

Quick Start
Register and Login
Unregistered users are by default allowed to view the platform’s homepage, news, leaderboard, and user manual, as well as experience the Large Model Arena and Debate Competition features.
To access the evaluation functions, users must register and log in to the platform, apply for participation in the evaluation through the Evaluation Management section, and complete their personal information. Please ensure that all submitted information is accurate and valid. Once the information is submitted and approved by the administrator, users will be granted access to the evaluation features of the platform.
Detailed instructions are as follows:
Register
When users click the [Login/Register] button, the following interface will appear. For first-time users, please scan the QR code using WeChat to follow the “BAAI Community Assistant” official WeChat account.
 After scanning the QR code and following the account, the interface will update to the following layout, where users can register by entering their email, phone number, and verification code online.
After scanning the QR code and following the account, the interface will update to the following layout, where users can register by entering their email, phone number, and verification code online. 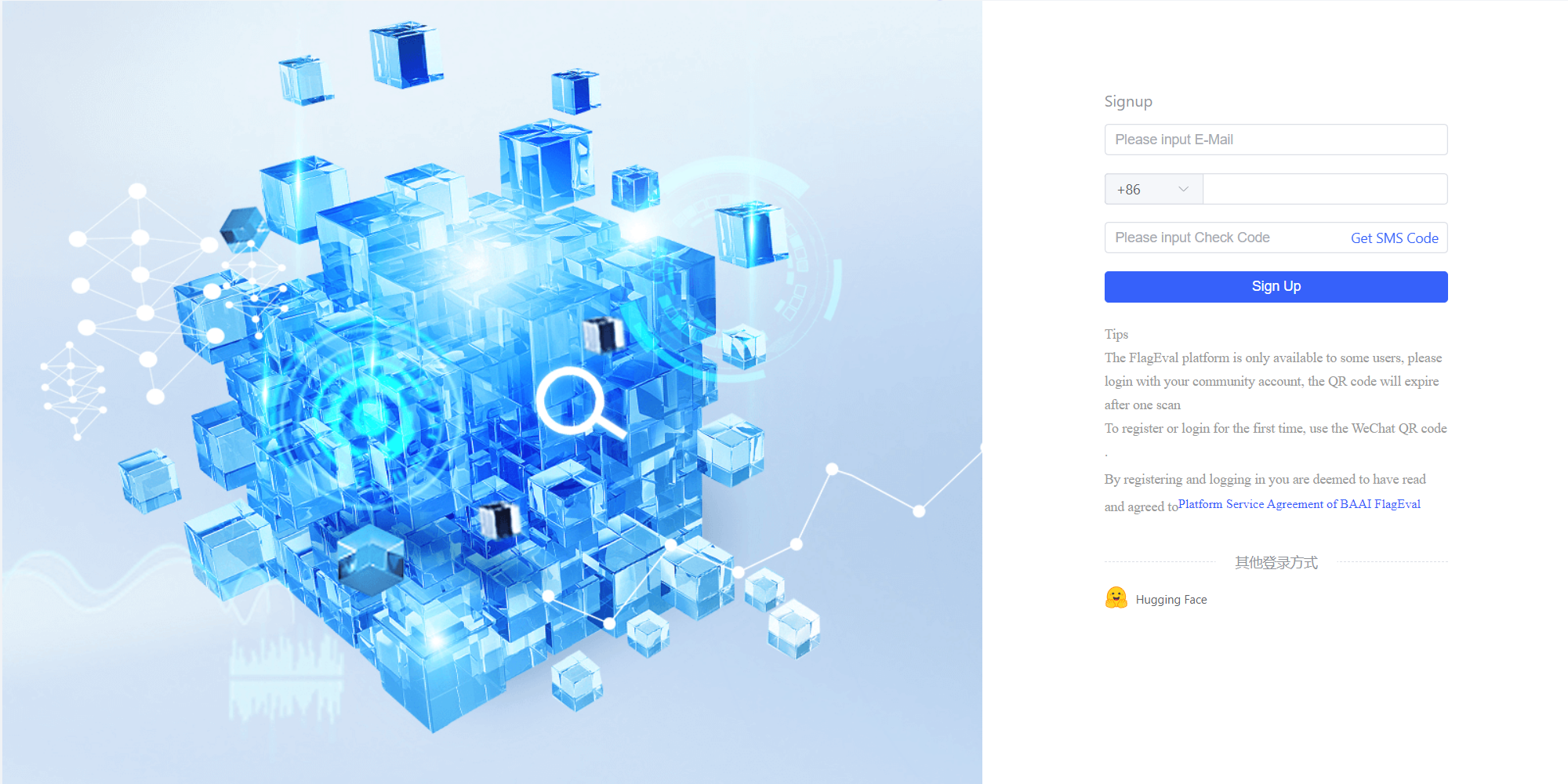
After completing registration, the system will redirect to the platform homepage. By clicking [Evaluation Console], users can apply for evaluation participation. Users are required to complete their personal information, which the platform administrator will review. Only users who pass the review will be granted access to the evaluation features. The review result will be sent to users via email.
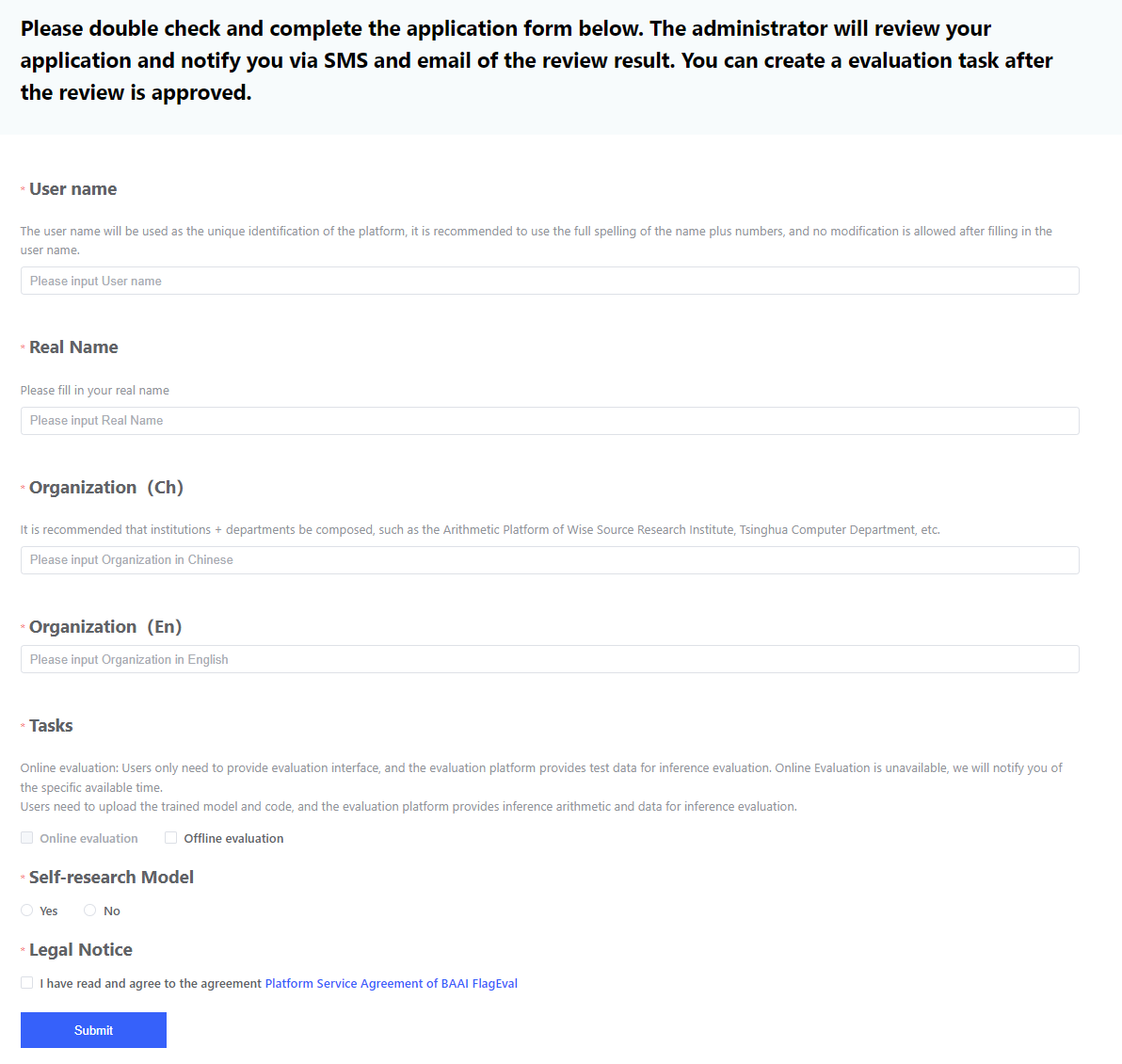
| Parameter | Explanation |
|---|---|
| Username |
|
| Real Name |
|
| Organization |
|
| Task to Register |
|
| Whether to evaluate self-developed models |
|
| Agreement statement |
|
The registration process is shown in the following image:
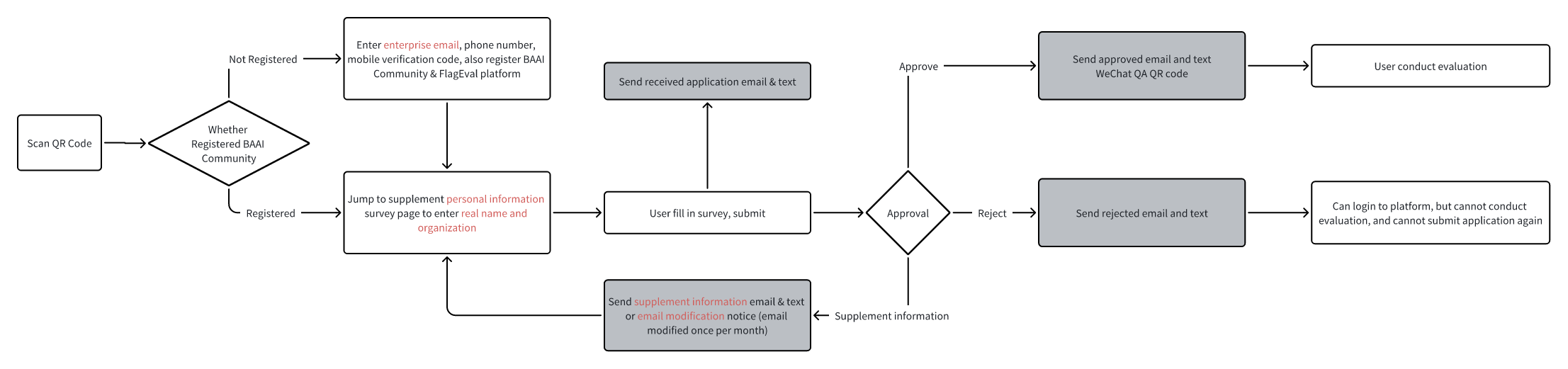 Note:
Note:
- Please fill in your personal information carefully, as the administrator will review your application based on the provided details.
- Please fill in a valid personal business email. The review status will be notified via email and SMS, and future evaluation task updates will be sent by email.
- If a personal email is used, the administrator will send an email requesting you to update it. Please change to an email address and wait for the review again. Each user is allowed to modify their email only once per month.
Login
If the user has already completed registration, clicking the [Login/Register] button will bring up the Login page. The user can choose to log in by scanning the QR code at the top of the screen using WeChat Scan, or by using the Mobile Verification Code option.
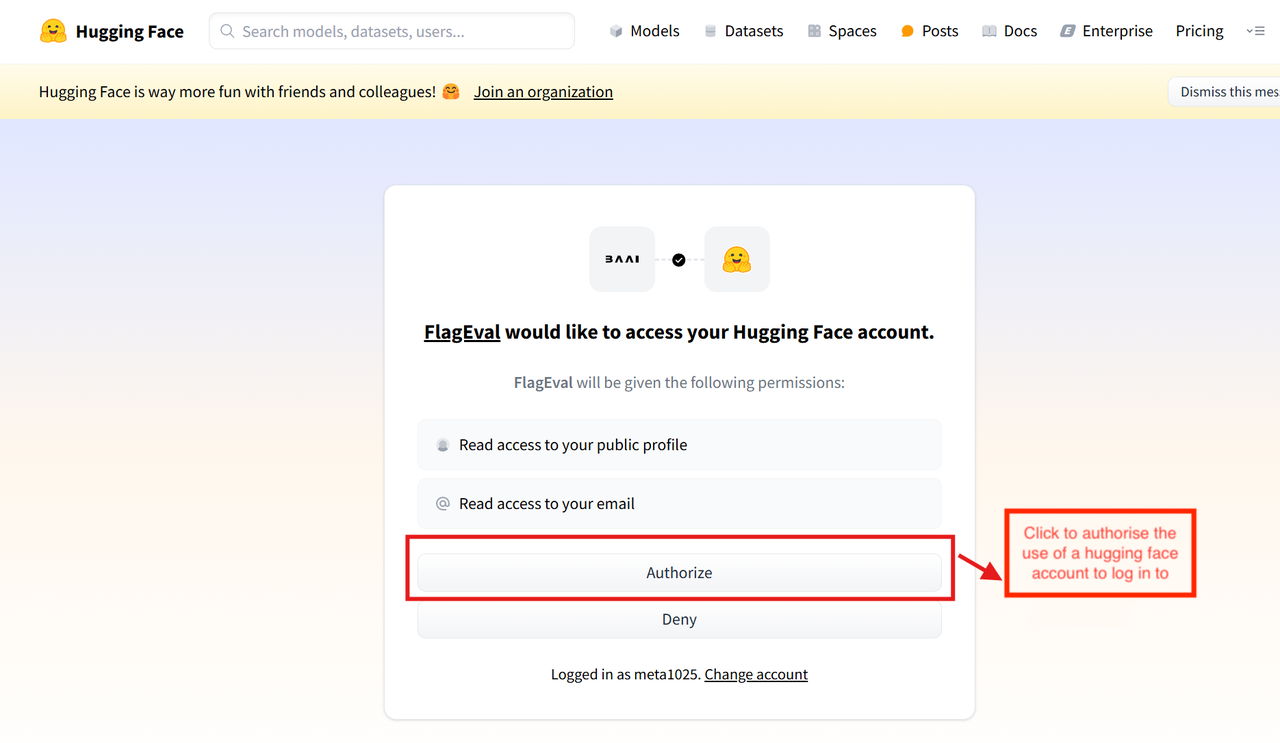
Alternatively, the user can click [Hugging Face] to log in via a third-party platform, which will redirect to the Hugging Face login page.
The login process is as follows: 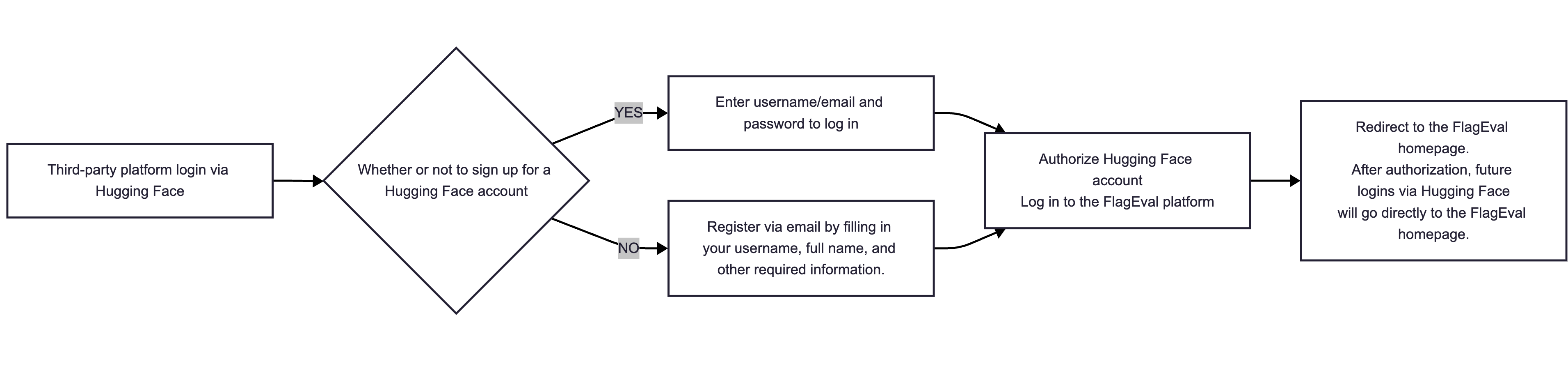

Enter the following two pieces of information: Username / Email Address and Password.
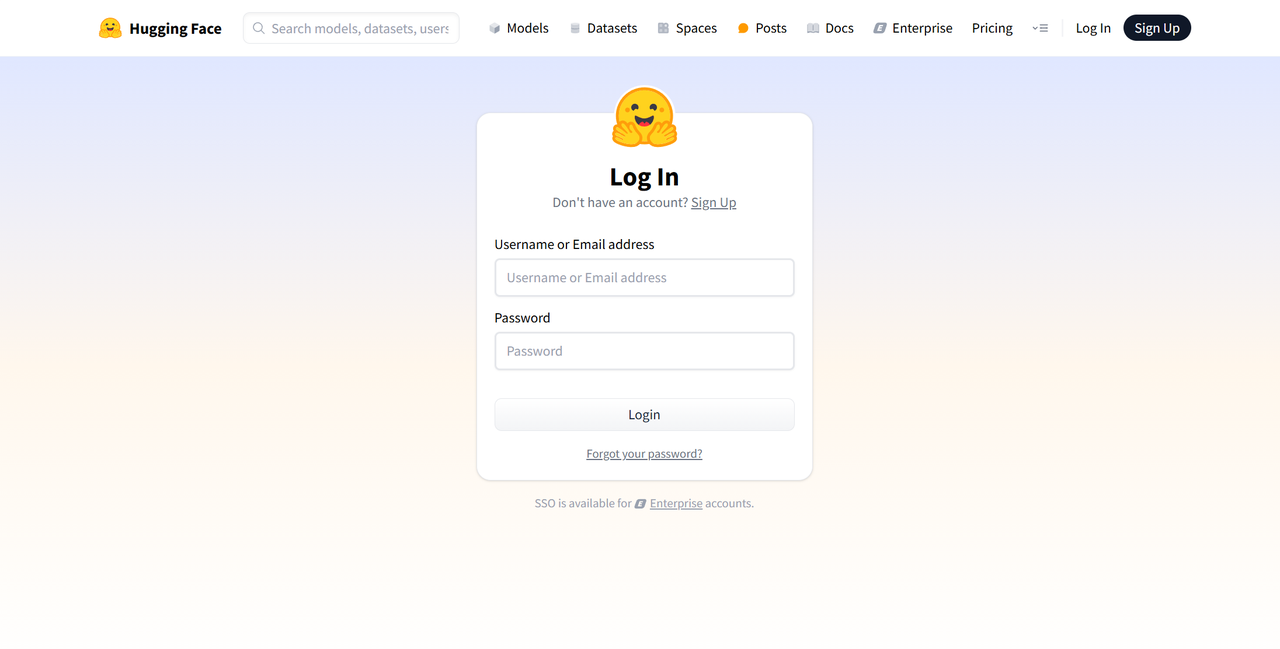
If you do not have a Hugging Face account, please register first. You can also log in by authorizing with your Hugging Face account. 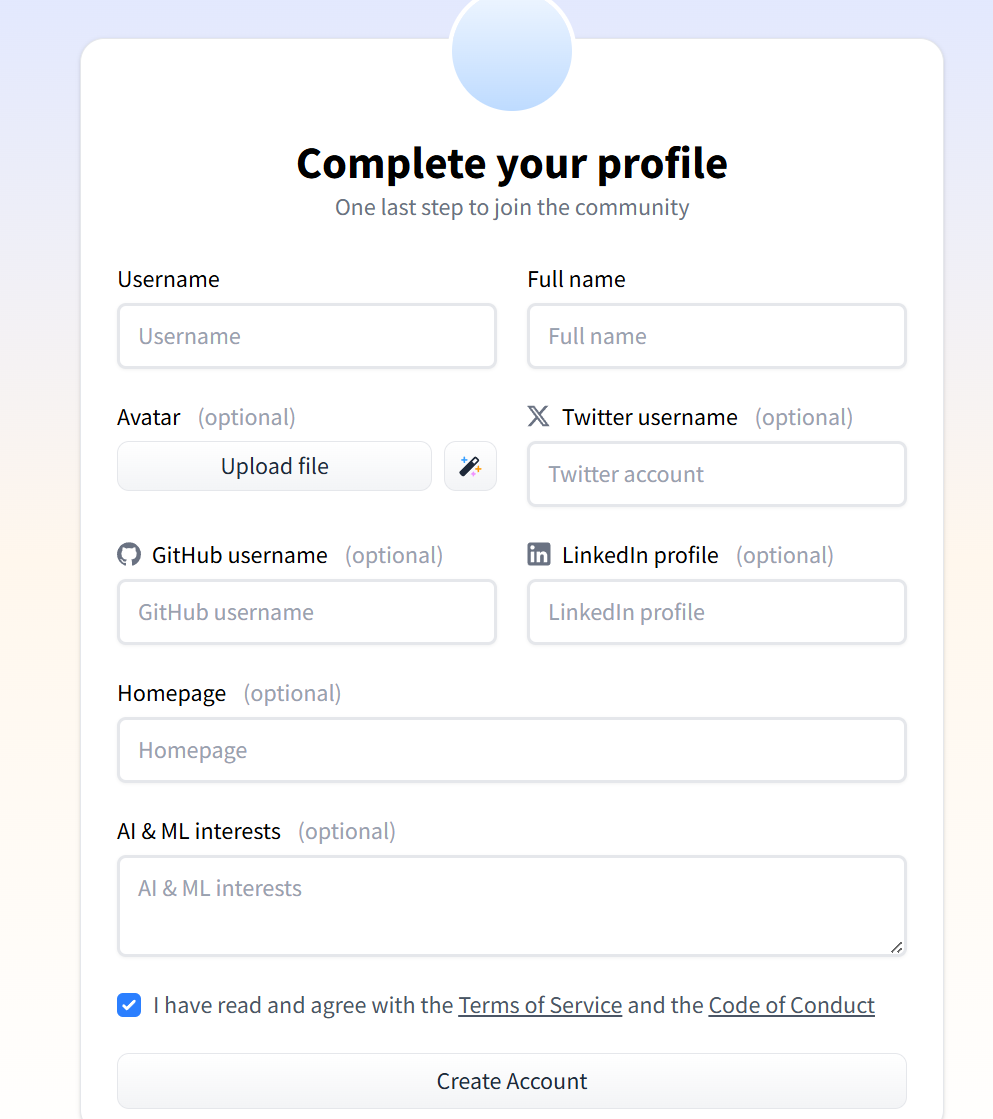
Create Evaluation
When users click [Evaluation Management], they will enter the Evaluation Management page, which mainly includes: Model Evaluation, Innovative Algorithm Evaluation, and Image Management.
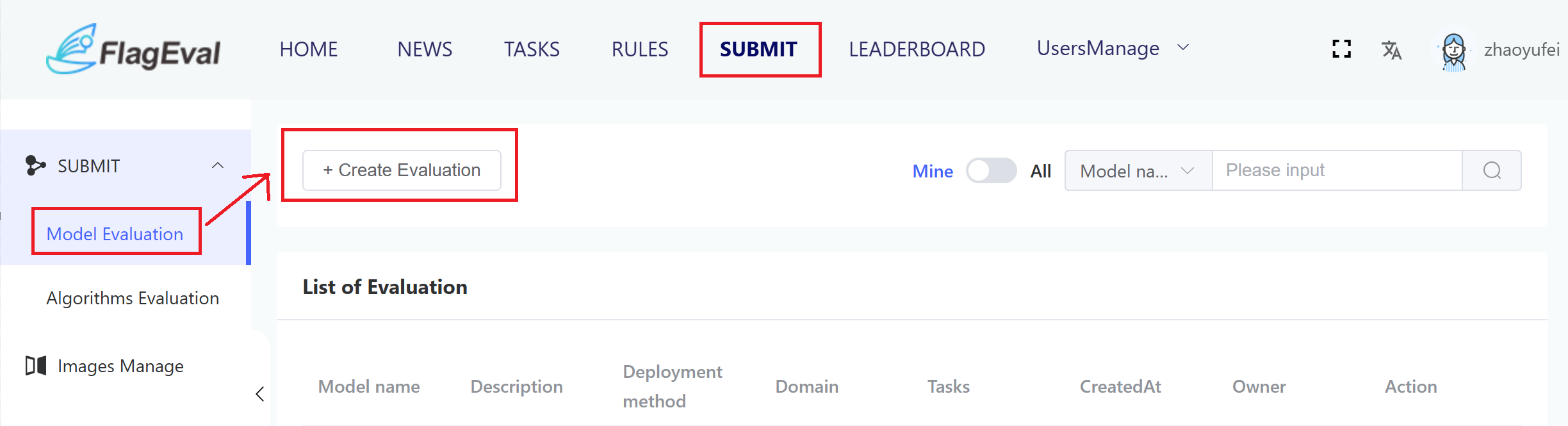
Users can choose either Model Evaluation or Innovative Algorithm Evaluation based on their needs. By clicking [Create Evaluation], a Create Evaluation dialogue box will pop up. Users should fill in the corresponding form according to the evaluation domain to submit and generate an evaluation task.
After creating an evaluation, the system will automatically redirect to the task details page. Users can click to view the "Upload Model & Code" specification and use flageval-serving to upload models and codes. After uploading, click "Inference Verification" to quickly verify whether the inference evaluation code can run. After passing the verification, click "Start Inference Evaluation" to proceed with the formal inference evaluation process. Wait for the evaluation to end to view the evaluation results. If there is any problem that causes termination and failure, the error message can be viewed through logs.

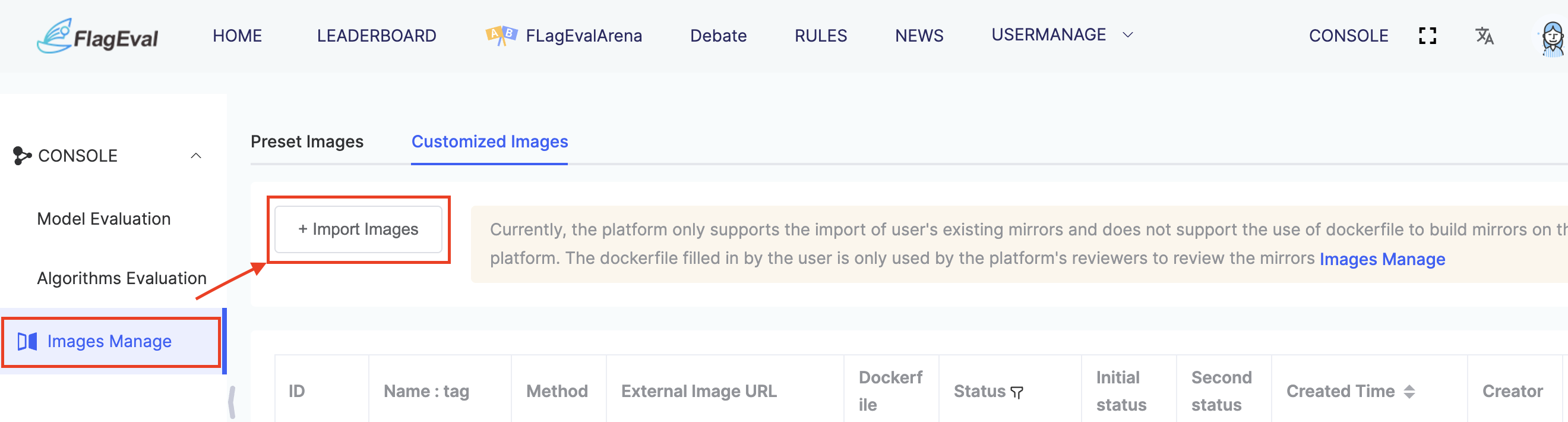
Upload Image
In [Image Management], several preset images are provided. If users need to use a custom image during actual evaluations, they can upload their own image under [Custom Image].
When users click [Image Management / Custom Image / Import Image], the [Import Image] dialog box will pop up. Users need to fill in and submit the form. After submission, the platform administrator will review it. Once approved, the image will be automatically imported. Only after a successful import can the image be used in evaluation tasks.
Currently, the platform only supports importing existing images. It does not support building images on the platform using a Dockerfile. The Dockerfile provided by the user is for review purposes only.
Auto-Evaluation
Introduction
Auto-Evaluation is a multi-chip compatible automatic model evaluation tool built on the Flageval platform. It covers three domains: LLM, VLM, and Embodied VLM, and is bound to classic datasets in corresponding fields. Currently, it only supports online evaluation. The tool provides interfaces for starting evaluations, checking evaluation progress, viewing evaluation results, stopping evaluations, resuming evaluations, and analyzing the differences in evaluation results across multiple chips. Whether you are an individual, a team, or an enterprise, as long as you launch the service on compute resources and support public network access, you can use this tool for automatic evaluation.
Tool Description
1、Address:
120.92.17.239:5050
2、Interface Overview
| Interface Name | Method | Description |
|---|---|---|
| /evaluation | POST | Start evaluation; invokes the uploaded service URL synchronously to begin model inference |
| /evaldiffs | GET | Query evaluation results |
| /stop_evaluation | POST | Stop evaluation; use this interface to pause if there are issues with the service |
| /resume_evaluation | POST | Resume evaluation; supports resuming from breakpoints |
| /evaluation_progress | POST | View evaluation progress; returns detailed information on completed evaluation status for each dataset |
| /evaluation_diffs | POST | View the differences of results between multiple models |
Detailed Interface Parameter Description
1. Start Evaluation
Request Interface
header
```json
"Content-Type": "application/json"
```
body:
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| eval_infos | EvalInfo[] | List of model evaluation service information | Yes |
| domain | string | Evaluation domain: NLP, MM | Yes |
| mode | string | Evaluation project identifier, having default value | No |
| region | string | Evaluation tool cluster: bj (default), sz | No |
| special_event | string | Whether it is a chip evaluation, default is yes | No |
| user_id | int | User ID on FlagEval platform | No |
EvalInfo Data Structure Parameters
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| eval_model | string | Name of the evaluation task to start, must be unique (to specify if the evaluation is an NVIDIA baseline model, please use xxx-nvidia-origin for naming) | Yes |
| model | string | The model used when the model is deployed as a service (multiple evaluations started with the same model will use the same cache) | Yes |
| eval_url | string | The evaluation interface for each deployed model service, e.g., http://10.1.15.153:9010/v1/chat/completions | Yes |
| tokenizer | string | Vendor and model information, e.g., Qwen/Qwen3-8B | Yes |
| api_key | string | API_KEY for model invocation, defaults to "EMPTY" | No |
| batch_size | int | The batch_size that the model can handle, defaults to 1 | No |
| num_concurrent | int | Number of concurrent requests, defaults to 1 | No |
| num_retry | int | Number of retries, defaults to 10 | No |
| gen_kwargs | string | Model parameters such as temperature, topn, etc., separated by commas e.g.: temperature=0.6,top_k=20,top_p=0.95,min_p=0 NLP uses max_gen_toks; for max_model_len of 16384, please set max_gen_toks=16000 MM and EV use the max_gen_toks field to specify | No |
| thinking | bool | Whether to enable the thinking model, currently only applicable to EmbodiedVerse's RoboBrain, defaults to False | No |
| retry_time | int | Timeout duration, currently supports MM and Embodied domains Current default is 3600s | No |
| chip | string | Name of the chip used for evaluation, format: Vendor-ChipName Default is: Nvidia-H100 | No |
| base_model_name | string | Base model used for evaluation, e.g.: Qwen3-8B | No |
Response Data
Note: Since model evaluation takes a long time, the interface temporarily returns the corresponding evaluation ID and batch ID, which can be used to query evaluation results later.
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| err_code | int | Whether the request was processed correctly, 0 for success, 1 for failure; if 1, request_id is not included in return data | Yes |
| err_msg | string | Request processing message | Yes |
| request_id | string | Unique Identifier | Yes |
| eval_tasks | EvalTask[] | Detailed information on evaluations started for each service | Yes |
2. View Evaluation Results
Request Interface
header
```bash
"Content-Type": "application/json"
```
body:
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| request_id | string | Unique identifier | Yes |
Response Data
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| err_code | int | Whether the request was processed correctly, 0 for success, 1 for failure | Yes |
| err_message | string | Request processing message | Yes |
| eval_results | EvalResultMap | Evaluation result information for each service |
EvalResultMap Data Structure
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| EvalResultMap | Map<string, EvalResult> | Evaluation results for all models in one run | Yes |
| EvalResultMap.key | string | The eval_model corresponding to the started evaluation | Yes |
| EvalResultMap.value | EvalResult[] | Evaluation results for a single model | Yes |
EvalResult Data Structure
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| status | string | Evaluation status. e.g.: S: Success, F: Failure, C: Cancelled, OOR: Out of Retries | Yes |
| details | Detail[] | Evaluation results for each dataset of the corresponding evaluation service (currently only supports mmlu, gsm8k) | Yes |
| release | bool | Whether the model can be released, if the diff is within acceptable range | Yes |
Detail Data Structure
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| dataset | string | Dataset name | Yes |
| status | string | Running status of the corresponding evaluation service, e.g.: S: Success, F: Failure, C: Cancelled | Yes |
| accuracy | float | Dataset evaluation result | Yes |
| diff | float | Difference between dataset evaluation result and NVIDIA baseline | Yes |
3. Stop Evaluation
Request Interface
header
```bash
"Content-Type": "application/json"
```
body
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| request_id | string | Unique Identifier | Yes |
Response Data
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| err_code | int | Whether the request was processed correctly, 0 for success, 1 for failure | Yes |
| err_message | string | Request processing message | Yes |
4. Resume Evaluation
Request Interface
header
```bash
"Content-Type": "application/json"
```
body:
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| request_id | string | Unique Identifier | Yes |
Response Data
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| err_code | int | Whether the request was processed correctly, 0 for success, 1 for failure | Yes |
| err_message | string | Request processing message | Yes |
5. Query Evaluation Progress
Request Interface
header
```bash
"Content-Type": "application/json"
```
body:
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| request_id | string | Unique Identifier | Yes |
| domain | string | Evaluation domain (NLP, MM) | Yes |
Response Data
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| err_code | int | Whether the request was processed correctly, 0 for success, 1 for failure | Yes |
| err_message | string | Request processing message | Yes |
| finished | bool | Whether evaluation is finished | Yes |
| status | string | Evaluation status | Yes |
| datasets_progress | string | Dataset progress | Yes |
| running_dataset | string | Currently running dataset | Yes |
| running_progress | string | Evaluation progress within the running dataset | Yes |
6. Query Evaluation Differences
Request Interface
header
```bash
"Content-Type": "application/json"
```
body:
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| request_ids | string[] | Unique Identifier | Yes |
Response Data
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| err_code | int | Whether the request was processed correctly, 0 for success, 1 for failure | Yes |
| err_message | string | Request processing message | Yes |
| eval_diffs | EvalDiff[] | List of evaluation result comparisons | Yes |
EvalDiff Data Structure
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| request_id | string | UUID of the evaluated record | Yes |
| details | Detail[] | Detailed comparison data for each dataset | Yes |
| release | bool | Whether release conditions are met | Yes |
Detail Data Structure
| Parameter Name | Type | Description | Required |
|---|---|---|---|
| dataset | string | Dataset name | Yes |
| base_acc | float | Baseline score | Yes |
| accuracy | float | Score of evaluated dataset | Yes |
| diff | float | Difference between evaluated dataset and baseline dataset | Yes |