

Evaluation Data
LiveCodeBench
Metrics Description:
The model generates k (k=1,10,100) code samples for each unit test problem, and if any of the samples pass the unit test, the problem is considered solved and the total percentage of problems solved is reported as the Pass@k score. Note: In actual testing, it is common practice to sample n=200 times and pass c times, using 1-C(k, n-c)/C(k, n) to reduce the variance of the rubric.
Data Description.
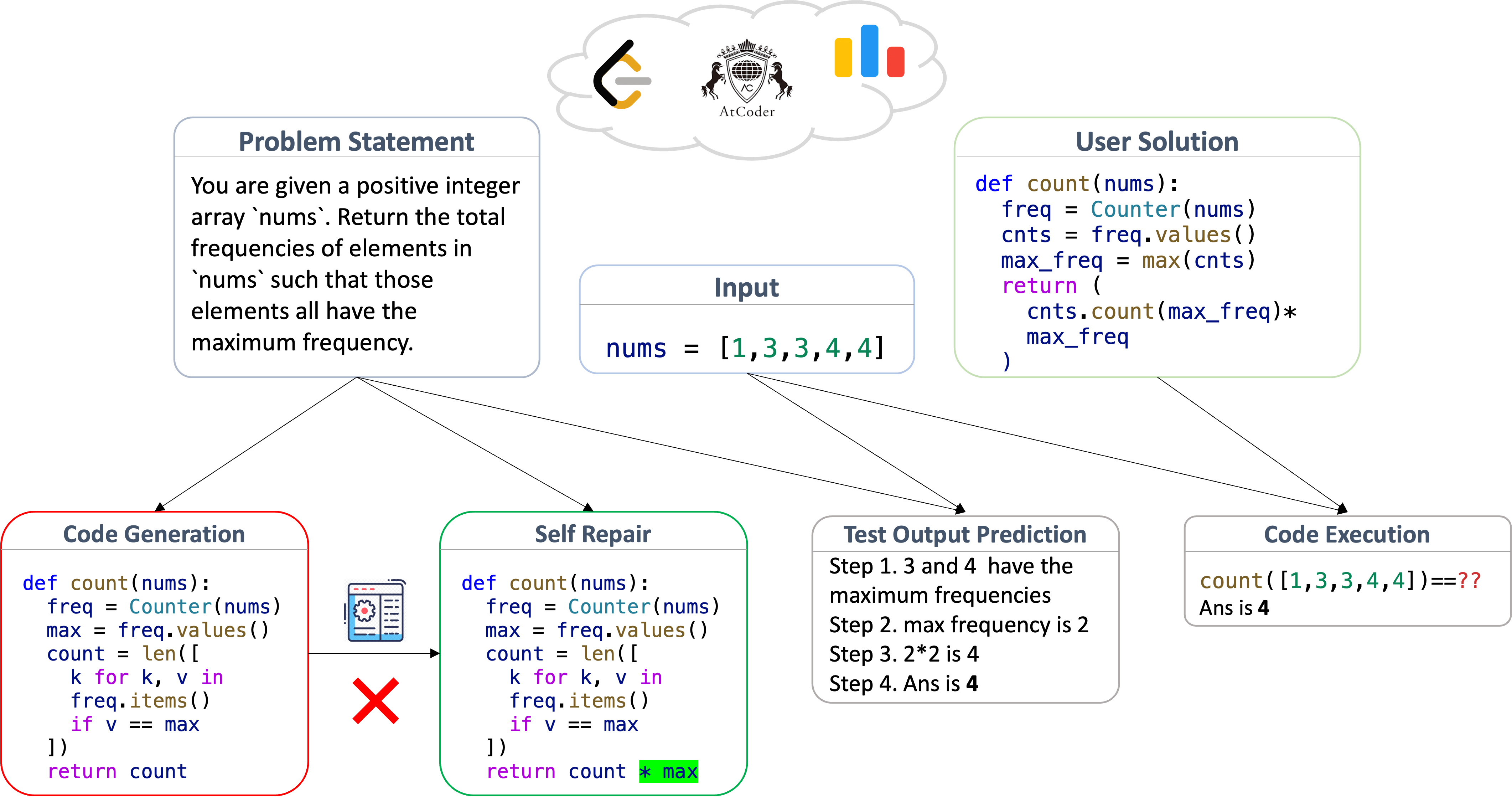
LiveCodeBench contains four tasks:
code generation:the most typical coding competence task ( earlier sets are also available); this data is taken from LeetCode, AtCoder and Codeforces new questions.
self-repair:fixing code based on error messages generated by executing the original code.
code execution:given a function code segment, predict the execution result based on the actual parameters passed in, as a way to test code comprehension.
test output prediction:Predict the corresponding output results based on natural language descriptions and specified inputs.
Dataset Composition and Specification:
Assessment Data Volume:
- code generation(code generation):500 questions, taken from LeetCode, AtCoder and Codeforces.
- self-repair(self-repair):This term is temporarily skipped in this review due to its strong correlation with the first round of model-specific self-reported code, and for uniformity reasons.
- code execution(code execution):479 questions.
- test output prediction(test output prediction):442 output prediction questions from LeetCode questions.
Sample source dataset:
{
<!-- Task: "execution", -->
"code": "def distinctDifferenceArray(a: List[int]) -> List[int]: return [len(set(a[:i+1]))-len(set(a[i+1:]))for i in range(len(a))]",
"input": "distinctDifferenceArray(a = [1, 2, 3, 4, 5])",
"difficulty": "easy"
}
{
<!-- Task: "test generation (test output prediction)", -->
"starter_code": "def countSeniors(self, details: List[str]) -> int: pass",
"question_content": "You are given a 0-indexed array of strings details. Each element of details provides information about a given passenger compressed into a string of length 15. The system is such that: The first ten characters consist of the phone number of passengers. The next character denotes the gender of the person. The following two characters are used to indicate the age of the person. The last two characters determine the seat allotted to that person. Return the number of passengers who are strictly more than 60 years old.",
"input": "[\"7868190130M7522\", \"5303914400F9211\", \"9273338290F4010\"]",
"difficulty": "easy"
}paper citation:
LiveCodeBench: https://arxiv.org/abs/2403.07974
@misc{jain2024livecodebenchholisticcontaminationfree,
title={LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code},
author={Naman Jain and King Han and Alex Gu and Wen-Ding Li and Fanjia Yan and Tianjun Zhang and Sida Wang and Armando Solar-Lezama and Koushik Sen and Ion Stoica},
year={2024},
eprint={2403.07974},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2403.07974},
}Dataset copyright usage instructions:
cc
BIRD
#Evaluation Indicators-Execution-Accuracy
Data Description.
BIRD (BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation) is a text-to-SQL generated dataset released in 2023.
Dataset Composition and Specification:
Data Volume:
A total of 12,751 sets of paired questions and SQL across 95 large databases (33.4 GB) covering 37 professional domains such as blockchain, hockey, healthcare, education, and more.
Evaluation data volume:
15 of the databases were not publicly available for evaluation purposes, and the test data included a total of 1,789 questions.
Paper Citation:
BIRD: https://arxiv.org/abs/2305.03111
@inproceedings{li2024BIRD,
author = {Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Geng, Ruiying and Huo, Nan and Zhou, Xuanhe and Chenhao, Ma and Li, Guoliang and Chang, Kevin and Huang, Fei and Cheng, Reynold and Li, Yongbin},
booktitle = {Advances in Neural Information Processing Systems},
pages = {42330--42357},
title = {Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs},
volume = {36},
year = {2023}
}Dataset copyright usage instructions:
CC BY-SA 4.0