

#Evaluation Data (Semantic Segmentation)
ADE20K
Data description:
The ADE20K semantic segmentation dataset contains more than 20K scene-centric images exhaustively annotated with pixel-level objects and object parts labels. There are totally 150 semantic categories, which include stuffs like sky, road, grass, and discrete objects like person, car, bed.
Dataset structure:
Amount of source data:
The dataset is split into train(18,210), validation(2,000), test(2,000)
Data detail:
Raw image:RGB image
Semantic segmentation map:Gray image
Sample of source dataset:
Raw image:

Semantic segmentation map:

Citation information:
@article{zhou2019semantic,
title={Semantic understanding of scenes through the ade20k dataset},
author={Zhou, Bolei and Zhao, Hang and Puig, Xavier and Xiao, Tete and Fidler, Sanja and Barriuso, Adela and Torralba, Antonio},
journal={International Journal of Computer Vision},
volume={127},
pages={302--321},
year={2019},
publisher={Springer}
}Licensing information:
Cityscapes
Data description:
Cityscapes is a large-scale database which focuses on semantic understanding of urban street scenes. It provides semantic, instance-wise, and dense pixel annotations for 30 classes grouped into 8 categories (flat surfaces, humans, vehicles, constructions, objects, nature, sky, and void). The dataset consists of around 5,000 fine annotated images and 20,000 coarse annotated ones. Data was captured in 50 cities during several months, daytimes, and good weather conditions. It was originally recorded as video so the frames were manually selected to have the following features: large number of dynamic objects, varying scene layout, and varying background.
Dataset structure:
Amount of source data:
The dataset is split into train(2,469), validation(506), test(500)
Data detail:
Raw image:RGB image
Semantic segmentation map:Gray image
Sample of source dataset:
Raw image:

Semantic segmentation map:
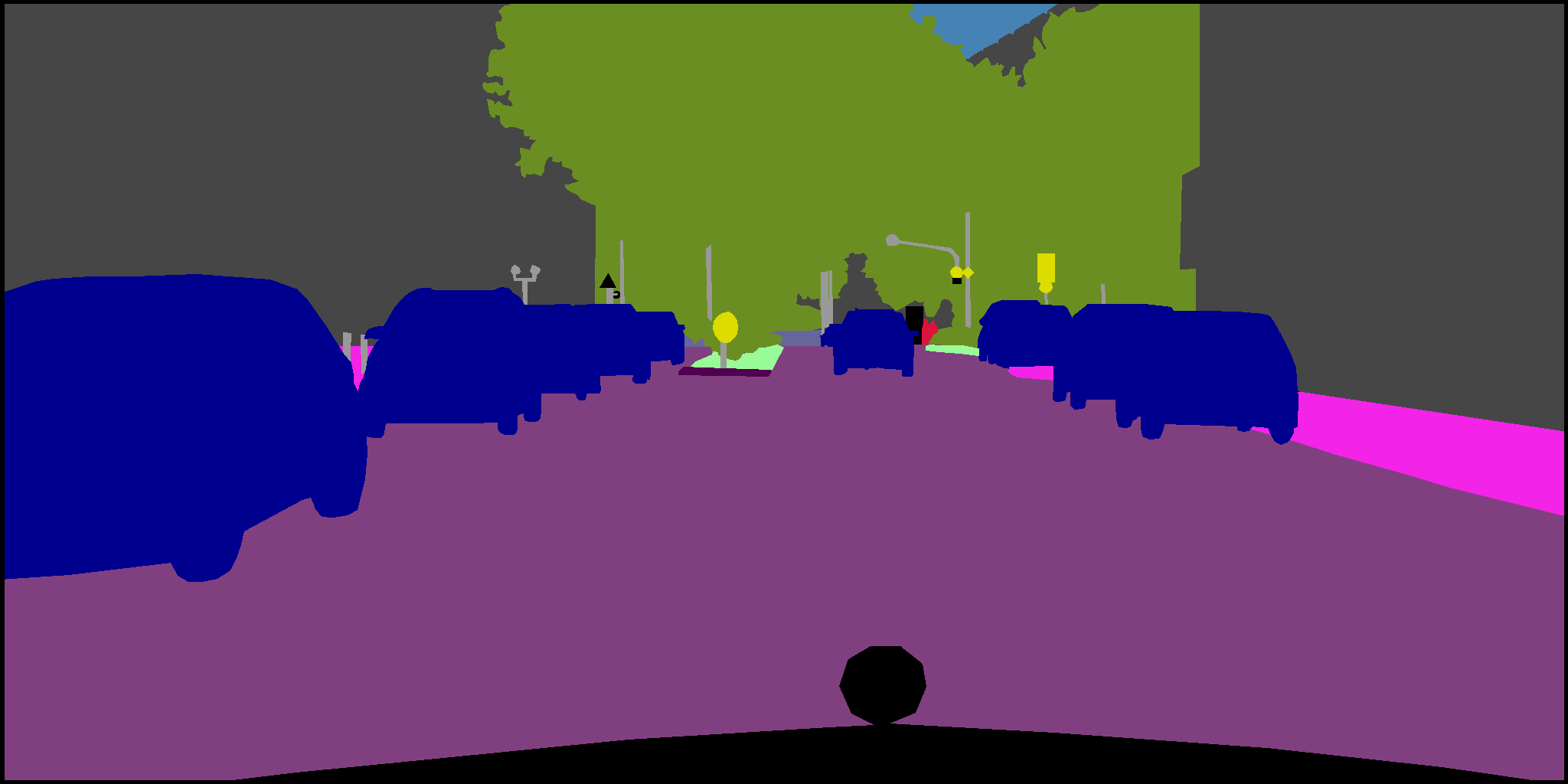
Citation information:
@inproceedings{cordts2016cityscapes,
title={The cityscapes dataset for semantic urban scene understanding},
author={Cordts, Marius and Omran, Mohamed and Ramos, Sebastian and Rehfeld, Timo and Enzweiler, Markus and Benenson, Rodrigo and Franke, Uwe and Roth, Stefan and Schiele, Bernt},
booktitle={Computer Vision and Pattern Recognition},
pages={3213--3223},
year={2016}
}Licensing information:
COCO-Stuff
Data description:
The Common Objects in COntext-stuff (COCO-stuff) dataset is a dataset for scene understanding tasks like semantic segmentation, object detection and image captioning. It is constructed by annotating the original COCO dataset, which originally annotated things while neglecting stuff annotations. There are 164K images in COCO-stuff dataset that span over 172 categories including 80 things, 91 stuff, and 1 unlabeled class.
Dataset structure:
Amount of source data:
The dataset is split into train(8K), validation(1K), test(1K)
Data detail:
Raw image:RGB image
Semantic segmentation map:Gray image
Sample of source dataset:
Raw image:

Semantic segmentation map:

Citation information:
@inproceedings{caesar2018coco,
title={Coco-stuff: Thing and stuff classes in context},
author={Caesar, Holger and Uijlings, Jasper and Ferrari, Vittorio},
booktitle={Computer Vision and Pattern Recognition},
pages={1209--1218},
year={2018}
}