

评测数据
LiveCodeBench
指标说明:
模型针对每个单元测试问题生成k(k=1,10,100)个代码样本,如果有任何样本通过单元测试,则认为问题已解决,并报告问题解决的总比例,即 Pass@k 得分。注:实际测试中,一般的做法是采样n=200次,通过c次,用1-C(k, n-c)/C(k, n)来降低评测值的方差。
数据描述:
LiveCodeBench包含四个任务:
- 代码生成(code generation):最典型的代码能力评测任务(亦可参见早前评测集);本数据取自LeetCode、AtCoder和Codeforces新题
- 代码修正(self-repair):根据执行原始代码产生的报错信息修正代码
- 代码执行(code execution):给定函数代码段,根据实际传入的参数预测执行结果,以此考察代码理解能力
- 测试输出预测(test output prediction):根据自然语言描述和指定输入,预测对应的输出结果
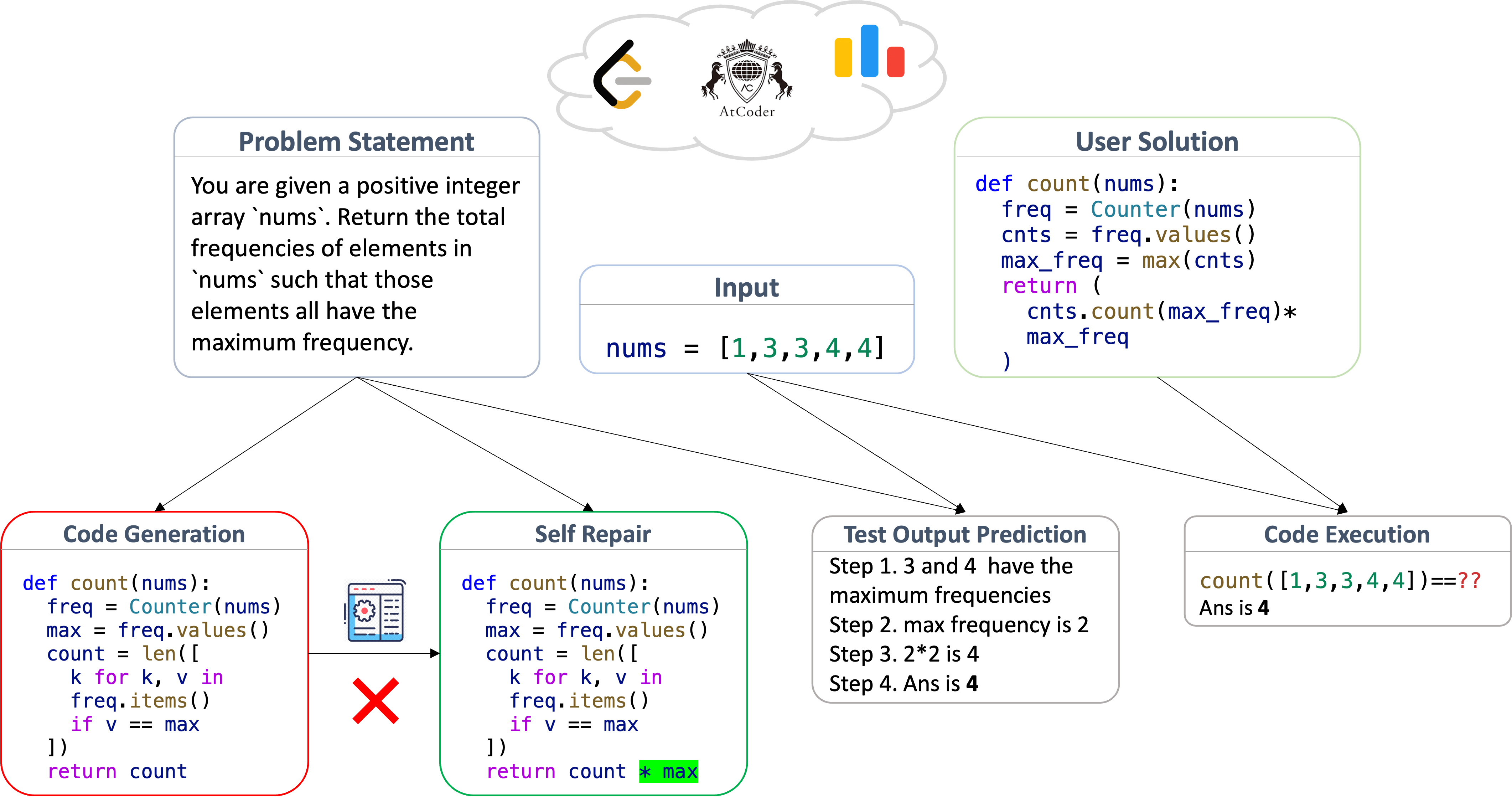
数据集构成和规范:
评测数据量:
- 代码生成(code generation):500题,取自LeetCode、AtCoder和Codeforces新题
- 代码修正(self-repair):(因与具体模型首轮自行输出的代码强相关,考虑统一性,本期评测暂时跳过此项)
- 代码执行(code execution):479题
- 测试输出预测(test output prediction):源自LeetCode问题的442条输出预测题
源数据集样例:
{
<!-- 任务: "execution", -->
"code": "def distinctDifferenceArray(a: List[int]) -> List[int]: return [len(set(a[:i+1]))-len(set(a[i+1:]))for i in range(len(a))]",
"input": "distinctDifferenceArray(a = [1, 2, 3, 4, 5])",
"difficulty": "easy"
}
{
<!-- 任务: "test generation (test output prediction)", -->
"starter_code": "def countSeniors(self, details: List[str]) -> int: pass",
"question_content": "You are given a 0-indexed array of strings details. Each element of details provides information about a given passenger compressed into a string of length 15. The system is such that: The first ten characters consist of the phone number of passengers. The next character denotes the gender of the person. The following two characters are used to indicate the age of the person. The last two characters determine the seat allotted to that person. Return the number of passengers who are strictly more than 60 years old.",
"input": "[\"7868190130M7522\", \"5303914400F9211\", \"9273338290F4010\"]",
"difficulty": "easy"
}论文引用:
LiveCodeBench: https://arxiv.org/abs/2403.07974
@misc{jain2024livecodebenchholisticcontaminationfree,
title={LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code},
author={Naman Jain and King Han and Alex Gu and Wen-Ding Li and Fanjia Yan and Tianjun Zhang and Sida Wang and Armando Solar-Lezama and Koushik Sen and Ion Stoica},
year={2024},
eprint={2403.07974},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2403.07974},
}数据集版权使用说明:
cc
BIRD
数据描述:
BIRD (BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation)是2023年发布的文本到SQL生成数据集。
数据集构成和规范:
数据量:
总计12,751组配对的问题与SQL,涉及95个大型数据库(33.4 GB),覆盖区块链、曲棍球、医疗、教育等37个专业领域。
评测数据量:
其中15个数据库并未公开,作为评测用途,测试数据包括共计1,789条问题。
论文引用:
BIRD: https://arxiv.org/abs/2305.03111
@inproceedings{li2024BIRD,
author = {Li, Jinyang and Hui, Binyuan and Qu, Ge and Yang, Jiaxi and Li, Binhua and Li, Bowen and Wang, Bailin and Qin, Bowen and Geng, Ruiying and Huo, Nan and Zhou, Xuanhe and Chenhao, Ma and Li, Guoliang and Chang, Kevin and Huang, Fei and Cheng, Reynold and Li, Yongbin},
booktitle = {Advances in Neural Information Processing Systems},
pages = {42330--42357},
title = {Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs},
volume = {36},
year = {2023}
}数据集版权使用说明:
CC BY-SA 4.0