡型 |
| |
| 设置资源 |
| |
| 模型信息 | 论文链接 | |
| 模型链接 |
用户提交评测实例,跳转到评测实例详情页面,分为上、左下、右下三部分:
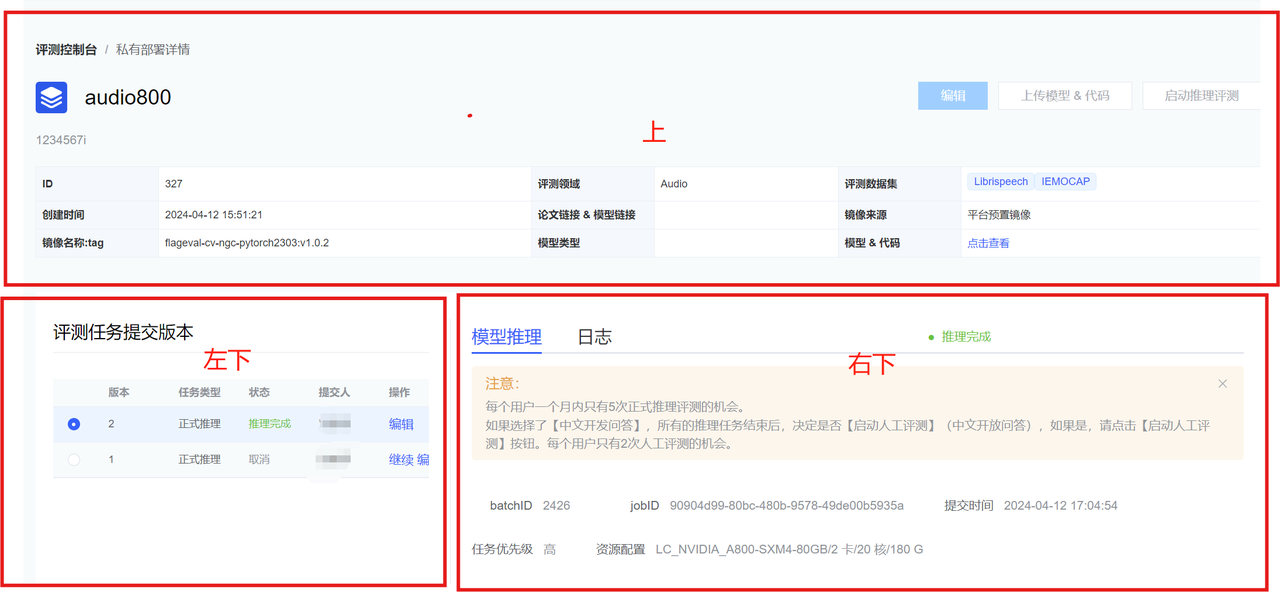
上半部分:
- 显示用户【创建评测】时的具体参数。
- 用户操作有:【编辑】、【上传模型&代码】、【启动推理评测】。
- 【编辑】操作:除模型名称和评测领域之外都允许编辑。
- 【上传模型&代码】操作:弹出上传模型和代码的引导页面。
- 【启动推理评测】操作:用户验证模型与服务没问题后,可以点击启动推理评测。
评测任务结束时会给用户发送邮件通知。- 目前仅支持单机推理评测。
- 左下部分:
- 展示用户启动推理和推理验证的历次版本。
- 展示参数有:版本、任务类型、状态、提交人、操作。
- 任务类型有:推理验证&正式推理。
- 【停止】操作:点击该操作,推理过程结束。
- 右下部分包括:验证详情页面、推理评测详情页面、日志页面。
- 验证详情页面:数据集进度展示(任务名称、数据集名称、状态)以及验证数据结果;
- 推理评测详情页面
- 主要记录任务名称、数据集名称、状态、评测指标、开始时间、结束时间。
- 日志页面
- 如果某个任务失败,用户可以通过查看日志定位失败原因。
注意:
- 用户每个月只有5次正式启动推理评测的机会。
上传模型与代码规范
开源示例代码请参考github
(1) 安装 FlagEval-Serving
pip install flageval-serving
或
pip install --upgrade flageval-serving参考https://github.com/FlagOpen/FlagEval/tree/master/flageval-serving
(2) 准备模型 & 代码
目前平台仅支持BackBone模型进行finetune后进行推理评测,下面是关于添加上游模型(BackBone)及其所需组件的步骤:
首先,上游模型文件夹组织结构 (Folder Structure) 如下,平台提供了示例结构与代码,详情请参考具体的代码:
upstream/example_model
├── model.py
├── convert.py
└── ModelWrapper.py在 model.py 中, 需要实现两个数据类: ExamplePretrainingConfig 和 exampleconfig 。分别初始化预训练参数配置和模型结构,具体要求如下:
ExamplePretrainingConfig: 使用该类来配置预训练参数,例如采样率,输入数据的最大最小长度等,例如upstream/wav2vec2/wa2vec2_model.py/AudioPretrainingConfig。ExampleConfig: : 该类配置自定义模型的架构参数,例如编码器层的数量、各层网络输入输出的维度、dropout的大小等。
此外,model.py 应该实现 ExampleModel 类,即定义模型结构,请尽量使用pytorch实现,避免额外的依赖。
@dataclass
class ExamplePretrainingConfig:
sample_rate: int = field(
default=16_000,
metadata={
"help": "target sample rate. audio files will be up/down sampled to this rate"
},
)
max_sample_size: Optional[int] = field(
default=None, metadata={"help": "max sample size to crop to for batching"}
)
min_sample_size: Optional[int] = field(
default=None, metadata={"help": "min sample size to skip small examples"}
)
pass
@dataclass
class ExampleConfig:
encoder_layers: int = field(
default=12, metadata={"help": "num encoder layers in the transformer"}
)
pass
class ExampleModel(nn.Module):
def __init__(self, config):
super(ExampleModel, self).__init__()
pass
def forward(self, wavs, padding_mask):
pass
return features, mask- convert.py
convert.py 文件用于将checkpoint转换为与我们项目兼容的格式。转换后的检查点结构应该如下所示 。
{
"task_cfg": , # Configuration for ExamplePretrainingConfig
"model_cfg", # Configuration for ExampleConfig
"model_weight", # Load model weights using model.load_state_dict(ckpt_state["model_weight"])
}用户可以使用 convert.py 中提供的 load_converted_model 函数来验证转换后模型的兼容性。
def load_converted_model(ckpt: str):
ckpt_state = torch.load(ckpt, map_location="cpu")
for required_key in ["task_cfg", "model_cfg", "model_weight"]:
if required_key not in ckpt_state:
raise ValueError(
f"{ckpt} is not a valid checkpoint since the required key: {required_key} is missing"
)
task_cfg = merge_with_parent(ExamplePretrainingConfig, ckpt_state["task_cfg"])
model_cfg = merge_with_parent(ExampleConfig, ckpt_state["model_cfg"])
model = ExampleModel(model_cfg)
model.load_state_dict(ckpt_state["model_weight"])
return model, task_cfg- ModelWrapper.py
ModelWrapper.py 作为平台上游模型的统一接口。该文件中需要创建一个类,例如 MyModel ,结构如下 :
class MyModel(nn.Module):
def __init__(self, load_type, **kwargs):
super(MyModel, self).__init__()
# 在这里初始化并且载入你的模型
# to get config and .pt file
ckpt_state = torch.load(ckpt, map_location="cpu")
self.task_cfg = merge_with_parent(ExamplePretrainingConfig, ckpt_state["task_cfg"])
self.model_cfg = merge_with_parent(ExamplePretrainingConfig, ckpt_state["model_cfg"])
self.model = ExampleModel(self.model_cfg)
self.model.load_state_dict(ckpt_state["model_weight"])
def forward(self, wavs, padding_mask=None):
device = wavs[0].device
# 实现forward结构,并且返回feature和feature_mask。维度均为(B*L*D)
def get_output_dim(self):
# 定义你的模型的输出维度D,以768为例。
return 768Safety领域模型评测
目前平台支持用户通过API调用的方式进行安全领域评测,用户共有5大类测试数据集可选择,创建评测任务后可在相应测试数据集上进行推理评测(不支持推理验证),得到模型在该数据集上的评测指标。
创建评测
用户在评测任务列表页面,点击【创建评测】,弹出【创建评测】对话框,填写相关参数点击提交,跳转到模型评测实例详情页面。
| 参数类别 | 参数名称 | 参数描述 |
|---|---|---|
| 基本信息 | 评测领域 |
|
| 模型名称 |
| |
| 描述 |
| |
| 评测数据集 | 选择评测任务。必填,多选 目前数据集按照TC260分为5大类:
| |
| 部署方式 | 默认以API评测的形式部署 | |
| 评测维度 | 默认进行准确性评测 | |
| 评测接口 | 必填 需符合平台接口规范 | |
| 在线模型名称 | 必填 | |
| 模型信息 | 在线 API KEY | 必填 |
| 论文链接 / 模型链接 | 选填 |
flageval-serving工具详细教程
用户可以通过安装 FlagEval-Serving工具上传模型、代码、数据等待评测文件,也可以通过该工具进行本地测试。 操作流程如下: (1) 安装 flageval-serving Markdown
pip install flageval-serving
或
pip install --upgrade flageval-serving工具开源: https://github.com/FlagOpen/FlagEval/tree/master/flageval-serving (2) 准备代码 & 模型 & 数据 不同领域的评测需要不同的目录结构和接口规范,请参考各个领域的要求准备待上传文档即可。NLP领域的模型评测还可以支持本地模型调试,请参考NLP领域的操作流程规范。 (3) 常用命令
- 用户上传更新文件需要唯一的 token 进行确认。
- 评测详情页面点击【上传模型 & 代码】获取 token 用于初始化创建评测目录。
- 若用户在当前版本追加文件,用cp命令,且用文件列表页面的 token 进行更新。
- 注意:下面命令中都是英文单引号。
(3) 文件上传 在页面点击【上传模型 & 代码】获取 token 然后填入下面的命令中:
flageval-serving upload --token='TOKEN' demo上传速度根据上传主机的出口网络带宽和评测平台服务入口带宽决定,最大速度约12.5MB/s。
镜像管理
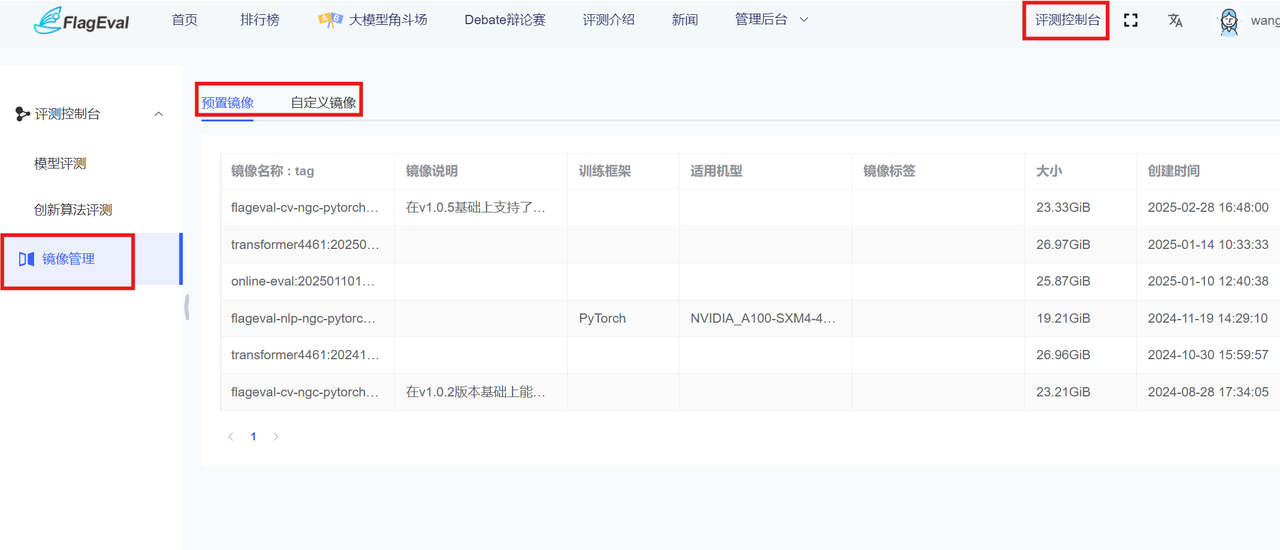
用户点击【评测管理/镜像管理】可以查看平台的预置镜像和自定义镜像列表(自己导入镜像的管理列表)。
- 预置镜像:Flageval平台为用户提供了各个领域的包括各种评测依赖的预置镜像供用户直接使用。用户可以根据镜像名称、镜像描述、训练框架、适配机型和标签,确定镜像的详细信息。
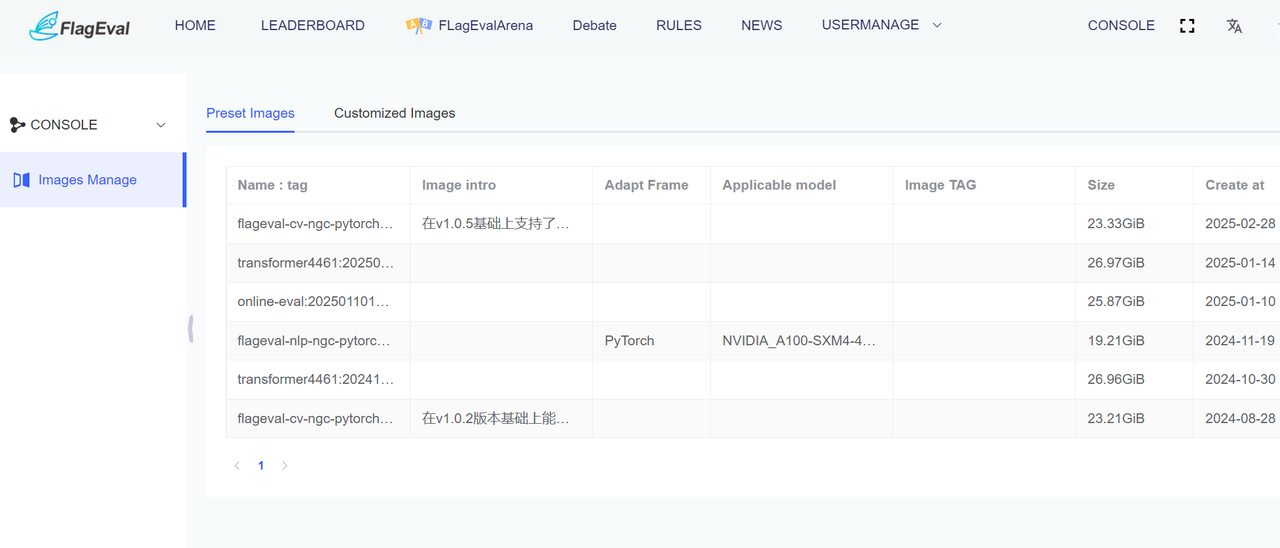
- 自定义镜像:Flageval平台支持用户导入自己构建好的镜像用于评测任务。
目前平台仅支持用户已有镜像导入,不支持利用dockerfile在平台构建镜像,用户填写的 dockerfile 仅用于平台审核人员审查镜像。
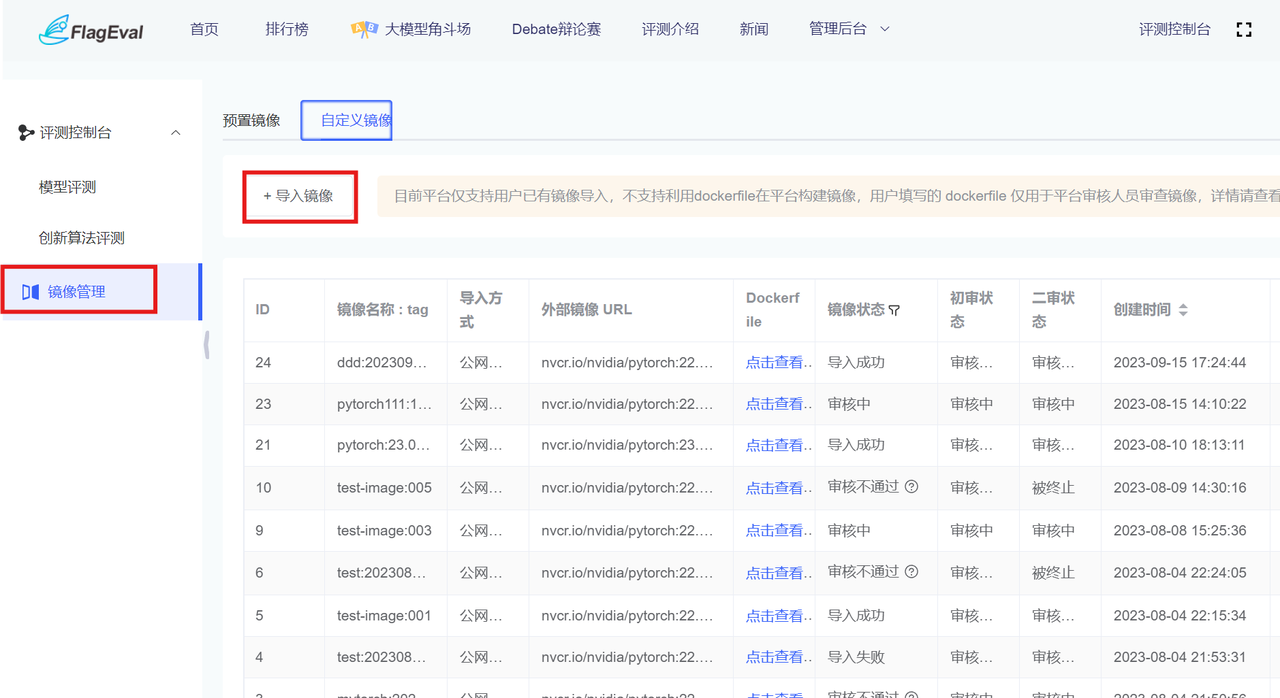 用户点击【+导入镜像】,弹出【+导入镜像】对话框,填写相应参数,点击提交:
用户点击【+导入镜像】,弹出【+导入镜像】对话框,填写相应参数,点击提交: 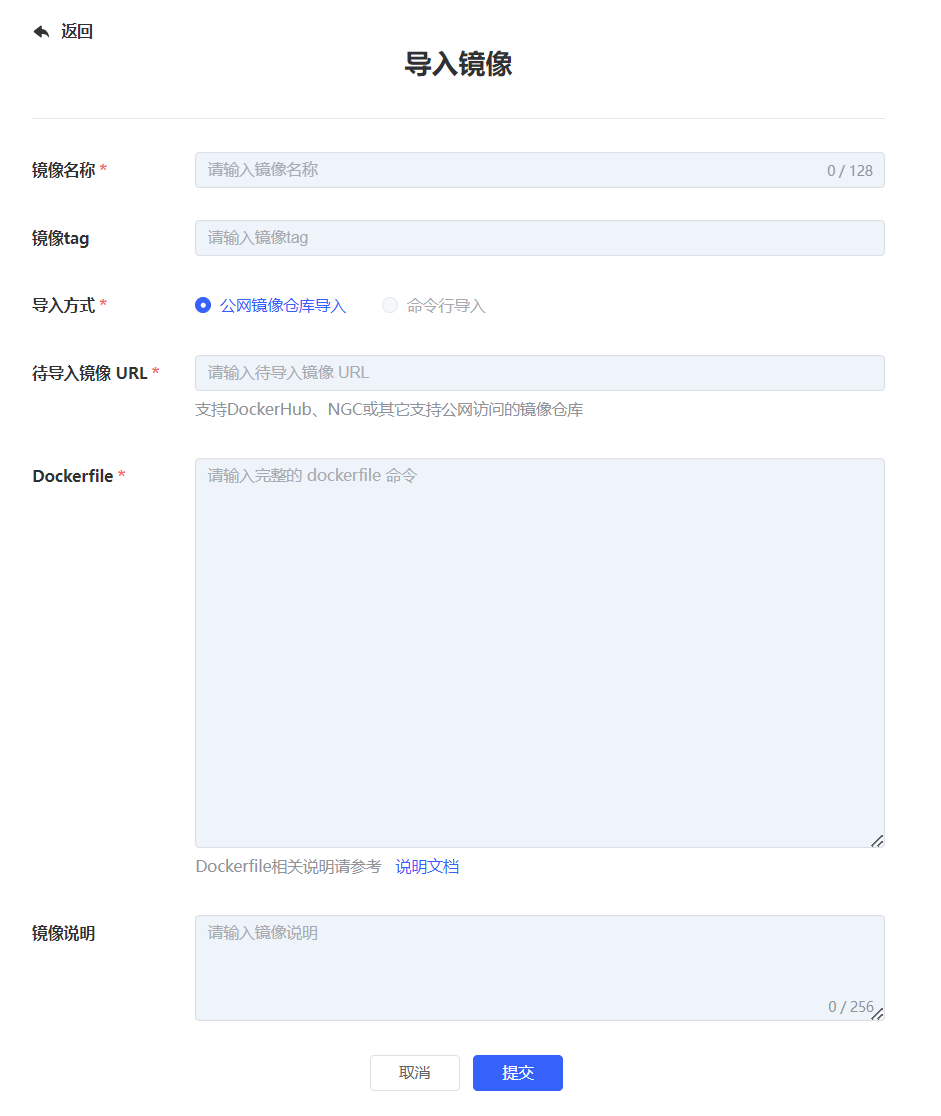
| 参数 | 参数解释 |
|---|---|
| 镜像名称 | 填写镜像名称,名称长度为 3~128 位,支持小写字母、数字、中间连字符 -、点 .,以小写字母开头,以小写字母、数字为结尾。必填 |
| 镜像 tag | 请填写镜像 tag,缺省默认为时间戳,禁止使用 latest 关键词。选填 |
| 导入方式 | 目前只支持公网镜像仓库导入 |
| 待导入镜像 URL | 请填写待导入镜像地址。必填,支持 DockerHub、NGC 或其它支持公网访问的镜像仓库 |
| Dockerfile | 必填;供审核人员审核查看。注释:Dockerfile 相关说明请参考[说明文档] |
| 镜像说明 | 选填,长度 0~256 个字符,支持中文 |
用户点击【提交】后,返回【镜像管理】列表页面。等待平台管理员审核导入镜像,审核通过后,会直接将该镜像导入到平台的镜像仓库,用户即可在创建评测时使用导入的镜像。
如果审核不通过,请查看审核不通过的原因,根据平台规范修改导入镜像的地址或者Dockerfile,重新导入。
审核通过、导入成功、审核不通过都会给用户发送邮件通知,如果长时间没有状态反馈,请联系平台管理员反馈问题。
基于 Dockerfile 自定义构建镜像
Dockerfile 是一种用于构建镜像的文本文件,其中包含了一系列的镜像构建指令和参数,Docker通过docker build执行Dockerfile中的一系列指令自动构建镜像。关于 Dockerfile 的语法详见其官方文档,同时可以参考快速入门手册。
用户进行离线评测时,如果平台提供的镜像不满足用户需求,用户可以提供 Dockerfile,平台帮助生成可用的镜像 。
常用关键词如下:
| 命令关键词 | 含义 |
|---|---|
| FORM | 基础镜像,表明当前镜像是基于哪个镜像的。Dockerfile第一行必须为From命令,选择的基础镜像必须是安全可信镜像,建议优先选择平台预置镜像以及官方提供的镜像。 |
| RUN | 容器构建时需要用到的命令。 |
| ENV | 用来构建镜像过程中设置环境变量 (ENV MY_PATH="/usr/mytest"),持久化至容器中,容器启动后可以直接获取。 |
| ARG | 构建时使用的临时变量 (ARG TMP="mytemp"),仅供构建期间使用,容器启动后无法获取。 |
注意
- ENV中的以下环境变量是容器给出的,不允许修改。
- NVIDIA_, HOSTNAME, KUBERNETES_, RANK, MASTER_, AIRS_, CUDA_, NCCL_, PADDLE_* Dockerfile使用建议:
- From 选择的基础镜像必须为平台提供的候选镜像。
- 减少镜像层数(layers),RUN, COPY 等指令会在 build 时产生对应的 layer,因此建议使用&&来连接多个命令。
下面命令行创建了2层镜像:
RUN apt-get install -y openssh-server
RUN mkdir -p /run/sshd修改为以下命令行后,2层变1层,可以有效减小镜像大小。
RUN apt-get install -y openssh-server \
&& mkdir -p /run/sshd- 当指令比较长时, 建议分行,且建议多行参数进行排序。
- 可以将需要安装的多个包按字母进行排序,避免重复安装,同时提高代码可读性,如下示例。
RUN apt-get update && apt-get install -y \
bzr \
cvs \
git \
mercurial \
subversion \
&& rm -rf /var/lib/apt/lists/*- 通过清理缓存减小镜像大小。
- 如 RUN apt-get -y *** && apt-get clean。
- 安装python包的时候建议使用 RUN pip install --no-cache-dir -i {指定源地址} {package} 来安装。
- 安装conda相关包的时候建议后面跟上clean命令,不同参数表示的含义为:
- RUN conda clean -p (删除没用的包)
- RUN conda clean -t (删除tar包)
- RUN conda clean -y --all (删除所有安装包和缓存文件)
- 通过 docker build 命令的 --no-cache=true 选项,不使用缓存。
- Dockerfile示例:该示例对应平台的镜像是flageval-nlp-ngc-pytorch2303:v1.0,该镜像已满足YuLan-Chat-2-13b、llama、chatglm2-6b、Baichuan-13B-Chat等主流模型的环境需求。如果该镜像满足需求,建议选择使用
FROM nvcr.io/nvidia/pytorch:23.03-py3
RUN apt-get update
RUN apt-get install -y openssh-server && mkdir -p /run/sshd
# 下列版本为建议版本,用户可根据自己模型的需求来安装, 建议transformer的包和其他包分开安装
RUN pip install --no-cache-dir transformer-engine==0.6.0 transformers==4.31.0 transformers-stream-generator==0.0.4
RUN pip install --no-cache-dir sentencepiece==0.1.98 accelerate==0.21.0 colorama==0.4.6 cpm_kernels==1.0.11 streamlit==1.25.0 fairscale==0.4.13
# Qwen
RUN pip install tiktoken平台镜像审核原则
平台目前主要提供英伟达卡系列显卡,建议使用英伟达官方提供的镜像(nvcr.io/nvidia)作为基础镜像。如使用pytorch框架,建议选用nvcr.io/nvidia下的pytorch镜像作为FROM来源,对于其他来源的镜像,如审核人员判断存在安全风险则审核不通过。
如果使用其他品牌的显卡,可先使用平台提供的镜像进行测试,如不满足需求,请联系运维人员(flageval@baai.ac.cn)进行处理。
对dockerfile有以下几点建议:
- Dockerfile 第一行必须为 FROM 命令,指明基础镜像来源,否则驳回镜像导入请求;
- 镜像中需要平台与后端k8s集群进行通讯,需要安装ssh;
- 在dockerfile中尽量不要出现COPY、ADD等命令,如果使用这两个命令需加上注释说明其内容;
- 根据镜像的安全性要求,RUN中不能有wget、curl等下载未知包的操作;
- 用户需使用系统自带的命令安装系统官方包;
- 填写的导入镜像URL需要能使用docker命令下载;
- 在安装包的时候尽量指定使用国内的源。
平台对镜像大小限制:40Gi。
Dockerfile示例:该示例对应平台的镜像是flageval-nlp-ngc-pytorch2303:v1.0,该镜像已满足YuLan-Chat-2-13b、llama、chatglm2-6b、Baichuan-13B-Chat等主流模型的环境需求。如果该镜像满足需求,建议选择使用。
FROM nvcr.io/nvidia/pytorch:23.03-py3
RUN apt-get update
RUN apt-get install -y openssh-server && mkdir -p /run/sshd
# 下列版本为建议版本,用户可根据自己模型的需求来安装, 建议transformer的包和其他包分开安装
RUN pip install --no-cache-dir transformer-engine==0.6.0 transformers==4.31.0 transformers-stream-generator==0.0.4
RUN pip install --no-cache-dir sentencepiece==0.1.98 accelerate==0.21.0 colorama==0.4.6 cpm_kernels==1.0.11 streamlit==1.25.0 fairscale==0.4.13
# Qwen
RUN pip install tiktoken- 镜像安全必备要求
- 禁止镜像存在公开可利用的且已公布修复方案的高危安全漏洞。
- 禁止使用官方已停止维护的发行版本进行镜像。
- 禁止镜像默认安装任何病毒、木马、后门、挖矿以及挂机等恶意程序。
- 禁止使用任何盗版或者破解版程序。
- 禁止使用包含一切其他可能会危害平台安全的任意程序。
注意:为确保服务镜像的安全性和合规性,我们会定期对已上架的镜像进行扫描。如果发现镜像存在安全漏洞或违规行为,我们将下架该镜像,并追究上传者的法律责任。感谢您对我们平台的支持和配合。
评测结果查看
- NLP领域评测结果查看
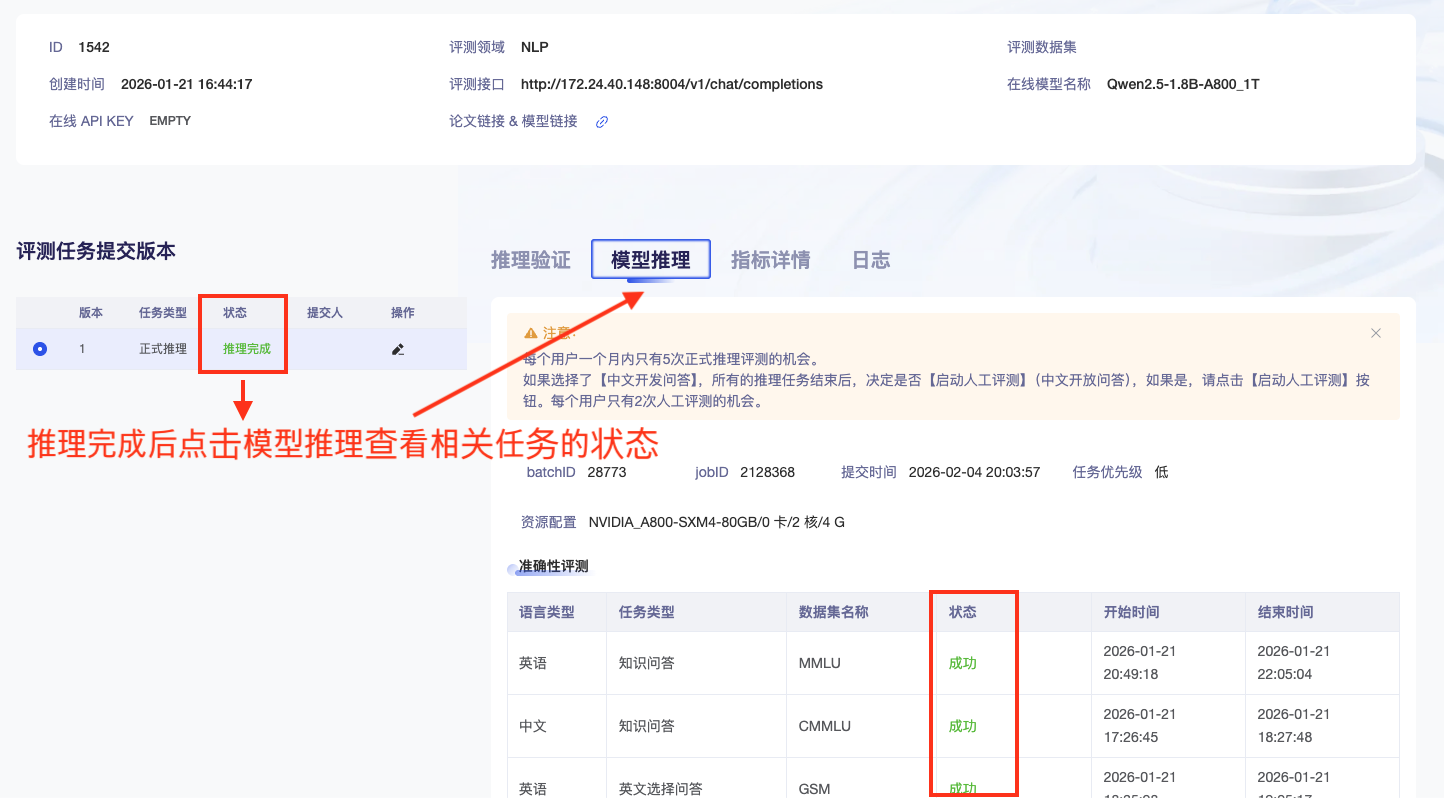
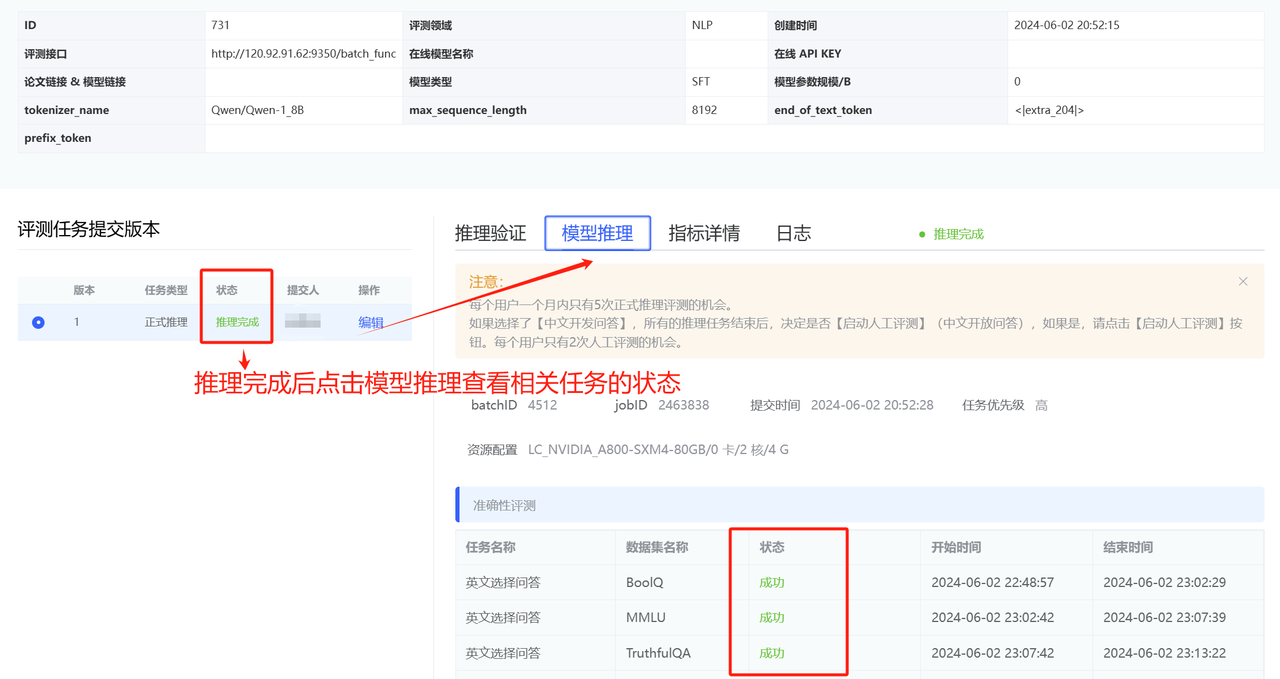 相关任务状态显示成功即可在指标详情下查看具体结果
相关任务状态显示成功即可在指标详情下查看具体结果 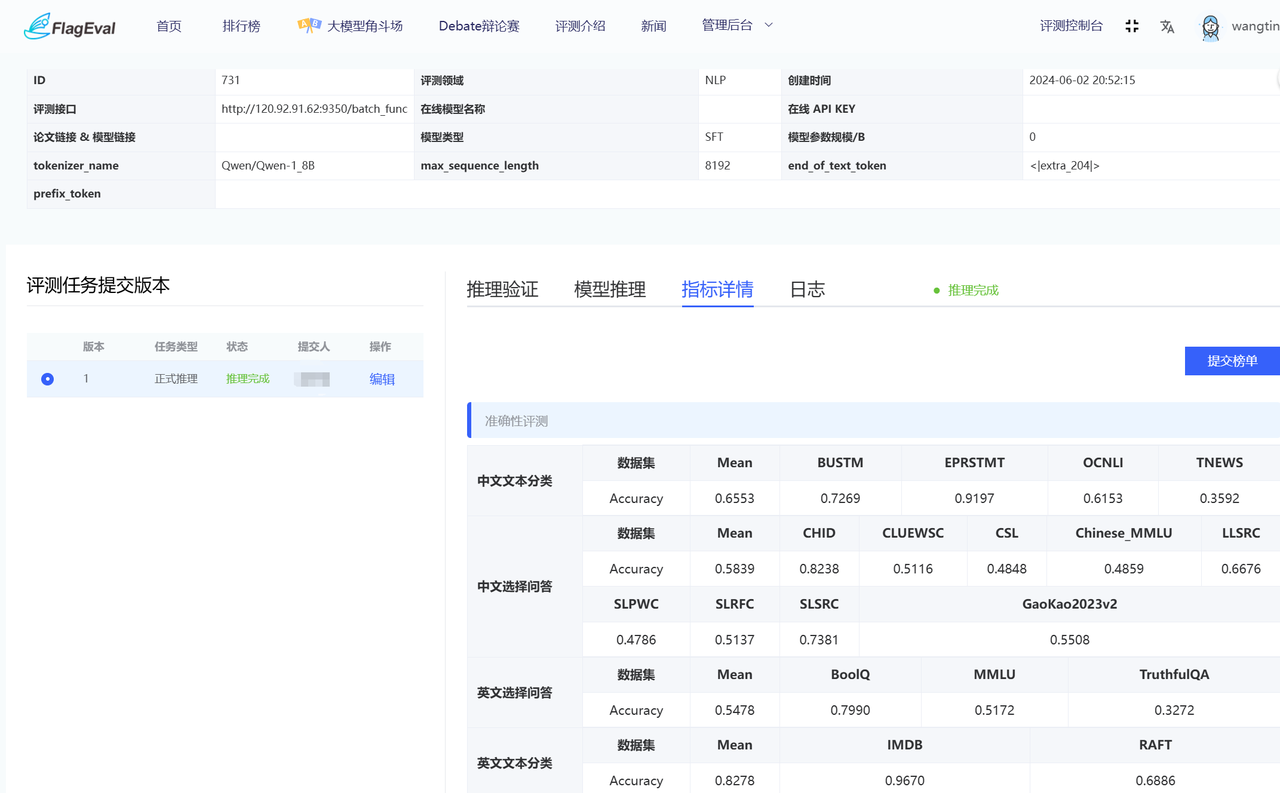
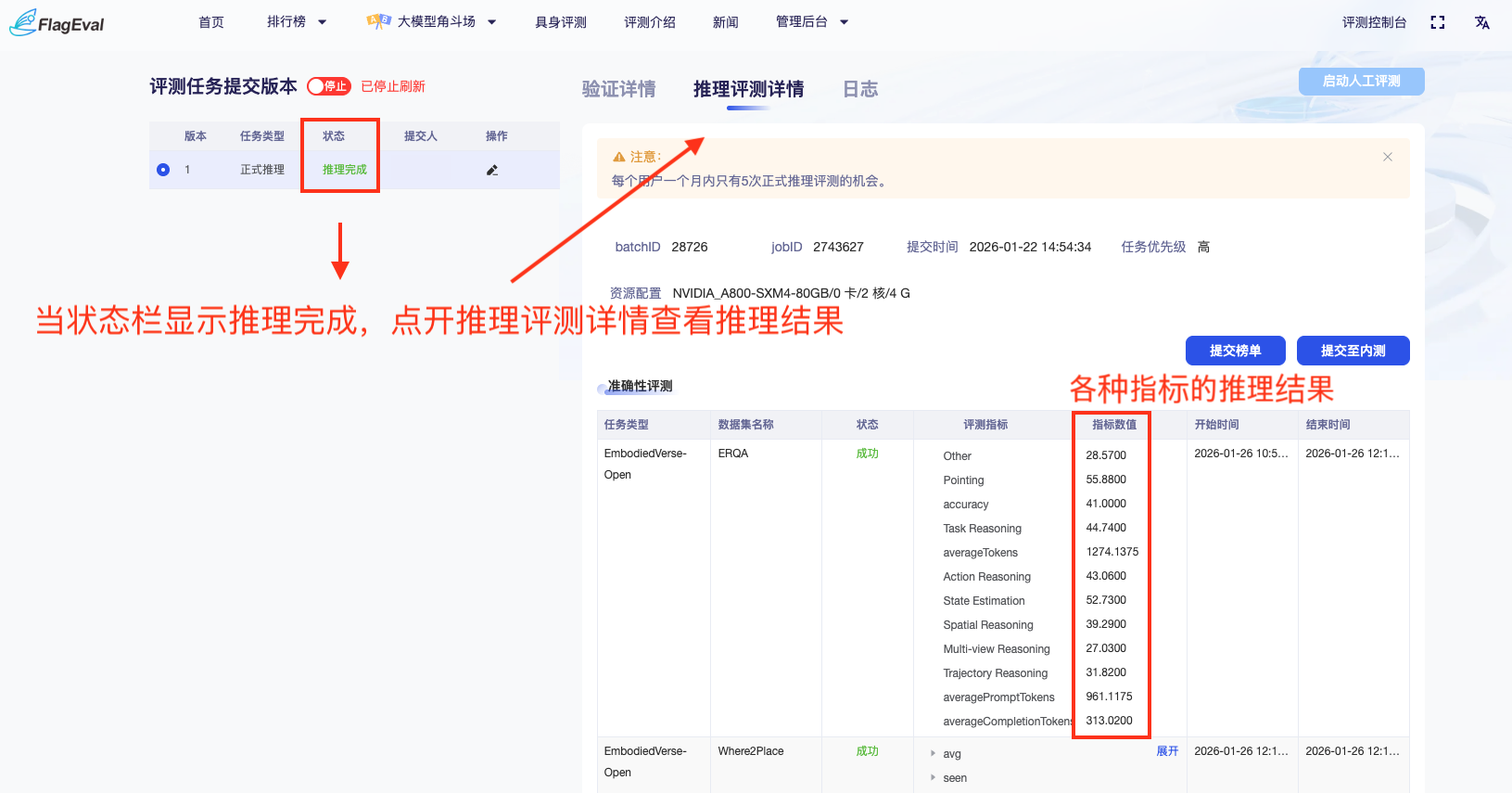
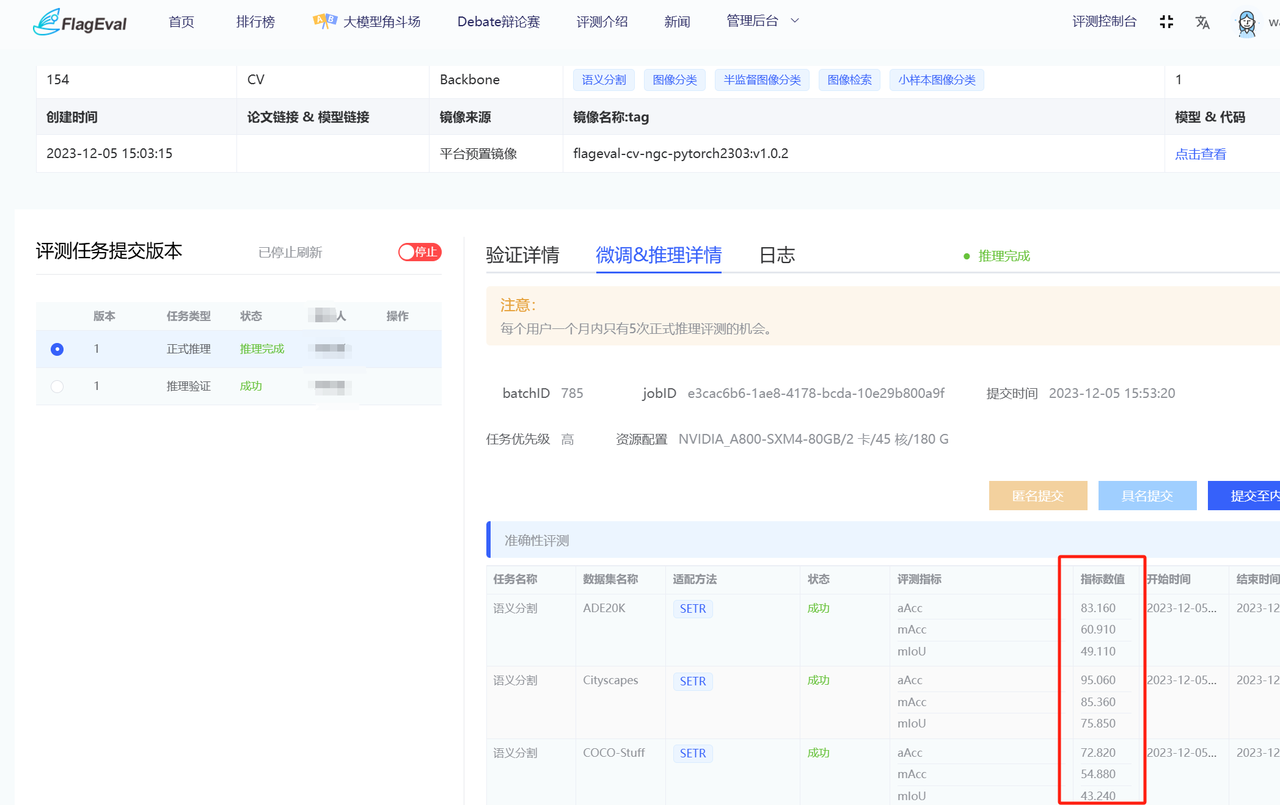
- CV领域评测结果查看 评测任务显示推理完成后,点击微调&推理详情查看评测结果
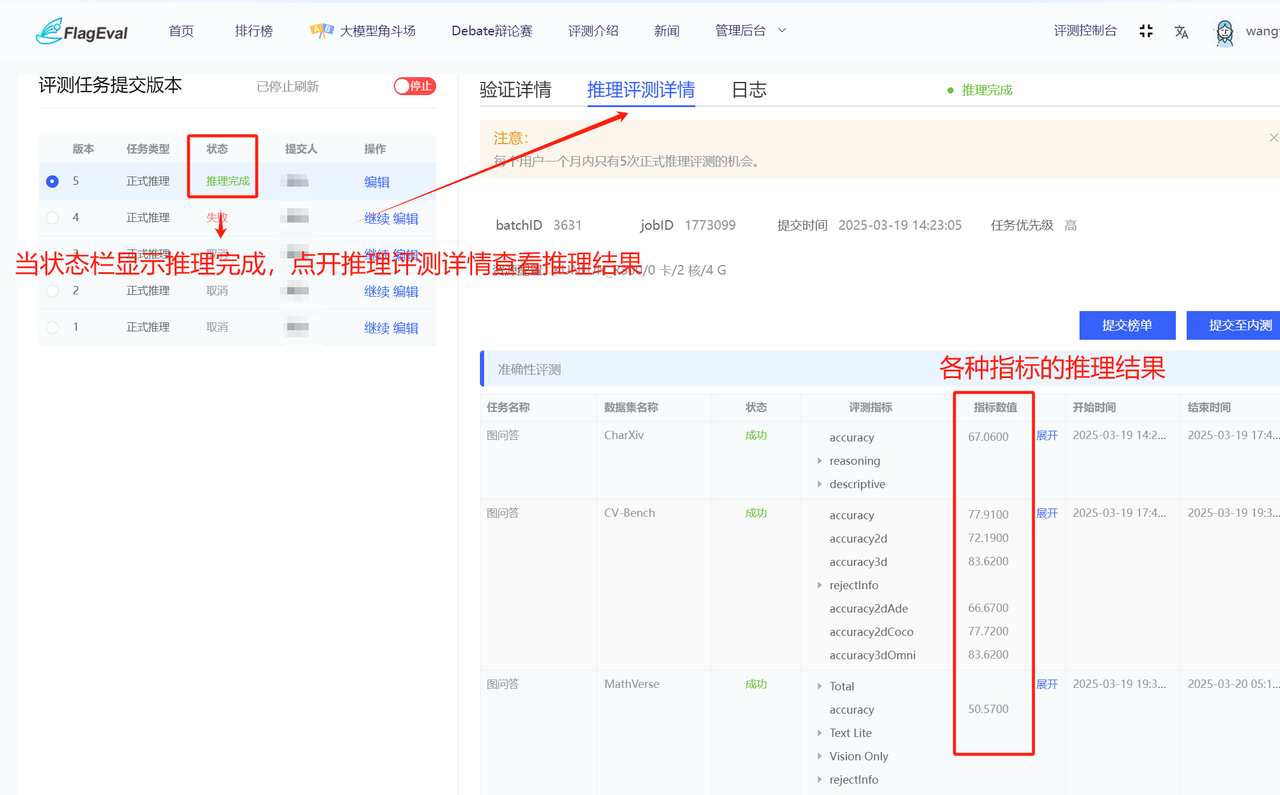
- Multimodal领域评测结果查看 在评测任务状态显示推理完成后,点击推理评测详情查看具体结果
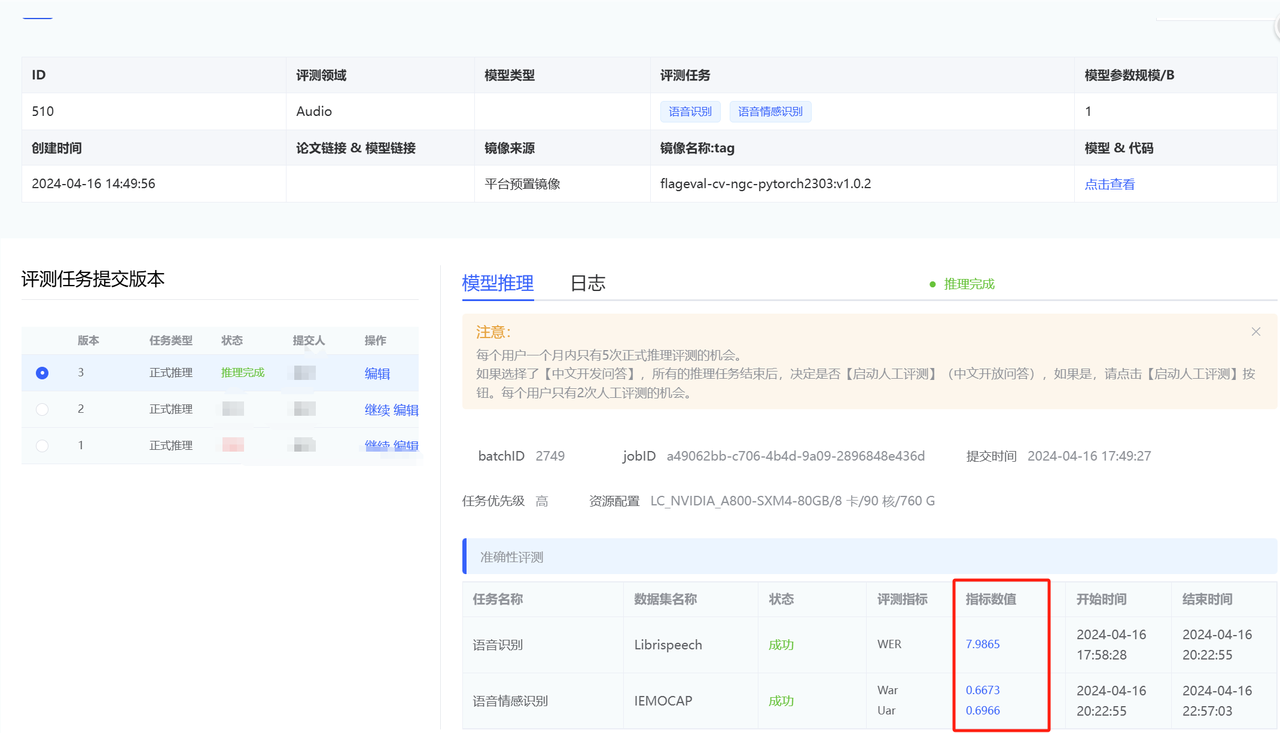
- Audio语音领域评测结果查看 在评测任务状态显示推理完成后,点击模型推理查看具体结果
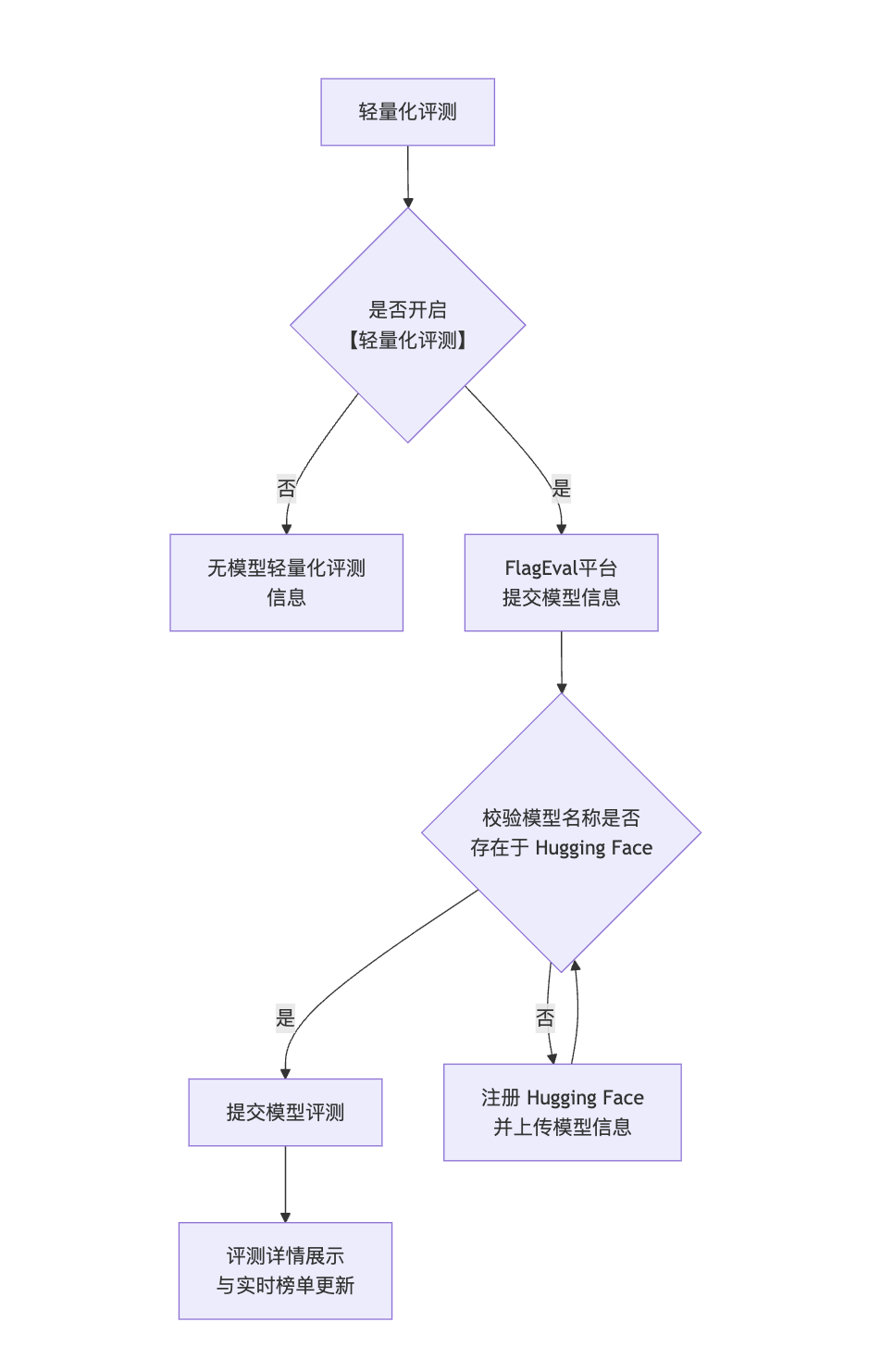
轻量化评测说明引导
目前本平台轻量化评测仅可用于模型NLP和multimodal能力评估,默认情况下关闭,手动开启后评测成绩将自动上传至「实时榜单」。
被评模型如采用API调用方式进行评测,需提前按照FlagEval平台接口规范准备标准格式API接口及apikey FlagEval评测 - API接口要求
被评模型如为开源模型,则需通过Hugging Face验证,必须为Hugging Face已注册模型方可进行评测。 以下为用户操作流程:
- 1 选择是否开启「轻量化评测」,开启后,评测成绩将自动上传至实时榜单。
- 2 选择开启「轻量化评测」按钮后,进行部署方式选择(目前多模态已支持API评测,大语言模型即将适配)
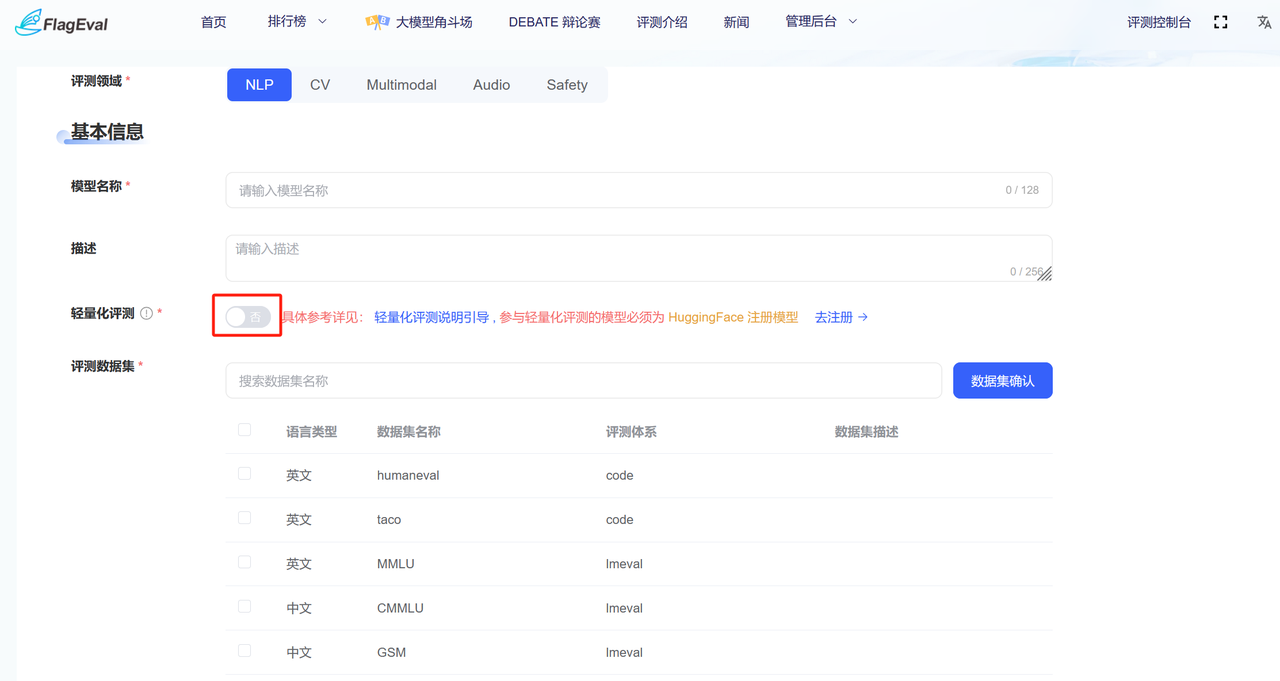
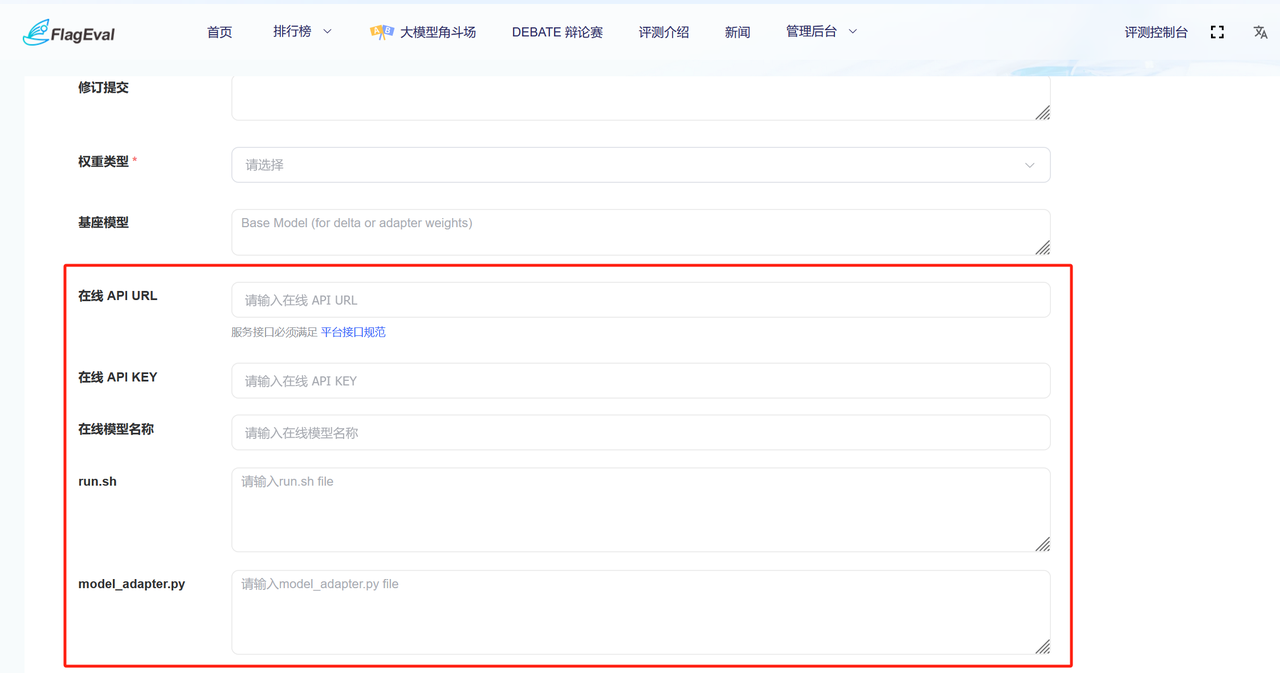
- API评测:通过API调用方式进行评测的模型,在下拉页面填写模型信息包括「模型名称」、「描述」、「部署方式」、「评测接口」、「在线模型名称」、「在线API KEY」
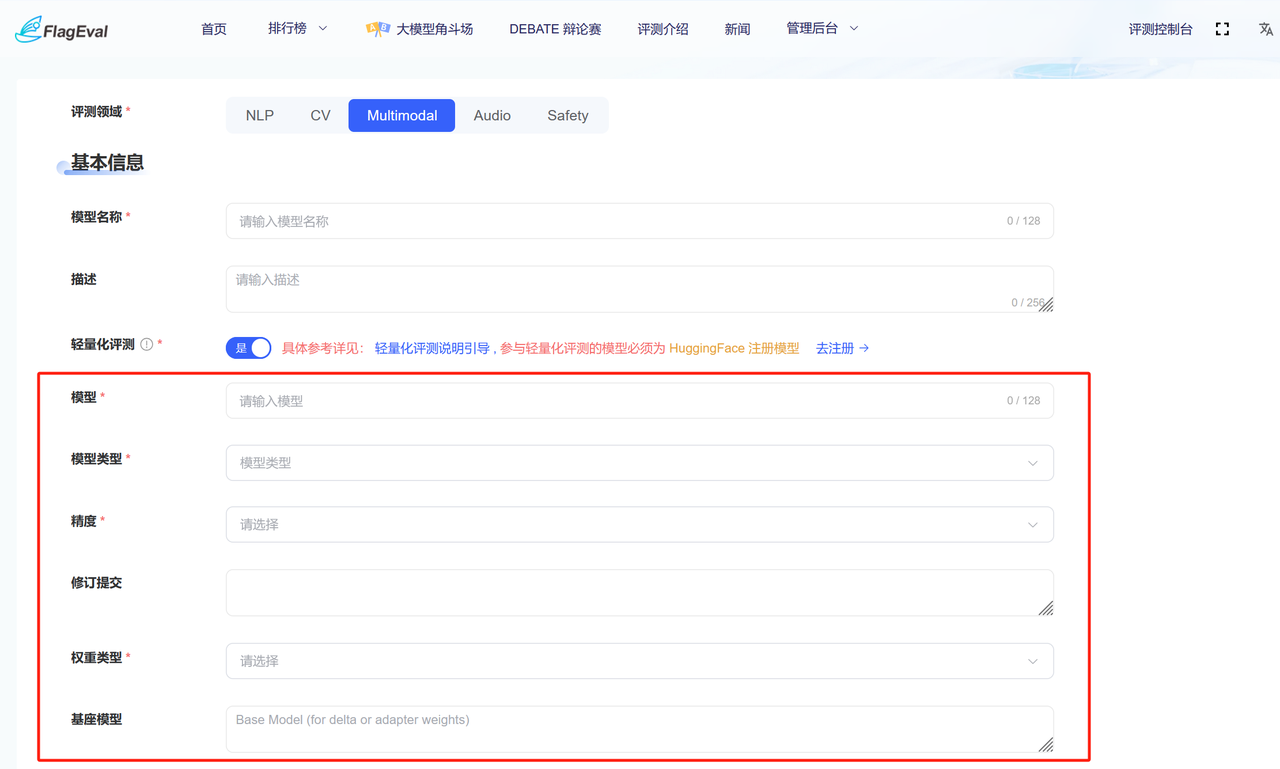
- 私有部署:私有部署方式支持开源模型。
在开启轻量化评测后,会对当前模型元信息进行验证,校验模型名称是否在Hugging Face中存在,如不存在则跳转至Hugging Face页面进行模型注册
Hugging Face模型校验通过后,用户可提交模型进行评测。
- 3 评测时间依赖当前被评测模型的大小,可在评测详情中查看当前评测任务进展
- 4 完成模型评测后,评测结果将同步展示在评测详情与实时排行榜中
多芯片模型适配评测
页面进入方式
- 平台登录:新用户首先访问 FlagEval 平台首页,注册并登录平台账号。

- 报名评测:注册完成后,跳转到平台首页,点击【评测控制台】,可报名评测。用户补充完整个人信息,平台管理员根据个人信息进行审核,审核通过的用户方可开启评测控制台查看权限。审核结果会以邮件的方式通知用户。
- 模块跳转:获得权限的用户可以在评测控制台左侧功能菜单栏中看到“多芯片模型适配评测”选项。点击该选项后,右侧内容区将自动跳转并加载该模块的页面信息。
- 子页面切换:“多芯片模型适配评测”包含两个子页面——“评测数据看板”与“模型列表”,可通过页面顶部的选项切换子页面。
评测数据看板页
- 用户进入“多芯片模型适配评测”模块后,系统默认展示“评测数据看板”页面。该页面从上至下 为「顶部数据标签」、「适配芯片列表」「统计汇总」与「各芯片模型适配评测情况」四个板块。
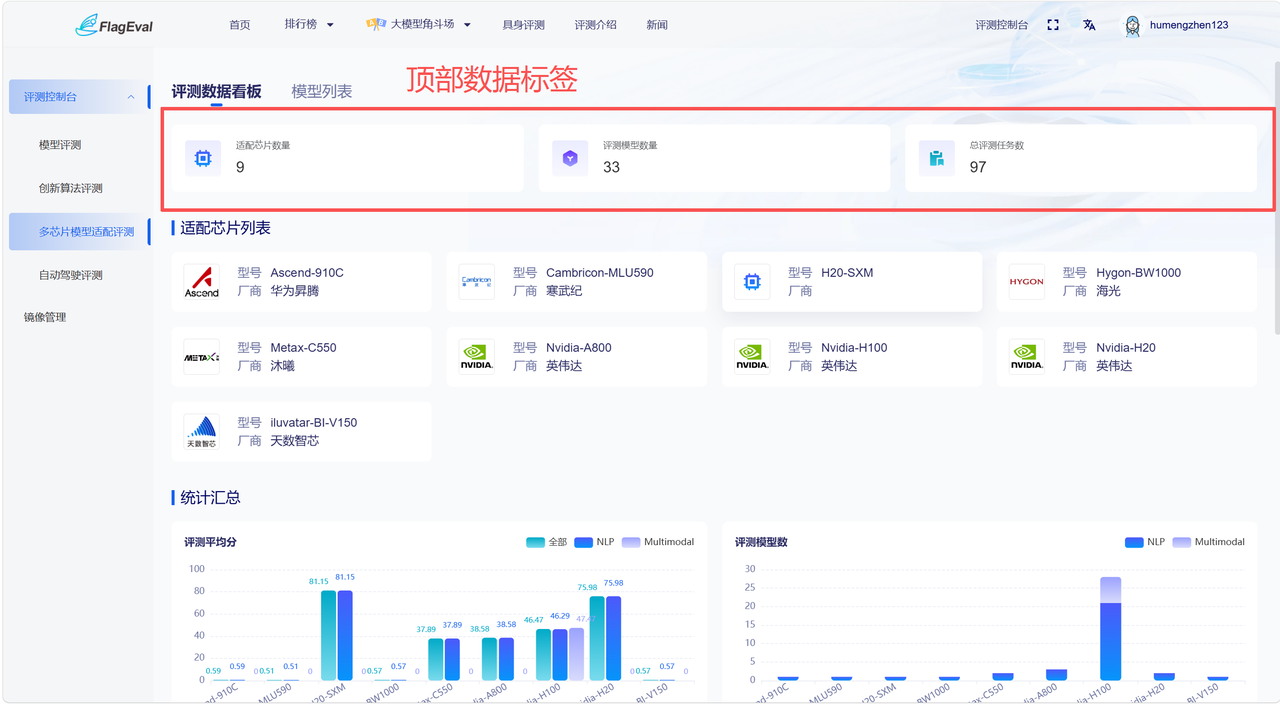
顶部数据标签
- 展示平台当前芯片评测总体情况
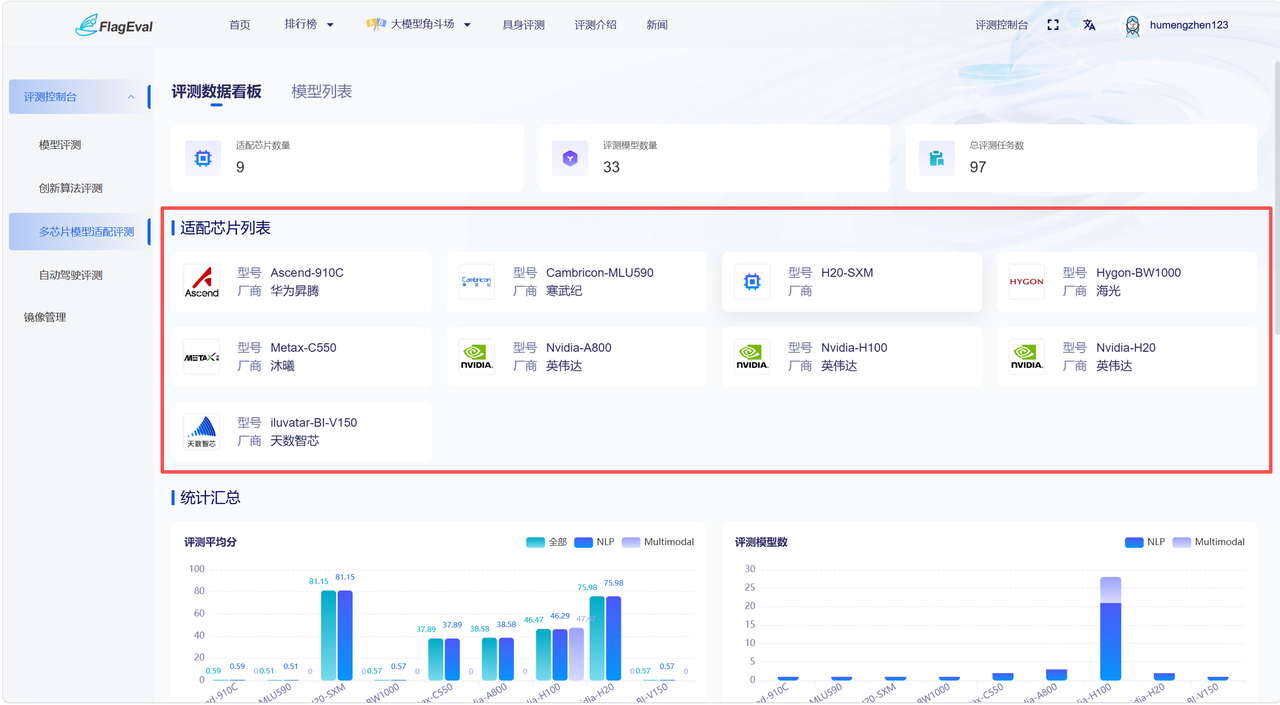
适配芯片列表
- 该区域展示适配芯片信息,具体字段信息包括:芯片logo、芯片型号、芯片厂商。
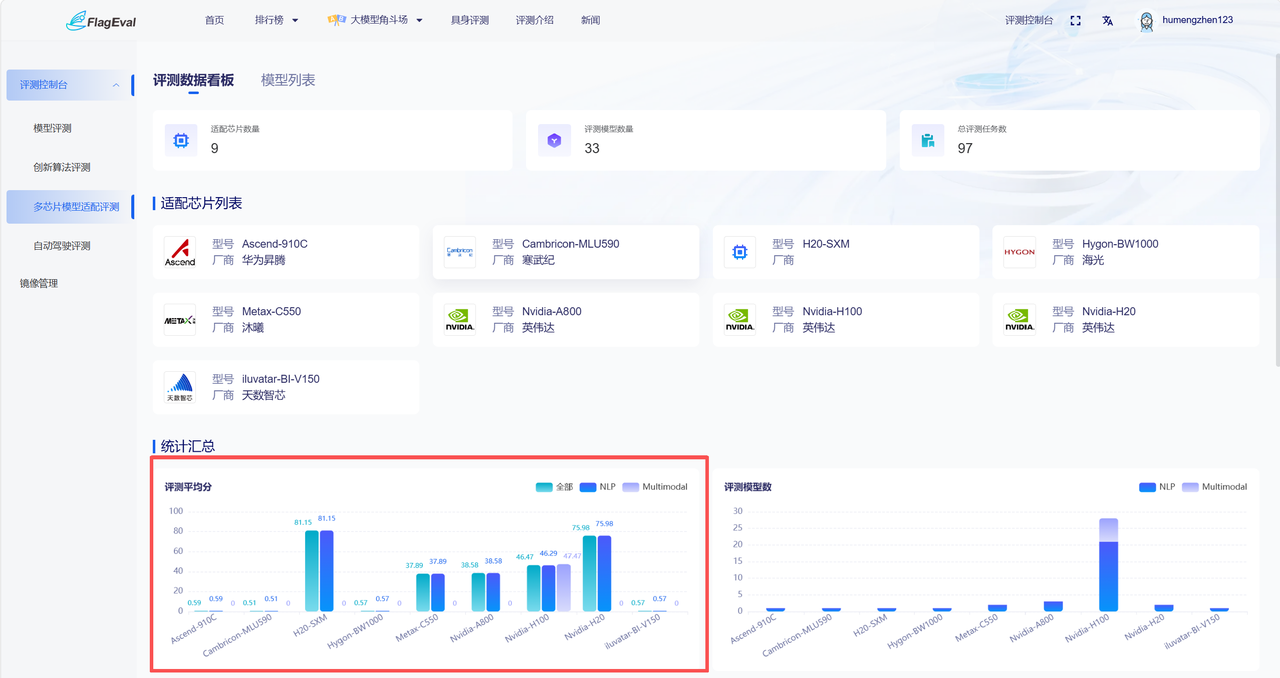
统计汇总-平均分
此板块内容为柱状图,用户可通过该图快速比较不同芯片的整体评测能力。
图表说明:
横轴:芯片型号,每个芯片包含“全部”、“NLP”、“Multimodal”三列数据
纵轴:评测平均分
图例呈现在图右上方:
全部:该芯片下所有参评模型评测分数的平均值
NLP:该芯片下 NLP 模型评测分数平均值
Multimodal:该芯片下多模态模型评测分数平均值
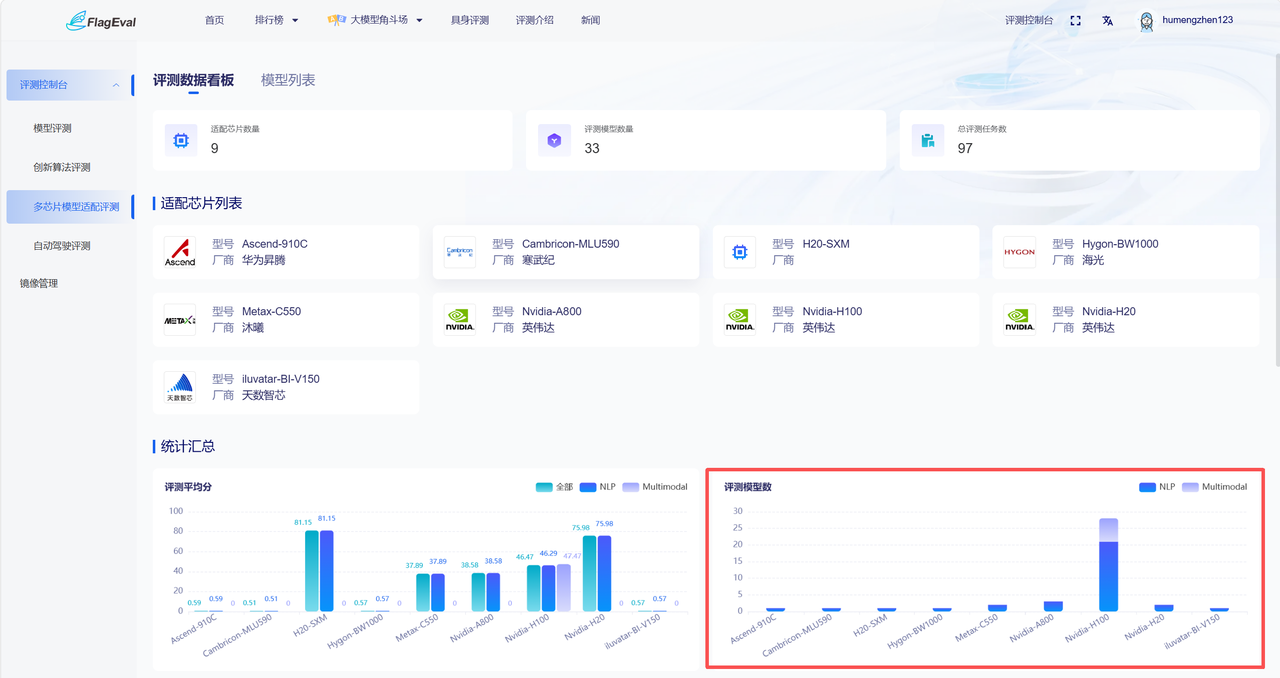
统计汇总-模型数
此板块内容为堆积柱状图,用户可通过该图了解各芯片生态覆盖情况及模型适配规模。
图表说明:
横轴:芯片型号
纵轴:芯片数量
图例呈现在图右上方:
NPL
Multimodal
鼠标悬停至图表对应区域时,可查看具体模型数量。
统计汇总-芯片-模型评分矩阵
此板块以热力图展示模型在不同芯片上的评测结果。
图表说明:
行:模型名称
列:芯片名称
单元格颜色深浅代表评测结果高低
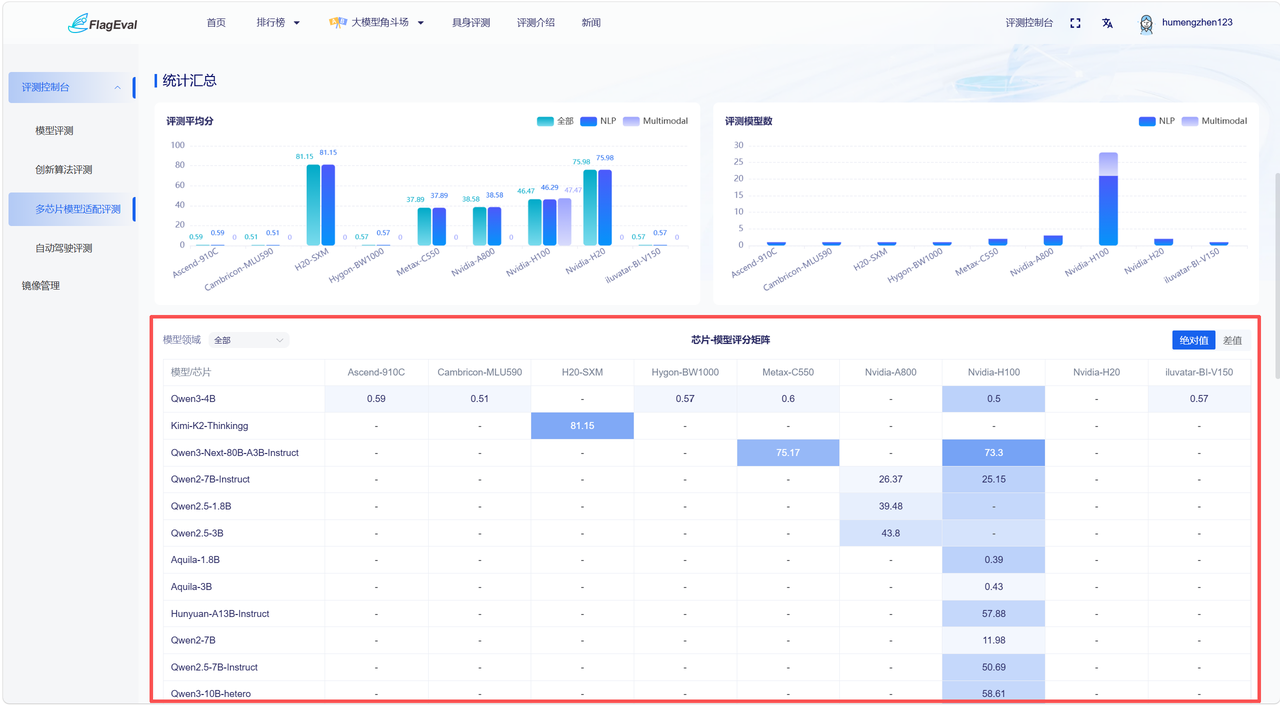
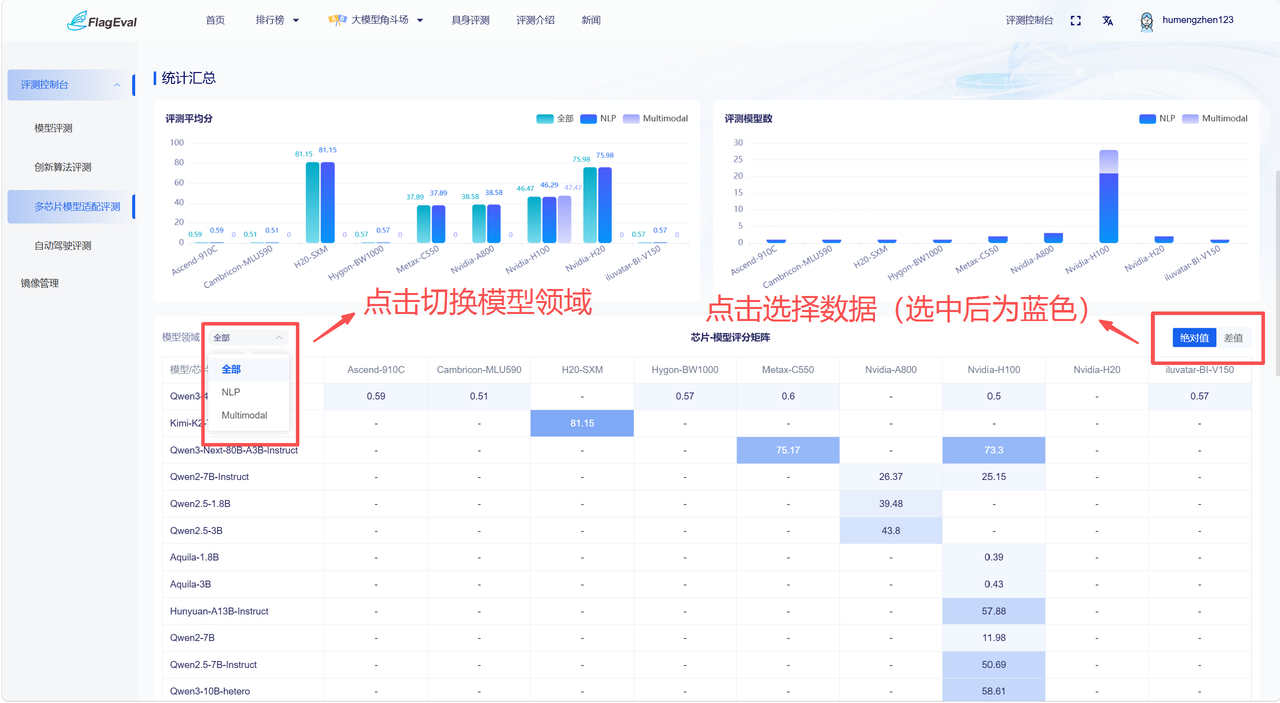
左上角可通过下拉框切换模型领域:全部、NLP、Multimodal;右上角可通过点击选择数据(选中后为蓝色):评分绝对值、与 Nvidia-H100 的评分差值。
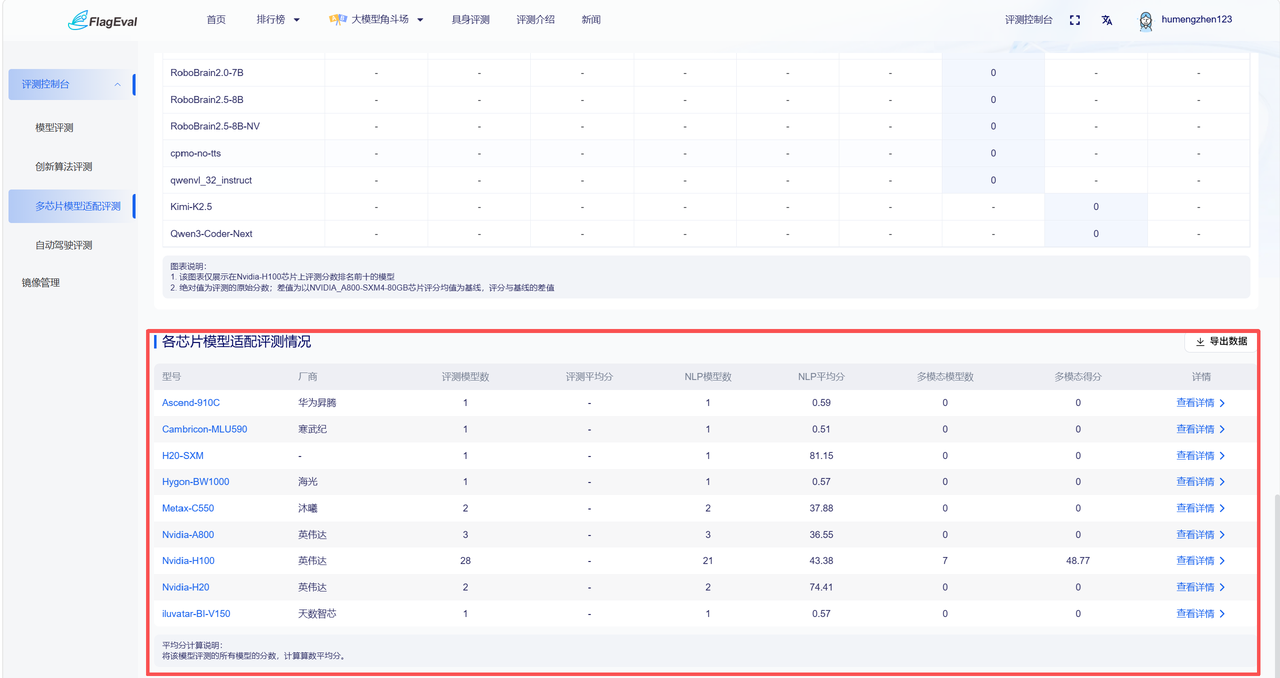
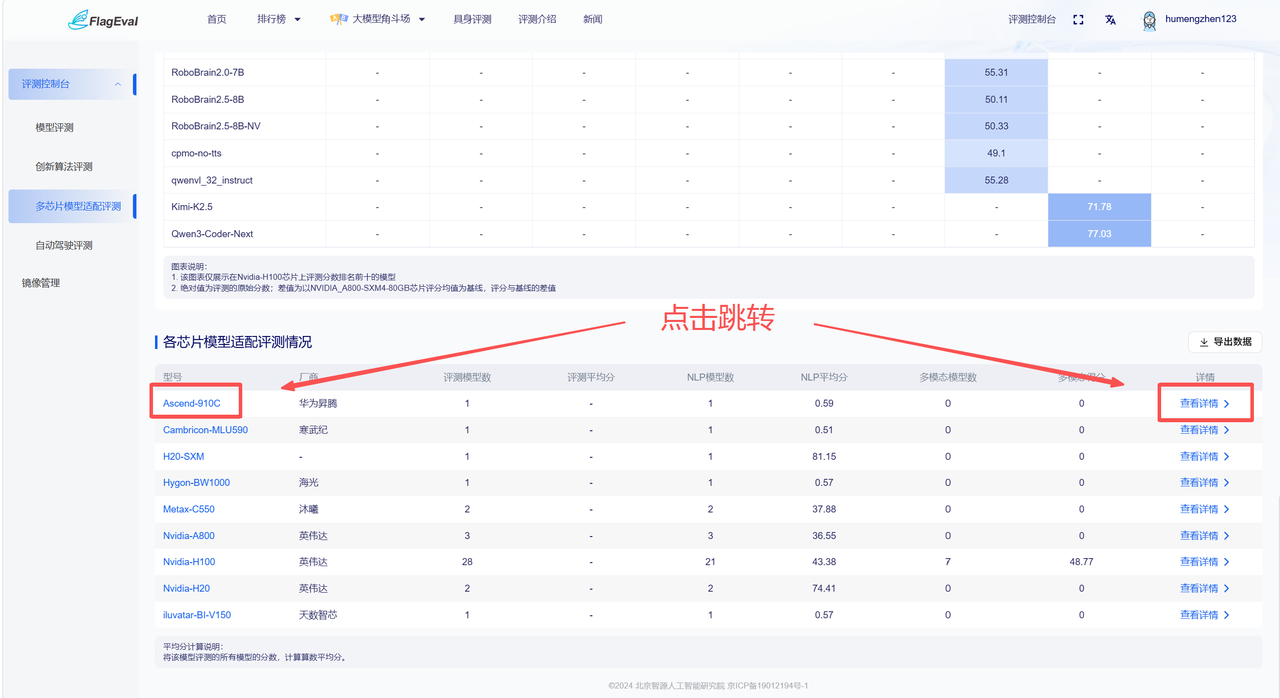
各芯片模型适配评测情况
此板块以表格形式展示各芯片整体评测情况,具体字段信息为:
| 字段名称 | 说明 |
|---|---|
| 型号 | 参评芯片型号,点击可查看芯片详情 |
| 厂商 | 芯片所属厂商 |
| 模型数 | 已完成评测的模型数量 |
| 平均分 | 当前芯片所有参评模型平均得分 |
| 详情 | 点击可查看对应芯片详细信息 |
右上角可点击「导出数据」按钮,自动下载电子表格xlsx文件(不包含详情列)
从表格中点击蓝色字体的具体芯片型号或详情栏的”查看详情“可跳转至该芯片的详情页。
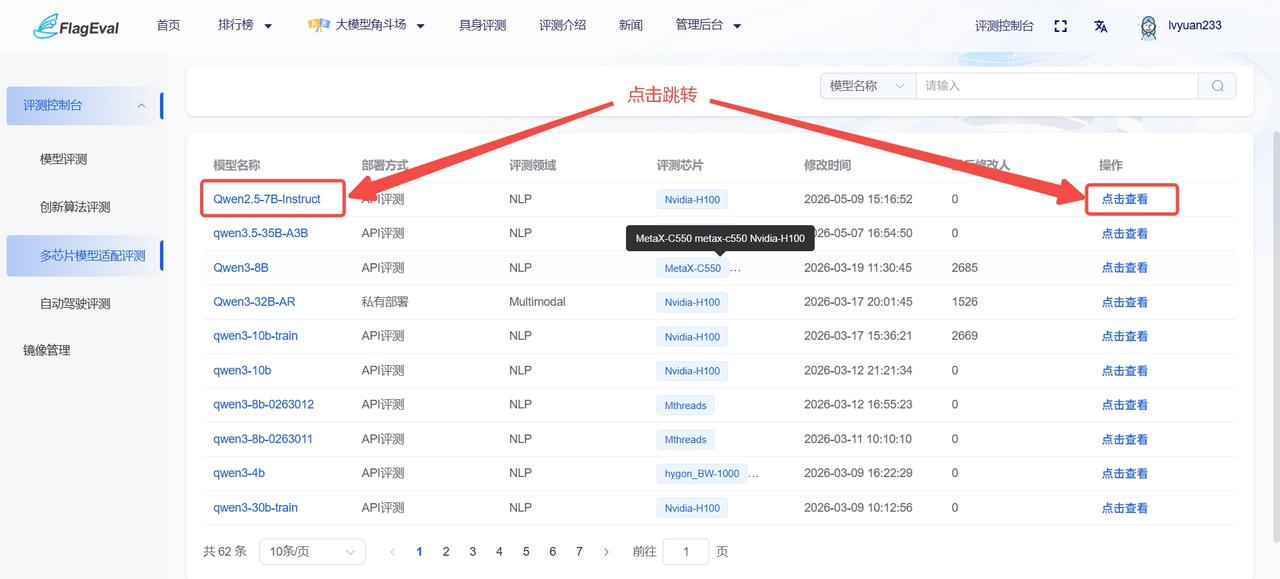
评测模型列表页
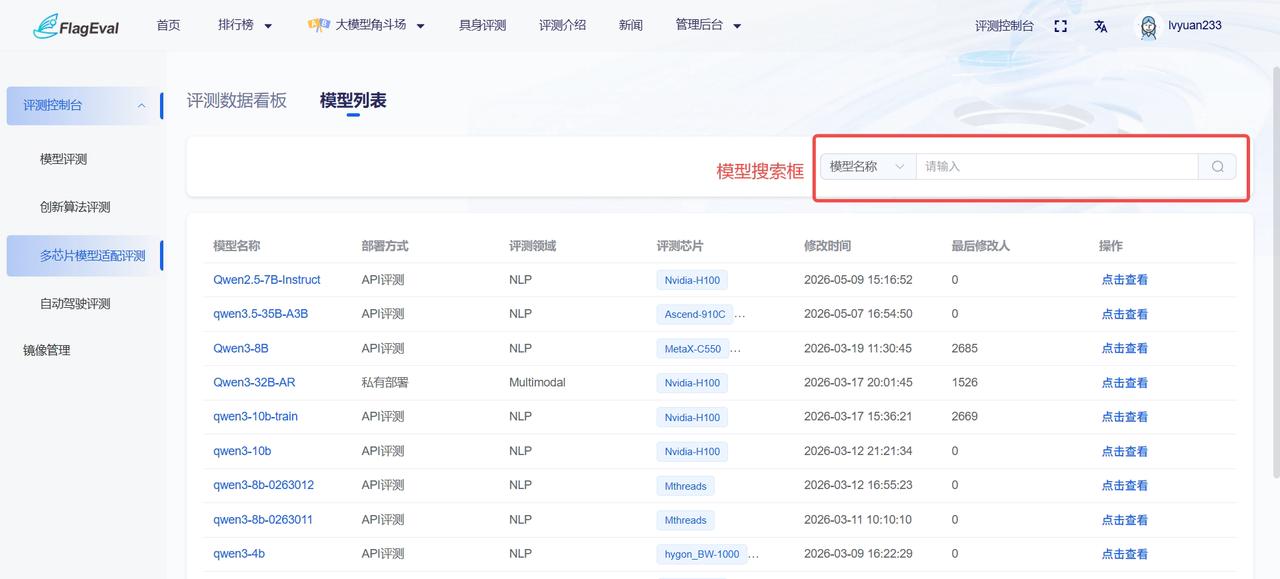
模型搜索框
- 操作方式:在页面右上方的搜索框中,选择“模型名称”并输入关键字,支持根据模型名称模糊查询,帮助用户在大量适配模型中快速定位目标模型。
模型列表
- 主内容区以列表形式展示适配的模型信息,具体字段信息为:
| 字段名称 | 说明 |
|---|---|
| 模型名称 | 参评模型的唯一标识(例如:Qwen2.5-7B-Instruct、Qwen3-8B) |
| 部署方式 | 模型在评测环境中的部署类型(如:API评测) |
| 评测领域 | 模型所属的技术赛道(如:NLP 自然语言处理、Multimodal 多模态) |
| 评测芯片 | 该模型已适配并运行评测的芯片型号(如:Nvidia-H100) |
| 修改时间 | 该条评测记录最后一次更新的时间戳 |
| 最后修改人 | 操作该记录的管理员或系统 ID |
| 操作 | 点击 【点击查看】 可跳转至该模型的详细评测记录 |
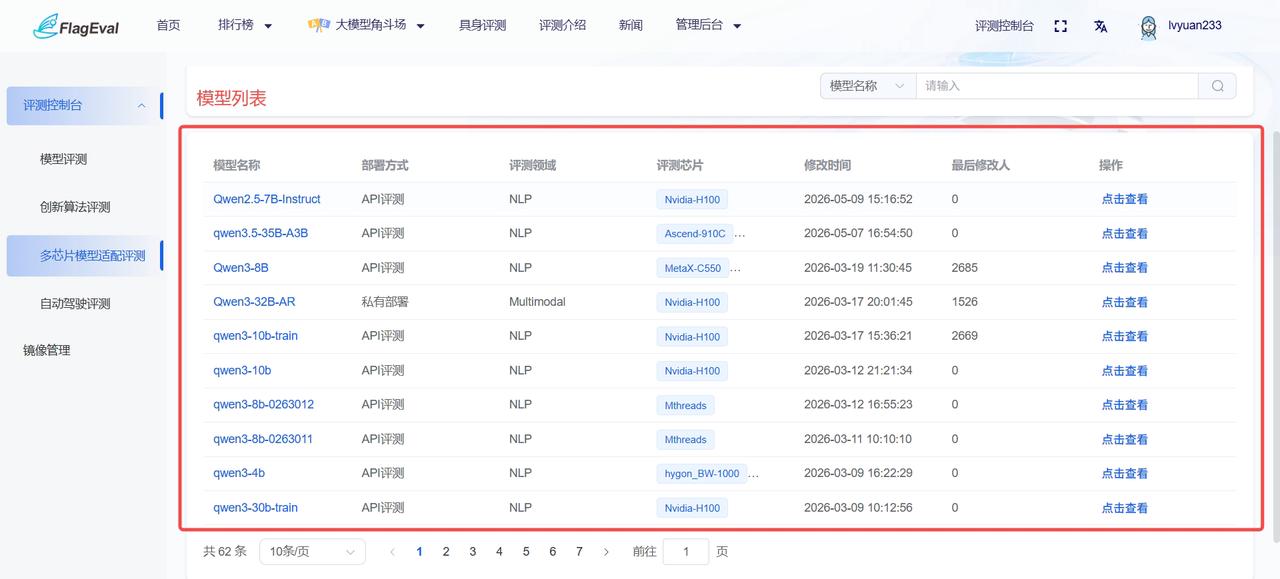
从“模型列表”中点击蓝色字体的模型名称或操作栏的“点击查看”,可跳转至该模型对应的详情页。
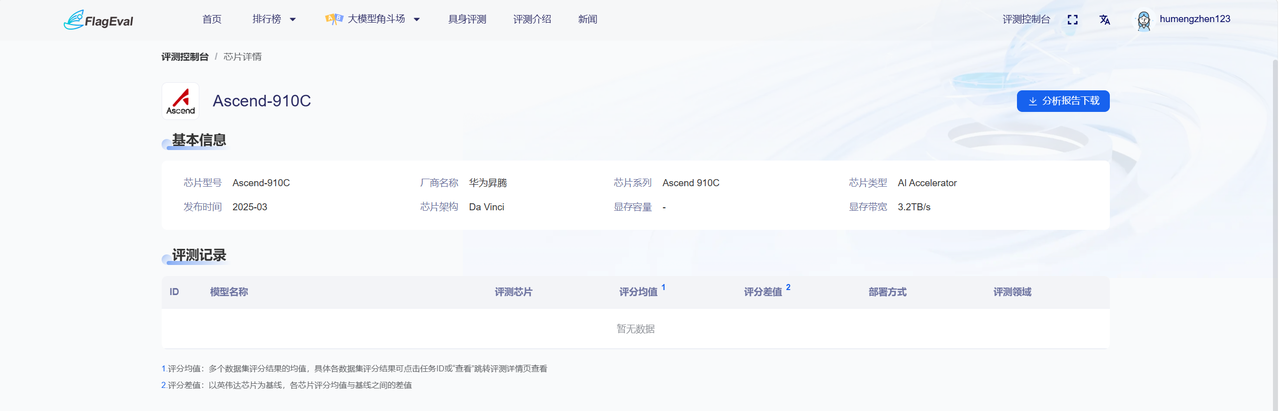
评测模型详情页
- 进入模型详情页后,左上角展示该模型的名称,下方依次展示模型的基础信息与评测记录。
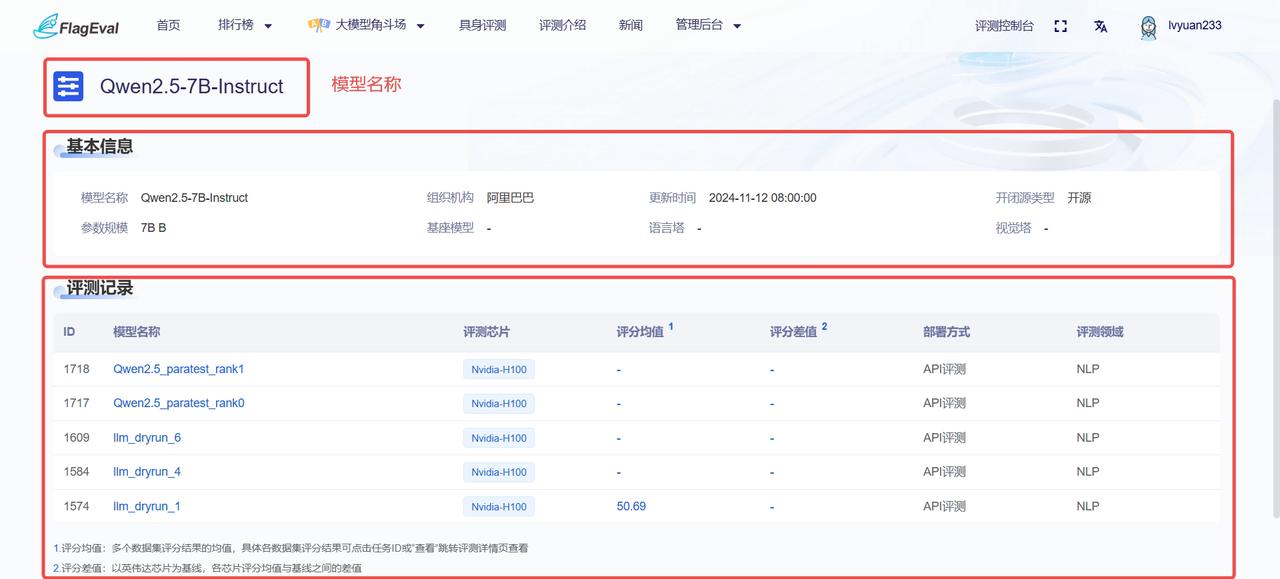
- 模型基本信息: 该区块列出了模型的基础元数据,方便用户核对评测对象的版本,具体字段为:
| 字段名称 | 说明 |
|---|---|
| 模型名称 | 当前查看的模型名称 |
| 更新时间 | 该模型最后一次同步或更新数据的时间 |
| 开闭源类型 | 明确标注模型是开源还是闭源 |
| 其他参数 | 包括参数规模、基座模型、语言塔及视觉塔等配置信息 |
- 评测记录: 记录了该模型在不同芯片上的评测记录,具体字段信息为:
| 字段名称 | 功能说明 |
|---|---|
| ID | 评测任务的唯一标识编号 |
| 模型名称 | 该次评测任务的具体模型版本 |
| 评测芯片 | 模型适配的具体芯片 |
| 评分均值 | 模型在该芯片上多个测试集得分的平均值 |
| 评分差值 | 该芯片评分均值与基准芯片评分均值的差值 |
| 部署方式 | 评测时采用的部署类型 |
| 评测领域 | 任务所属的专业领域 |
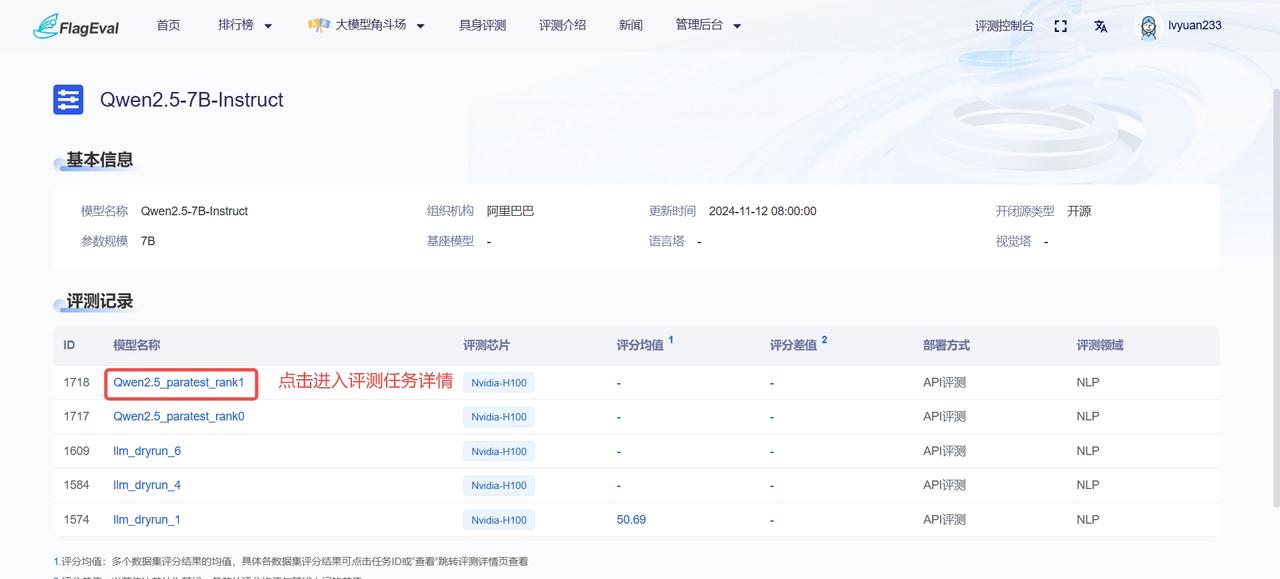
- 从“评测记录”列表中点击蓝色字体的模型名称,会跳转到该评测任务的详情页面,可查看具体的评测结果。
NLP 领域评测结果查看
- 相关任务状态显示成功即可在指标详情下查看具体结果。
Multimodal 领域评测结果查看
- 在评测任务状态显示推理完成后,点击推理评测详情查看具体结果。