

Evaluation Metrics
Answer Input Format
results = [result]
result{
"question_id": int,
"answer": str
}Data Processing
Before evaluating machine generated answers, we do the following processing: 1. Making all characters lowercase 2. Removing periods except if it occurs as decimal 3. Converting number words to digits 4. Removing articles (a, an, the) 5. Adding apostrophe if a contraction is missing it (e.g., convert "dont" to "don't") 6. Replacing all punctuation (except apostrophe and colon) with a space character.
1. Accuracy
For VQA2.0 and VQA-CP datasets, we use the standard evaluation metrics of the VQA dataset for evaluation. In both datasets, each question has 10 gt answers provided by 10 different subjects, and in order to be consistent with "human accuracy", machine accuracies are averaged over all 10 choose 9 sets of human annotators:
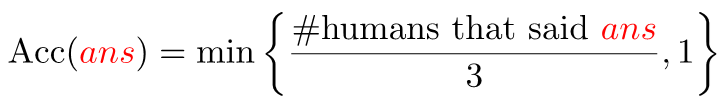
2. MPT Accuracy
Mean-per-type accuracy (MPT) is a standard evaluation method for TDIUC dataset. This metric can handle unbalanced problem type distribution. The overall metrics are the arithmetic and harmonic means across all per question-type accuracies, referred to as arithmetic mean-per-type (Arithmetic MPT) accuracy and harmonic mean-per-type accuracy (Harmonic MPT). Unlike the Arithmetic MPT, Harmonic MPT measures the ability of a system to have high scores across all question-types and is skewed towards lowest performing categories.
It also uses normalized metrics that compensate for bias in the form of imbalance in the distribution of answers within each question-type. To do this, it computes the accuracy for each unique answer separately within a question-type and then average them together for the question-type. To compute overall performance, it computes the arithmetic normalized mean per-type (N-MPT) and harmonic N-MPT scores. A large discrepancy between unnormalized and normalized scores suggests an algorithm is not generalizing to rarer answers.
CSV format
Calculating the MPT metric for the TDIUC dataset requires providing a csv file of model-predicted answers, giving each answer a unique id. The first column of the file is the answer, and the second column is the answer corresponding id:
raining 251
hats 784
yellow 13
...A sample answerkey file has been provided in the dataset, or you can choose to used your own csv file. Make sure the file should follow similar format and contain all the predicted answers.
3. WUPS
Wu-Palmer Similarity (WUPS) evaluates the difference between the answers predicted by the model and the ground truth answers available in the dataset, depending on the difference in their semantic connotation in Wordnet. Based on the similarity between them, WUPS will assign a value between 0 and 1 based on the ground truth answer in the dataset and the model's predicted answer to the question:
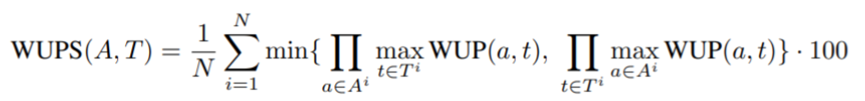
The WUPS metric has certain limitations. Firstly, some words may be very similar linguistically but can have significantly different meanings. Another limitation is that WUPS cannot be applied to answers in the form of phrases or sentences because it typically deals with rigid semantic concepts (those found in WordNet), which are most likely single words. Therefore, for answers containing multiple words or having complex semantics, the WUPS metric may not be sufficiently accurate.
4. BLEU
BiLingual Evaluation Understudy (BLEU) examines the degree of overlap between n-grams (n = 1, 2, 3, 4) between ground truth and predicted answers, commonly used for machine translation:
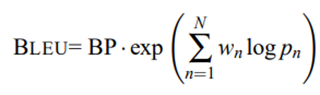
BP is the penalty factor, which prevents the matching degree of n-grams from getting better as the sentence length becomes shorter, so it is not suitable for use in short sentences. In the three datasets of this evaluation, the answers are all single words or phrases, so only unigram matching is performed to reduce the low BLUE score caused by too short sentences.
5. METEOR
Metric for Evaluation of Translation with Explicit ordered (METEOR) is similar to BLEU and is usually used to evaluate machine translation models. It proposes three modules for counting the number of co-occurrences: one is the "exact" module, which is statistics the number of co-occurrences of absolutely identical words in candidate and reference; the second is the "Porter stem module", which is based on the Porter stem algorithm to calculate the co-occurrence of "variants" of words with the same stem in candidate and reference. The number of occurrences, such as "happiness" and "happiness" will be recognized as co-occurrence words in this module; the third is the "WN synonyms" module, which is based on the WordNet dictionary to match synonyms in candidate and reference, and is counted in the number of co-occurrences. Such as "sunshine" and "sunshine".
The algorithm first calculates the precision P and recall R in the case of unigram, and obtains the harmonic mean F:
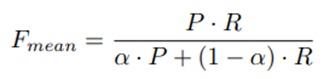
At the same time, METEOR includes word order into the evaluation category and establishes a penalty mechanism based on word order changes. When the word order of candidate is different from reference, appropriate penalties will be applied. Therefore, short sentence answers will also be penalized. The three datasets had lower scores when evaluated using METEOR:
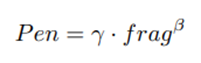
and the final score is:
