

Evaluation Data
MuSR
Data Description:
MuSR (Multistep Soft Reasoning) is a multistep reasoning assessment set where each question contains longer (around a thousand words) natural text descriptions of three types: who is the culprit, object location, and team task assignment.
There are a total of 756 test data.
Sample (simplified) source dataset:
{
"context": "In an adrenaline inducing bungee jumping site, Mack's thrill-seeking adventure came to a gruesome end by a nunchaku ...",
"questions": [{"question": "Who is the most likely murderer?", "choices": ["Mackenzie", "Ana"]}]
}paper citation:
MuSR: https://arxiv.org/abs/2310.16049
@inproceedings{
sprague2024musr,
title={Mu{SR}: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning},
author={Zayne Rea Sprague and Xi Ye and Kaj Bostrom and Swarat Chaudhuri and Greg Durrett},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=jenyYQzue1}
}HellaSwag
HellaSwag: https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/tasks/hellaswag/README.md
Data description:
Questions like the above are trivial to humans, with over 95% accuracy, but current state-of-the-art NLP models built on pretraining struggle with under 48% accuracy. We achieve this via Adversarial Filtering (AF), a data collection paradigm wherein a series of discriminators iteratively select an adversarial set of machine-generated wrong answers. AF proves to be surprisingly robust. The key insight is to scale up the length and complexity of the dataset examples towards a critical 'Goldilocks' zone wherein generated text is ridiculous to humans, yet often misclassified by state-of-the-art models.
Our construction of HellaSwag, and its resulting difficulty, sheds light on the inner workings of deep pretrained models. More broadly, it suggests a new path forward for NLP research, in which benchmarks co-evolve with the evolving state-of-the-art in an adversarial way, so as to present ever-harder challenges.
paper citation:
HellaSwag: https://arxiv.org/abs/1905.07830
@inproceedings{zellers2019hellaswag,
title={HellaSwag: Can a Machine Really Finish Your Sentence?},
author={Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin},
booktitle ={Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics},
year={2019}
}Dataset Copyright and Usage Instructions:
MIT License
Copyright (c) 2019 Rowan Zellers
BBH
BBH:https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/tasks/bbh/README.md
Data description:
BIG-Bench (Srivastava et al., 2022) is a diverse evaluation suite that focuses on tasks believed to be beyond the capabilities of current language models. Language models have already made good progress on this benchmark, with the best model in the BIG-Bench paper outperforming average reported human-rater results on 65% of the BIG-Bench tasks via few-shot prompting. But on what tasks do language models fall short of average human-rater performance, and are those tasks actually unsolvable by current language models?
In this work, we focus on a suite of 23 challenging BIG-Bench tasks which we call BIG-Bench Hard (BBH). These are the task for which prior language model evaluations did not outperform the average human-rater. We find that applying chain-of-thought (CoT) prompting to BBH tasks enables PaLM to surpass the average humanrater performance on 10 of the 23 tasks, and Codex (code-davinci-002) to surpass the average human-rater performance on 17 of the 23 tasks. Since many tasks in BBH require multi-step reasoning, few-shot prompting without CoT, as done in the BIG-Bench evaluations (Srivastava et al., 2022), substantially underestimates the best performance and capabilities of language models, which is better captured via CoT prompting. As further analysis, we explore the interaction between CoT and model scale on BBH, finding that CoT enables emergent task performance on several BBH tasks with otherwise flat scaling curves.
Sample question for the source dataset:
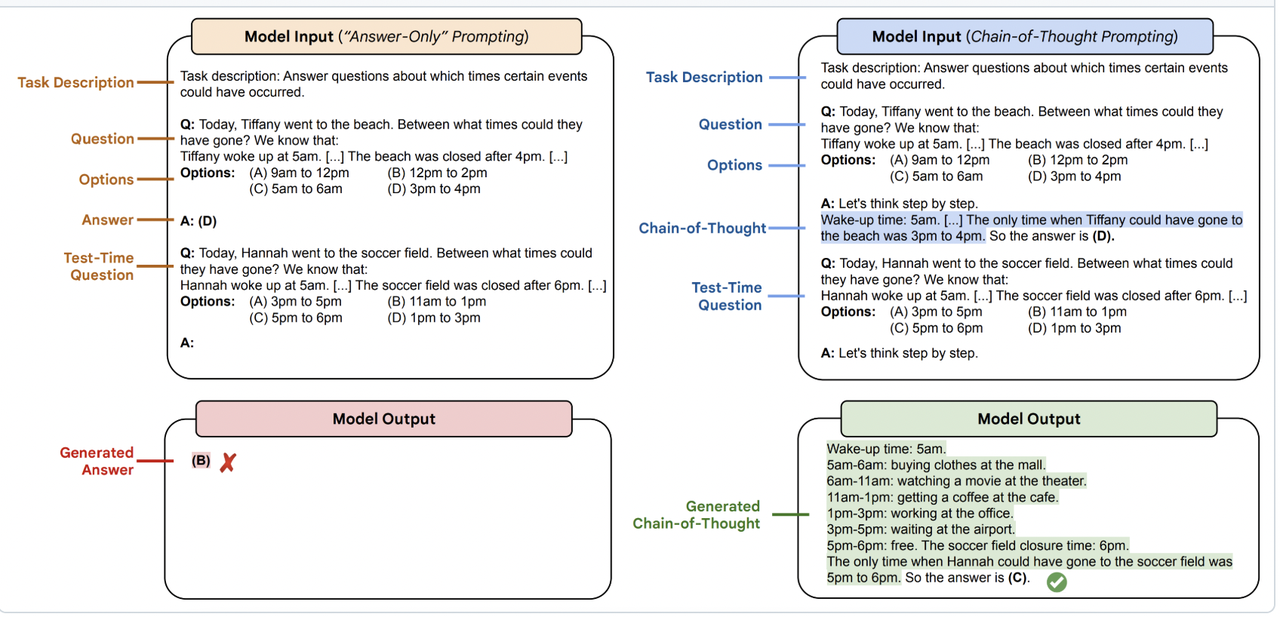
paper citation:
BBH: https://arxiv.org/abs/2210.09261
BIG Bench (Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models (Srivastava et al., 2022))
@article{srivastava2022beyond,
title={Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models},
author={Srivastava, Aarohi and Rastogi, Abhinav and Rao, Abhishek and Shoeb, Abu Awal Md and Abid, Abubakar and Fisch, Adam and Brown, Adam R and Santoro, Adam and Gupta, Aditya and Garriga-Alonso, Adri{\`a} and others},
journal={arXiv preprint arXiv:2206.04615},
year={2022}
}BIG-Bench Hard (Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them (Suzgun et al., 2022))
@article{suzgun2022challenging,
title={Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them},
author={Suzgun, Mirac and Scales, Nathan and Sch{\"a}rli, Nathanael and Gehrmann, Sebastian and Tay, Yi and Chung, Hyung Won and Chowdhery, Aakanksha and Le, Quoc V and Chi, Ed H and Zhou, Denny and and Wei, Jason},
journal={arXiv preprint arXiv:2210.09261},
year={2022}
}Dataset Copyright and Usage Instructions:
MIT License
Copyright (c) 2022 suzgunmirac