

评测数据
MuSR
数据描述:
MuSR (Multistep Soft Reasoning)是一个多步推理评测集,每个问题包含篇幅较长(千字左右)的自然文字描述,有三种类型:谁是凶手、物体位置、团队任务分配。
共756条测试数据。
源数据集样例(简化):
{
"context": "In an adrenaline inducing bungee jumping site, Mack's thrill-seeking adventure came to a gruesome end by a nunchaku ...",
"questions": [{"question": "Who is the most likely murderer?", "choices": ["Mackenzie", "Ana"]}]
}论文引用:
MuSR: https://arxiv.org/abs/2310.16049
@inproceedings{
sprague2024musr,
title={Mu{SR}: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning},
author={Zayne Rea Sprague and Xi Ye and Kaj Bostrom and Swarat Chaudhuri and Greg Durrett},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=jenyYQzue1}
}HellaSwag
HellaSwag: https://github.com/EleutherAI/lm-evaluation-harness/blob/main/lm_eval/tasks/hellaswag/README.md
数据描述:
像上述这类题目对人类来说是非常简单的,正确率超过 95%,但当前基于预训练的最先进 NLP 模型在这类任务上的表现却不到 48% 的准确率。我们通过对抗性筛选(Adversarial Filtering, AF)实现了这一点,AF 是一种数据收集范式,通过一系列判别器迭代地筛选出一组具有对抗性的机器生成错误答案。实践证明,AF 方法具有出人意料的鲁棒性。其关键洞见在于:通过扩展数据集示例的长度和复杂度,将其调整到一个关键的“恰到好处(Goldilocks)”区间,在该区间内,生成的文本对人类而言显得荒谬,但却常常被最先进的模型误判。
我们对 HellaSwag 数据集的构建过程以及其由此带来的高难度表现,揭示了深度预训练模型内部的工作机制。更广义地说,这也为 NLP 研究指出了一条新的前进方向:基准测试可以与不断演进的最先进模型以对抗的方式共同演进,从而持续提出更具挑战性的任务。
源数据集问题样例:
论文引用:
https://arxiv.org/abs/1905.07830
@inproceedings{zellers2019hellaswag,
title={HellaSwag: Can a Machine Really Finish Your Sentence?},
author={Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin},
booktitle ={Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics},
year={2019}
}数据许可说明:
MIT License
Copyright (c) 2019 Rowan Zellers
BBH
数据描述:
BIG-Bench(Srivastava 等,2022)是一个多样化的评估套件,专注于那些被认为超出当前语言模型能力范围的任务。尽管如此,语言模型在该基准上的表现已有显著进步,在 BIG-Bench 论文中,最佳模型通过少样本提示在 65% 的 BIG-Bench 任务上超越了平均人类评分者的表现。
但问题是,在哪些任务上语言模型仍然无法超越平均人类评分者的表现?这些任务是否真的是当前语言模型无法解决的?
在本研究中,我们聚焦于一组 23 个具有挑战性的 BIG-Bench 任务,称为 BIG-Bench Hard(BBH)。这些任务是在以往的语言模型评估中未能超越平均人类评分者表现的任务。我们的研究发现,通过对 BBH 任务应用 思维链提示,PaLM 模型在 23 个任务中的 10 个任务上超越了平均人类评分者的表现,Codex(code-davinci-002) 则在 23 个任务中的 17 个任务上取得了超越。
由于 BBH 中的许多任务需要多步推理,直接使用不带思维链的少样本提示(正如 BIG-Bench 评估中所采用的方法)会显著低估语言模型的最佳性能与潜力,而这种潜力通过 CoT 提示 能够更好地展现出来。
进一步分析中,我们还探讨了 CoT 提示与模型规模在 BBH 任务中的交互作用,发现 CoT 能够在若干 BBH 任务上激发出原本呈现平缓扩展曲线的任务表现出现涌现性提升。
源数据集问题样例:
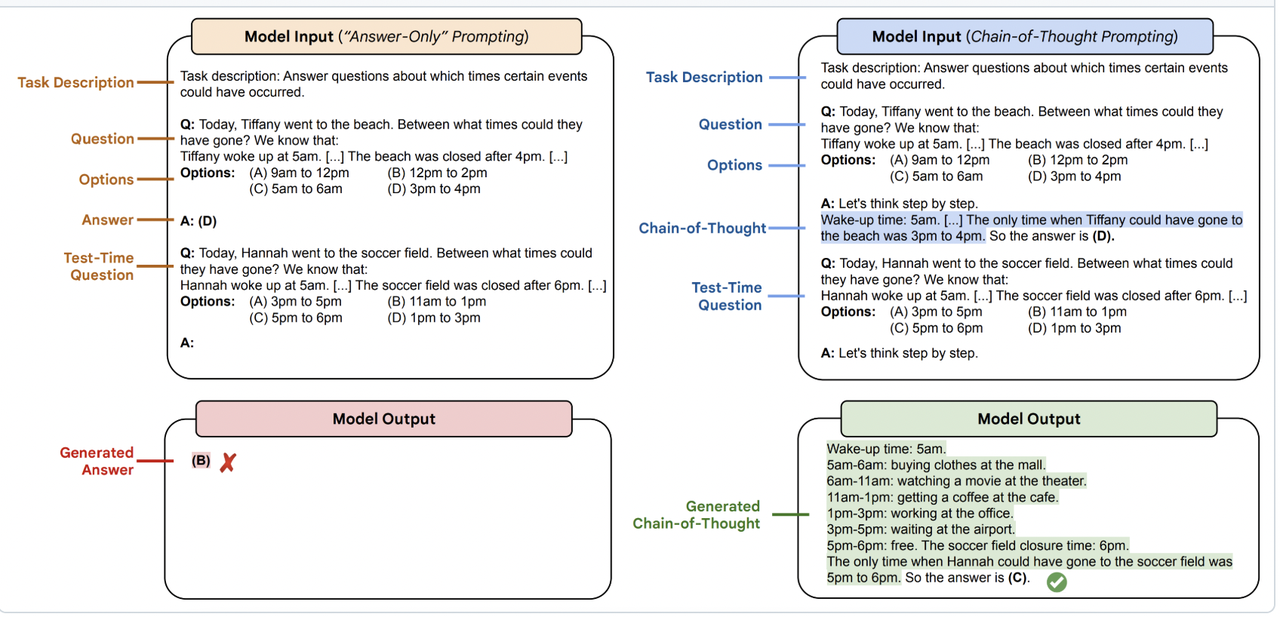
论文引用:
https://arxiv.org/abs/2210.09261
BIG Bench (Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models (Srivastava et al., 2022))
@article{srivastava2022beyond,
title={Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models},
author={Srivastava, Aarohi and Rastogi, Abhinav and Rao, Abhishek and Shoeb, Abu Awal Md and Abid, Abubakar and Fisch, Adam and Brown, Adam R and Santoro, Adam and Gupta, Aditya and Garriga-Alonso, Adri{\`a} and others},
journal={arXiv preprint arXiv:2206.04615},
year={2022}
}BIG-Bench Hard (Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them(Suzgun et al., 2022))
@article{suzgun2022challenging,
title={Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them},
author={Suzgun, Mirac and Scales, Nathan and Sch{\"a}rli, Nathanael and Gehrmann, Sebastian and Tay, Yi and Chung, Hyung Won and Chowdhery, Aakanksha and Le, Quoc V and Chi, Ed H and Zhou, Denny and and Wei, Jason},
journal={arXiv preprint arXiv:2210.09261},
year={2022}
}数据许可说明:
MIT License
winogrande
数据描述:
WinoGrande 是一个针对常识推理的大规模多选题问答数据集,旨在评估机器对常识知识的深度理解和抗偏见能力。其设计灵感源于经典的 Winograd Schema Challenge (WSC),包含 44,000个问题,远超WSC的273个问题,覆盖更复杂的语义场景。
源数据集样例(简化):
{
"id": "example_123",
"sentence": "The sanctions hurt the school's reputation, as they seemed to _ its efforts to improve.",
"option1": "ignore",
"option2": "support",
"answer": "ignore",
"question_concept": "punishment"
}论文引用:
@article{sakaguchi2019winogrande,
title={WinoGrande: An Adversarial Winograd Schema Challenge at Scale},
author={Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin},
journal={arXiv preprint arXiv:1907.10641},
year={2019}
}arXiv:1907.10641
数据集版权使用说明:
MIT License
commonsense_qa
数据描述:
CommonsenseQA 是一个旨在评估模型常识推理能力的多项选择题问答数据集。它包含大约 12,102 个问题,每个问题有 5 个候选答案,需要不同类型的常识知识才能正确回答。数据集主要有两个划分:"Random split"(随机划分),这是主要的评估划分,以及 "Question token split"(问题标记划分)。
源数据集样例(简化):
{
"id": "075e483d21c29a511267ef62bedc0461",
"question": "The sanctions against the school were a punishing blow, and they seemed to what the efforts the school had made to change?",
"question_concept": "punishing",
"choices": {
"label": ["A", "B", "C", "D", "E"],
"text": ["ignore", "enforce", "authoritarian", "yell at", "avoid"]
},
"answerKey": "A"
}论文引用:
@inproceedings{talmor-etal-2019-commonsenseqa,
title = "{C}ommonsense{QA}: A Question Answering Challenge Targeting Commonsense Knowledge",
author = "Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan",
booktitle = "NAACL-HLT 2019",
year = "2019",
url = "https://arxiv.org/abs/1811.00937"
}数据集版权使用说明:
MIT license
piqa
数据描述:
任务类型为二选一物理常识选择题,数据规模包括:16,113训练样本 / 1,838验证样本 / 1,838测试样本,覆盖日常物理交互场景(如食物保存、物体稳定性等)。每个问题包含goal(目标)和两个解决方案(sol1/sol2)
源数据集样例(简化):
{
"id": "07e9e52121df8b0d",
"goal": "Cool down a hot bowl of soup",
"sol1": "Put it in the freezer",
"sol2": "Blow air over the top with a fan",
"label": 1,
"correct": "sol2" # 风扇加速蒸发散热更有效
}论文引用:
@inproceedings{bisk2020piqa,
title={PIQA: Reasoning about Physical Commonsense in Natural Language},
author={Bisk, Yonatan and Zellers, Rowan and Bras, Ronan Le and Gao, Jianfeng and Choi, Yejin},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={34},
number={05},
pages={7432--7439},
year={2020}
}数据集版权使用说明:
Apache License 2.0
openbookqa
数据描述:
由 Allen Institute for AI (AI2) 开发,旨在评估机器在开放书籍问答(Open Book QA)任务中的推理能力。数据集包含 5,957 个四选一科学常识问题(训练集 4,957,验证集 500,测试集 500),并附带 1,326 个核心科学事实(作为“开放书籍”背景知识)。并提供扩展数据,提供 5,167 个众包常识知识,增强模型推理能力。问题需要进行多步推理问答,需结合 给定科学事实 + 外部常识知识 才能正确回答。 源数据集样例(简化):
{
"id": "7-980", "question_stem": "The sun is responsible for", "choices": {"text": ["A", "B", "C", "D"], "label": [...]}, "answerKey": "D", "fact1": "the sun is the source of energy...", # 核心科学事实 "humanScore": 1.0, # 人类标注准确率 "clarity": 2.0 # 问题清晰度评分
}问题:The sun is responsible for
选项:
A. puppies learning new tricks
B. children growing up and getting old
C. flowers wilting in a vase
D. plants sprouting, blooming and wilting
答案:D
核心事实:the sun is the source of energy for physical cycles on Earth
论文引用:
@inproceedings{OpenBookQA2018, title={Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering}, author={Mihaylov, Todor and Clark, Peter and Khot, Tushar and Sabharwal, Ashish}, booktitle={EMNLP}, year={2018}
}https://arxiv.org/abs/1809.02789
数据集版权使用说明:
Apache License Version 2.0